JMH是Java Micro Benchmark Harness的简写,是专门用于代码微基准测试的工具集(toolkit)。JMH是由实现Java虚拟机的团队开发的,因此他们非常清楚开发者所编写的代码在虚拟机中将会如何执行。
由于现代JVM已经变得越来越智能,在Java文件的编译阶段、类的加载阶段,以及运行阶段都可能进行了不同程度的优化,因此开发者编写的代码在运行中未必会像自己所预期的那样具有相同的性能体现,JVM的开发者为了让普通开发者能够了解自己所编写的代码运行的情况,JMH便因此而生。
JMH的官网地址:http://openjdk.java.net/projects/code-tools/jmh/
JMH的Github地址:https://github.com/openjdk/jmh
要想使用JMH,必须先引入相应的Maven依赖
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.37</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.37</version>
<scope>provided</scope>
</dependency>
注意,各版本可能存在较大差异,并非完全兼容,所以同样的微基准测试代码在不同的版本下可能运行结果不一样,甚至会报错。
一、JMH简单案例
为了快速熟悉JMH的用法,先看一个简单的案例:字符串加法和StringBuilder的append方法效率比较
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/8
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Thread)
@Fork(1)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class JMHExample00 {
private final static String DATA = "DUMMY DATA";
private String s;
private StringBuilder sb;
@Setup(Level.Iteration)
public void setUp() {
s = "";
sb = new StringBuilder();
}
@Benchmark
public String stringAdd() {
s = s + DATA;
return s;
}
@Benchmark
public StringBuilder stringBuilderAdd() {
sb.append(DATA);
return sb;
}
public static void main(String[] args) throws RunnerException {
final Options opts = new
OptionsBuilder()
.include(JMHExample00.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
运行结果如下:
# JMH version: 1.37
# VM version: JDK 1.8.0_333, Java HotSpot(TM) 64-Bit Server VM, 25.333-b02
# VM invoker: D:\ProgramFiles\Java\jdk8\jdk1.8.0_333\jre\bin\java.exe
# VM options: -javaagent:D:\ProgramFiles\JetBrains\IntelliJ IDEA 2020.3.4\lib\idea_rt.jar=13866:D:\ProgramFiles\JetBrains\IntelliJ IDEA 2020.3.4\bin -Dfile.encoding=UTF-8
# Blackhole mode: full + dont-inline hint (auto-detected, use -Djmh.blackhole.autoDetect=false to disable)
# Warmup: 5 iterations, 1 s each
# Measurement: 5 iterations, 1 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: cn.kdyzm.thread.demo.chapter01.jmh.JMHExample00.stringAdd
# Run progress: 0.00% complete, ETA 00:00:20
# Fork: 1 of 1
# Warmup Iteration 1: 34.429 us/op
# Warmup Iteration 2: 30.769 us/op
# Warmup Iteration 3: 54.728 us/op
# Warmup Iteration 4: 55.328 us/op
# Warmup Iteration 5: 35.313 us/op
Iteration 1: 31.829 us/op
Iteration 2: 28.702 us/op
Iteration 3: 30.219 us/op
Iteration 4: 31.238 us/op
Iteration 5: 27.626 us/op
Result "cn.kdyzm.thread.demo.chapter01.jmh.JMHExample00.stringAdd":
29.923 ±(99.9%) 6.730 us/op [Average]
(min, avg, max) = (27.626, 29.923, 31.829), stdev = 1.748
CI (99.9%): [23.192, 36.653] (assumes normal distribution)
# JMH version: 1.37
# VM version: JDK 1.8.0_333, Java HotSpot(TM) 64-Bit Server VM, 25.333-b02
# VM invoker: D:\ProgramFiles\Java\jdk8\jdk1.8.0_333\jre\bin\java.exe
# VM options: -javaagent:D:\ProgramFiles\JetBrains\IntelliJ IDEA 2020.3.4\lib\idea_rt.jar=13866:D:\ProgramFiles\JetBrains\IntelliJ IDEA 2020.3.4\bin -Dfile.encoding=UTF-8
# Blackhole mode: full + dont-inline hint (auto-detected, use -Djmh.blackhole.autoDetect=false to disable)
# Warmup: 5 iterations, 1 s each
# Measurement: 5 iterations, 1 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: cn.kdyzm.thread.demo.chapter01.jmh.JMHExample00.stringBuilderAdd
# Run progress: 50.00% complete, ETA 00:00:11
# Fork: 1 of 1
# Warmup Iteration 1: 0.027 us/op
# Warmup Iteration 2: 0.029 us/op
# Warmup Iteration 3: 0.026 us/op
# Warmup Iteration 4: 0.028 us/op
# Warmup Iteration 5: 0.026 us/op
Iteration 1: 0.025 us/op
Iteration 2: 0.024 us/op
Iteration 3: 0.025 us/op
Iteration 4: 0.042 us/op
Iteration 5: 0.023 us/op
Result "cn.kdyzm.thread.demo.chapter01.jmh.JMHExample00.stringBuilderAdd":
0.028 ±(99.9%) 0.030 us/op [Average]
(min, avg, max) = (0.023, 0.028, 0.042), stdev = 0.008
CI (99.9%): [≈ 0, 0.058] (assumes normal distribution)
# Run complete. Total time: 00:00:26
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
Benchmark Mode Cnt Score Error Units
JMHExample00.stringAdd avgt 5 29.923 ± 6.730 us/op
JMHExample00.stringBuilderAdd avgt 5 0.028 ± 0.030 us/op
Process finished with exit code 0
可以看到运行结果非常长,暂时看最终的结果就行:
Benchmark Mode Cnt Score Error Units
JMHExample00.stringAdd avgt 5 29.923 ± 6.730 us/op
JMHExample00.stringBuilderAdd avgt 5 0.028 ± 0.030 us/op
这个意思表示stringAdd方法和stringBuilderAdd方法分别进行了5次基准测试,方法调用的平均耗时为stringAdd方法29微妙,stringBuilderAdd方法0.028us,由此可见string字符串累加效率比较低,大量字符串连接操作应当使用StringBuilder。
二、JMH核心配置
JMH的配置几乎都是基于注解的配置,所以搞清楚注解怎么用,就基本搞定了JMH的使用。
1、@BenchmarkMode注解
JMH使用@BenchmarkMode这个注解来声明使用哪一种模式来运行,可以看到它是个数组类型,所以可以同时指定多个类型从而让它输出多维度的统计数据。
@Inherited
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface BenchmarkMode {
/**
* @return Which benchmark modes to use.
* @see Mode
*/
Mode[] value();
}
Mode的类型有如下几种
| Mode类型 | 释义 |
|---|---|
| Throughput | Throughput(方法吞吐量)模式,与AverageTime相反,它的输出信息表明了在单位时间内可以对该方法调用多少次。 |
| AverageTime | AverageTime(平均响应时间)模式,它主要用于输出基准测试方法每调用一次所耗费的时间,也就是elapsed time/operation |
| SampleTime | SampleTime(时间采样)的方式是指采