1、搭建前准备
- 老规矩,新建hadoop01、hadoop02、hadoop03虚拟机,并且配置好对应的免密登录(http://blog.kdyzm.cn/post/19)以及hosts
- java装好
- flume会自动检测hadoop、hive、hbase等安装情况,能安装的都安装好,只是演示的话,不安装也没关系
2、下载安装包
官网地址:https://flume.apache.org/download.html
历史版本下载地址:http://archive.apache.org/dist/flume/
flume 1.10.1下载地址:http://archive.apache.org/dist/flume/1.10.1/apache-flume-1.10.1-bin.tar.gz
将安装包下载并上传到 hadoop01的/usr/local文件夹,并使用
tar -zxvf apache-flume-1.10.1-bin.tar.gz
命令解压,然后使用命令
ln -s apache-flume-1.10.1-bin flume
建立软链接
3、环境变量配置
vim /etc/profile
export FLUME_HOME=/usr/local/flume
export PATH=$FLUME_HOME/bin:$PATH
4、分发安装文件夹
scp -r /usr/local/apache-flume-1.10.1-bin hadoop02:/usr/local/
scp -r /usr/local/apache-flume-1.10.1-bin hadoop03:/usr/local/
5、Flume写出到日志
需求:监听某个日志文件变更,并通过负载均衡模式打印出来结果,集群架构如下
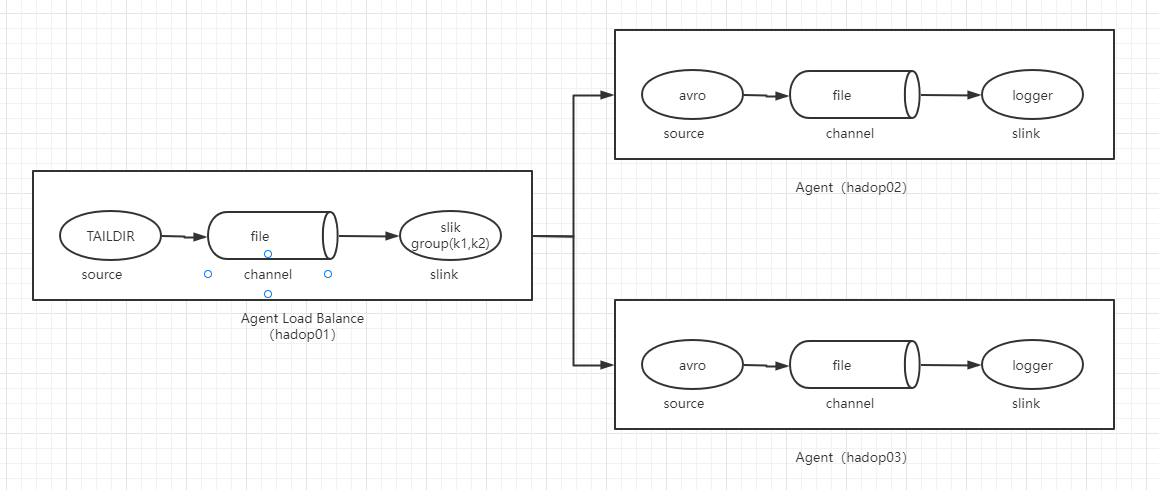
5.1 配置文件
三台机器上除了配置文件不一样,其它环境均相同。
hadoop01在/usr/local/flume/conf目录下新建配置文件taildir-file-selector-avro.properties
#taildir-file-selector-avro.properties
#/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f conf/taildir-file-selector-avro.properties -Dflume.root.logger=INFO,console
#定义source、channel、sink
agent1.sources=taildirSource
agent1.channels=fileChannel
agent1.sinkgroups=g1
agent1.sinks=k1 k2
#定义和配置一个taildir Source
#agent1.sources.taildirSource.type=TAILDIR
#agent1.sources.taildirSource.positionFile=/usr/local/flume/data/taildir_position.json
#agent1.sources.taildirSource.filegroups=fl
#agent1.sources.taildirSource.filegroups.f1=/opt/module/testdir/test.log
agent1.sources.taildirSource.type = TAILDIR
agent1.sources.taildirSource.positionFile = /usr/local/flume/data/taildir_position.json
agent1.sources.taildirSource.filegroups = f1
agent1.sources.taildirSource.filegroups.f1 = /opt/module/testdir/test.log
agent1.sources.taildirSource.channels=fileChannel
#定义和配置一个FileChannel
agent1.channels.fileChannel.type=file
agent1.channels.fileChannel.checkpointDir=/usr/local/flume/data/checkpointDir
agent1.channels.fileChannel.dataDirs=/usr/local/flume/data/dataDirs
#定义和配置一个sink组
agent1.sinkgroups.g1.sinks=k1 k2
#为Sink组定义一个处理器,load_balance表示负载均衡,failover表示故障切换
agent1.sinkgroups.g1.processor.type=load_balance
agent1.sinkgroups.g1.processor.backoff=true
#定义处理器发送聚合节点的方式,round_robin表示轮询发送,random表示随机发送
agent1.sinkgroups.g1.processor.selector=round_robin
agent1.sinkgroups.g1.processor.maxTimeOut=10000
#定义一个sink将数据发送给hadoop02节点
agent1.sinks.k1.type=avro
agent1.sinks.k1.channel=fileChannel
agent1.sinks.k1.batchSize=1
agent1.sinks.k1.hostname=hadoop02
agent1.sinks.k1.port=1234
#定义另一个sink将数据发送给hadoop03节点
agent1.sinks.k2.type=avro
agent1.sinks.k2.channel=fileChannel
agent1.sinks.k2.batchSize=1
agent1.sinks.k2.hostname=hadoop03
agent1.sinks.k2.port=1234
hadoop02、hadoop03在/usr/local/flume/conf新建配置文件avro-file-selector-logger.properties
#avro-file-selector-logger.properties
#/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console
#定义source、channel、Sink的名称
agent1.sources=r1
agent1.channels=c1
agent1.sinks=k1
#定义和配置一个avro sources
agent1.sources.r1.type=avro
agent1.sources.r1.channels=c1
agent1.sources.r1.bind=0.0.0.0
agent1.sources.r1.port=1234
#定义和配置一个fileChannel
agent1.channels.c1.type=file
agent1.channels.c1.checkpointDir=/usr/local/flume/data/checkpointDir
agent1.channels.c1.dataDirs=/usr/local/flume/data/dataDirs
#定义和配置一个logger sink
agent1.sinks.k1.type=logger
agent1.sinks.k1.channel=c1
5.2 启动集群
hadoop02、hadoop03上运行如下命令
/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/avro-file-selector-logger.properties -Dflume.root.logger=INFO,console
启动完成后在hadoop01上运行如下命令
/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/taildir-file-selector-avro.properties -Dflume.root.logger=INFO,console
5.3 集群测试
在hadoop01上执行如下命令
echo "Hello,world" >> /opt/module/testdir/test.log
在hadoop02和hadoop03控制台上查看结果,两台机器的控制台上应该有一个能看到接收到的Events信息

这样即表示程序功能正常。
5.4 负载均衡测试
在控制台多重复几次上一步骤的测试,发现请求都打到同一台机器上了,这让我不禁怀疑负载均衡是不是出了问题。。写了个循环写日志的脚本
for i in {1..1000}
do
echo "hello,workd" >> /opt/module/testdir/test.log
done
然后才发现两台机器上均出现大量日志,这说明负载均衡的配置是好的,那为啥会出现好多请求都出现在统一台机器上的情况呢?我也不知道,就这么着吧。
6、Flume写出到Kafka
整体架构图如下所示
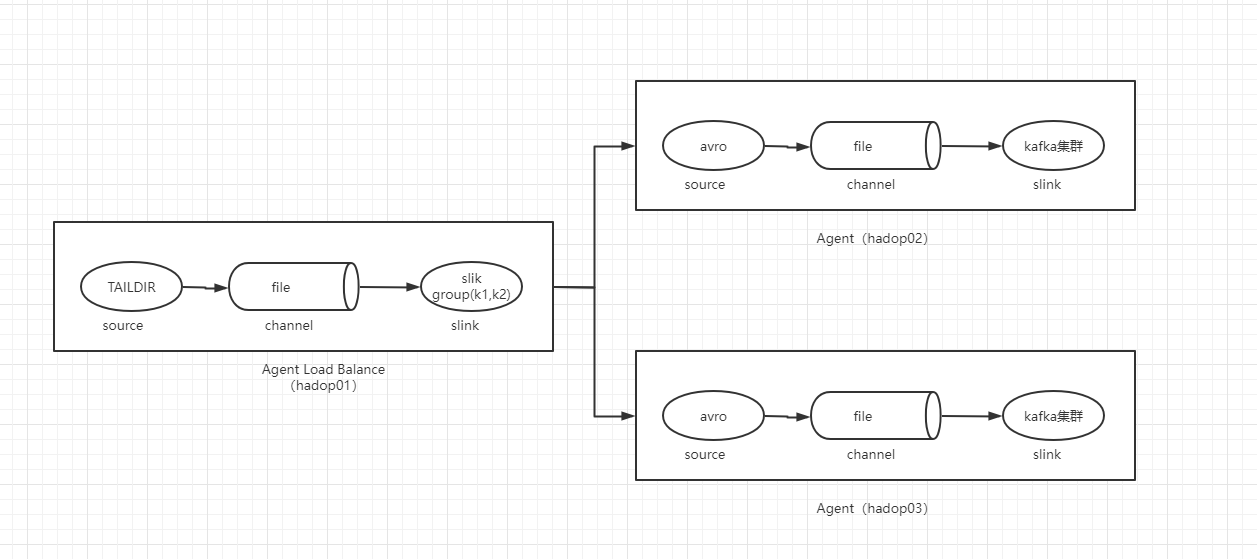
和上一步只是日志打印到控制台不同,现在会将这些日志写出到kafka集群,从架构图上可以看到,第一个Agent Load Balance角色不变(配置不需要变,服务也不需要停止),只是hadoop02和hadoop03需要改变
6.1 创建Topic
需要创建topic:sogoulogs
利用OffsetExploer创建即可
6.2 配置变更
具体来说,在hadoop02和hadoop03上新建配置文件/usr/local/flume/conf/avro-file-selector-kafka.properties
#avro-file-selector-kafka.properties
#/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/avro-file-selector-kafka.properties -Dflume.root.logger=INFO,console
#定义source、channel、Sink的名称
agent1.sources=r1
agent1.channels=c1
agent1.sinks=k1
#定义和配置一个avro sources
agent1.sources.r1.type=avro
agent1.sources.r1.channels=c1
agent1.sources.r1.bind=0.0.0.0
agent1.sources.r1.port=1234
#定义和配置一个fileChannel
agent1.channels.c1.type=file
agent1.channels.c1.checkpointDir=/usr/local/flume/data/checkpointDir
agent1.channels.c1.dataDirs=/usr/local/flume/data/dataDirs
#定义和配置一个logger sink
agent1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.k1.topic=sogoulogs
agent1.sinks.k1.brokerList=hadoop01:9092,hadoop02:9092,hadoop03:9092
agent1.sinks.k1.producer.acks=1
agent1.sinks.k1.channel=c1
然后分别使用命令启动
/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/avro-file-selector-kafka.properties -Dflume.root.logger=INFO,console
最后再hadoop01上执行脚本
for i in {1..1000}
do
echo "hello,workd" >> /opt/module/testdir/test.log
done
执行完毕后查看执行结果
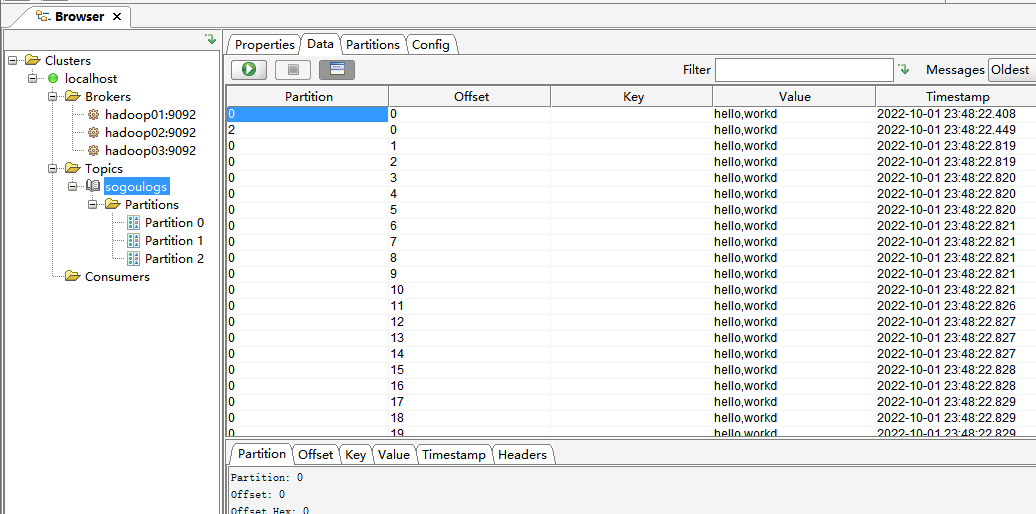
可以看到日志已经正确收集到kafka了
7、Flume写出到hbase
到目前为止(20221002)hbase有两个大版本:hbase1和hbase2,Flume集成两者的方式大部分相同,只有一处不一样,如果弄错了,会集成失败
以下是hbase2集成方案
7.1 创建hbase表
在haddop01机器上,执行如下命令创建hbase表:sogoulogs以及列簇:info
[root@hadoop01 ~]# hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.5.0, r2ecd8bd6d615ca49bfb329b3c0c126c80846d4ab, Tue Aug 23 15:58:57 UTC 2022
Took 0.0018 seconds
hbase:001:0> create 'sogoulogs','info'
hbase:002:0> create 'sogoulogs','info'
Created table sogoulogs
Took 0.6354 seconds
=> Hbase::Table - sogoulogs
7.2 配置文件
hadoop01的负载均衡配置文件无需变动;以下是hadoop02和hadoop03的配置文件变更
新建配置文件:/usr/local/flume/conf/avro-file-selector-hbase2.properties
#avro-file-selector-hbase2.properties
#/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/avro-file-selector-hbase2.properties -Dflume.root.logger=INFO,console
#定义source、channel、Sink的名称
agent1.sources=r1
agent1.channels=c1
agent1.sinks=k1
#定义和配置一个avro sources
agent1.sources.r1.type=avro
agent1.sources.r1.channels=c1
agent1.sources.r1.bind=0.0.0.0
agent1.sources.r1.port=1234
#定义和配置一个fileChannel
agent1.channels.c1.type=file
agent1.channels.c1.checkpointDir=/usr/local/flume/data/checkpointDir
agent1.channels.c1.dataDirs=/usr/local/flume/data/dataDirs
#定义和配置一个Hbase Sink
#agent1.sinks.k1.type=asynchbase
agent1.sinks.k1.type=org.apache.flume.sink.hbase2.HBase2Sink
agent1.sinks.k1.channel=c1
#Hbase表名
agent1.sinks.k1.table=sogoulogs
#agent1.sinks.k1.serializer=org.apache.flume.sink.hbase.kdyzm.DjtAsyncHbaseEventSerializer
agent1.sinks.k1.serializer=org.apache.flume.sink.hbase2.kdyzm.KdyzmHBase2EventSerializer
agent1.sinks.k1.zookeeperQuorum=hadoop01:2181,hadoop02:2181,hadoop03:2181
#用户行为数据每个列的名称
agent1.sinks.k1.serializer.payloadColumn=datetime,userid,searchname,retorder,cliorder,cliurl
agent1.sinks.k1.znodeParent=/hbase
#Hbase列簇名称
agent1.sinks.k1.columnFamily=info
不要着急启动,还需要些其它修改,上述配置中的agent1.sinks.k1.serializer配置项值为org.apache.flume.sink.hbase2.kdyzm.KdyzmHBase2EventSerializer,这个需要修改flume-ng-hbase2-sink源代码来实现
7.3 修改flume-ng-hbase2-sink源码
原生的sink组件不能按照表格式插入数据(它会将payload中的列配置的英文逗号分割的字符串整个当做列簇的一列),所以这里需要修改相关代码,这样就可以适应我们自定义的一些规则,比如日志格式是使用英文逗号分割的、RowKey的生成规则、hbase表的列插入等
去flume官网下载1.10.1版本的源码
解压后可以看到有很多项目
首先打开flume-ng-sinks目录,里面是一堆集成第三方的插件,hbase也在里面
可以看到,这里有两个版本,一个是hbase1,一个是hbase2两个项目单独拿出来修改,这里修改hbase2的
7.3.1 SimpleRowKeyGenerator
在该类中新增方法
/**
* 自定义RowKey生成策略
*
* @param userId
* @param datetime
* @return
*/
public static byte[] getDjtRowKey(String userId, String datetime) {
return (userId + datetime + System.currentTimeMillis()).getBytes(StandardCharsets.UTF_8);
}
7.3.2 KdyzmHBase2EventSerializer
新建类:org.apache.flume.sink.hbase2.kdyzm.KdyzmHBase2EventSerializer
package org.apache.flume.sink.hbase2.kdyzm;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.base.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.FlumeException;
import org.apache.flume.conf.ComponentConfiguration;
import org.apache.flume.sink.hbase2.HBase2EventSerializer;
import org.apache.flume.sink.hbase2.SimpleHBase2EventSerializer;
import org.apache.flume.sink.hbase2.SimpleRowKeyGenerator;
import org.apache.flume.sink.hbase2.utils.JsonUtils;
import org.apache.hadoop.hbase.client.Increment;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Row;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.nio.charset.StandardCharsets;
import java.util.LinkedList;
import java.util.List;
/**
* @author kdyzm
* @date 2022/10/2
*/
public class KdyzmHBase2EventSerializer implements HBase2EventSerializer {
private String rowPrefix;
private byte[] incrementRow;
private byte[] cf;
private byte[] plCol;
private byte[] incCol;
private SimpleHBase2EventSerializer.KeyType keyType;
private byte[] payload;
private Logger logger = LoggerFactory.getLogger(KdyzmHBase2EventSerializer.class);
@Override
public void configure(Context context) {
rowPrefix = context.getString("rowPrefix", "default");
incrementRow =
context.getString("incrementRow", "incRow").getBytes(Charsets.UTF_8);
String suffix = context.getString("suffix", "uuid");
String payloadColumn = context.getString("payloadColumn", "pCol");
String incColumn = context.getString("incrementColumn", "iCol");
if (payloadColumn != null && !payloadColumn.isEmpty()) {
switch (suffix) {
case "timestamp":
keyType = SimpleHBase2EventSerializer.KeyType.TS;
break;
case "random":
keyType = SimpleHBase2EventSerializer.KeyType.RANDOM;
break;
case "nano":
keyType = SimpleHBase2EventSerializer.KeyType.TSNANO;
break;
default:
keyType = SimpleHBase2EventSerializer.KeyType.UUID;
break;
}
plCol = payloadColumn.getBytes(Charsets.UTF_8);
}
if (incColumn != null && !incColumn.isEmpty()) {
incCol = incColumn.getBytes(Charsets.UTF_8);
}
}
@Override
public void configure(ComponentConfiguration conf) {
// TODO Auto-generated method stub
}
@Override
public void initialize(Event event, byte[] cf) {
this.payload = event.getBody();
this.cf = cf;
}
@Override
public List<Row> getActions() throws FlumeException {
List<Row> actions = new LinkedList<>();
if (plCol != null) {
byte[] rowKey;
try {
//解析列字段
String[] columns = new String(this.plCol).split(",");
logger.info("columns={},lenth={}", JsonUtils.toString(columns), columns.length);
//解析每列对应的值
String[] values = new String(this.payload).split(",");
logger.info("values={},lenth={}", JsonUtils.toString(values), values.length);
//判断数据与字段长度是否一致
if (columns.length != values.length) {
return actions;
}
//时间
String datetime = values[0];
//用户id
String userId = values[1];
//自定义生成RowKey
rowKey = SimpleRowKeyGenerator.getDjtRowKey(userId, datetime);
Put put = new Put(rowKey);
for (int i = 0; i < columns.length; i++) {
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(StandardCharsets.UTF_8);
put.addColumn(cf, colColumn, colValue);
actions.add(put);
}
} catch (Exception e) {
logger.error("", e);
// throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
@Override
public List<Increment> getIncrements() {
List<Increment> incs = new LinkedList<>();
if (incCol != null) {
Increment inc = new Increment(incrementRow);
inc.addColumn(cf, incCol, 1);
incs.add(inc);
}
return incs;
}
@Override
public void close() {
}
}
7.3.3 打包
使用命令
mvn clean package -DskipTests
打包,将打包完成的flume-ng-hbase2-sink-1.10.1.jar上传到hadoop02和hadoop03的/usr/local/flume/lib目录,替换掉之前的jar包
7.4 运行
在hadoop02、hadoop03上运行命令
/usr/local/flume/bin/flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/avro-file-selector-hbase2.properties -Dflume.root.logger=INFO,console
启动项目
7.5 测试
在hadoop01上运行命令
echo '00:00:01,19400215479348182,[天津工业大学\],1,65,www.baidu.com/' >> /opt/module/testdir/test.log
检查下hadoop02和hadoop03的控制台没问题之后,在habase端查看落库情况
hbase:044:0> scan 'sogoulogs'
ROW COLUMN+CELL
1940021547934818200:00:011664791412121 column=info:cliorder, timestamp=2022-10-03T18:03:32.542, value=65
1940021547934818200:00:011664791412121 column=info:cliurl, timestamp=2022-10-03T18:03:32.542, value=www.baidu.com/
1940021547934818200:00:011664791412121 column=info:datetime, timestamp=2022-10-03T18:03:32.542, value=00:00:01
1940021547934818200:00:011664791412121 column=info:retorder, timestamp=2022-10-03T18:03:32.542, value=1
1940021547934818200:00:011664791412121 column=info:searchname, timestamp=2022-10-03T18:03:32.542, value=xE5\xA4\xA9\xE6\xB4\xA5\xE5\xB7\xA5\xE4\xB8\x9A\xE5\xA4\xA7\xE5\xAD\xA6\x5C]
1940021547934818200:00:011664791412121 column=info:userid, timestamp=2022-10-03T18:03:32.542, value=19400215479348182
1 row(s)
能看到数据就表示没问题了
7.6 hbase1和hbase2的集成异同
现在网上很多Flume和hbase集成的方案都是和hbase1的集成方案,也要修改源代码,但是要修改项目:flume-ng-hbase-sink的源代码,修改方式和flume-ng-hbase2-sink项目的修改方式大同小异,配置方式上,和hbase1的集成方案,配置文件如下
......
agent1.sinks.k1.type=asynchbase
......
agent1.sinks.k1.serializer=org.apache.flume.sink.hbase.kdyzm.DjtAsyncHbaseEventSerializer
......
其中DjtAsyncHbaseEventSerializer是自定义的序列化类,相关源代码的修改在flume-ng-hbase-sink项目,替换的是flume-ng-hbase-sink-1.10.1.jar jar包
而在和hbase2的集成方案中,则是这样子
......
agent1.sinks.k1.type=org.apache.flume.sink.hbase2.HBase2Sink
......
agent1.sinks.k1.serializer=org.apache.flume.sink.hbase2.kdyzm.KdyzmHBase2EventSerializer
......
KdyzmHBase2EventSerializer是自定义的序列化类,相关源代码的修改在flume-ng-hbase2-sink项目,替换的是flume-ng-hbase2-sink-1.10.1.jar jar包
如果安装的hbase版本是2.0版本以上,但是在flume配置文件中写配置却是
agent1.sinks.k1.type=asynchbase
则会报错
hbase major version number must be less than 2 for hbase-sink
7.7 相关源代码
和hbase1集成源码项目:https://gitee.com/kdyzm/flume-ng-hbase-sink
和hbase2集成源码项目:https://gitee.com/kdyzm/flume-ng-hbase2-sink
出现的问题
启动报错:Could not find or load main class org.apache.flume.tools.GetJavaProperty
错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty或者Error: Could not find or load main class org.apache.flume.tools.GetJavaProperty
一般来说是由于装了HBASE等工具的原因
[root@master conf]# flume-ng version
Error: Could not find or load main class org.apache.flume.tools.GetJavaProperty
解决方法:
将Hbase的配置文件hbas-env.sh修改为:
1、将hbase的hbase.env.sh的一行配置注释掉
# Extra Java CLASSPATH elements. Optional.
#export HBASE_CLASSPATH=/home/hadoop/hbase/conf
2、或者将HBASE_CLASSPATH改为JAVA_CLASSPATH,配置如下
# Extra Java CLASSPATH elements. Optional.
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
启动报错:hbase major version number must be less than 2 for hbase-sink
配置文件里写的sink类型为asynchbase,但是hbase版本已经是2.0以上,需要类型为org.apache.flume.sink.hbase2.HBase2Sink
参考文档
Flume-Hbase-Sink针对不同版本flume与HBase的适配研究与经验总结
Hadoop大数据开发Flume和HBase、Kafka集成
注意:本文归作者所有,未经作者允许,不得转载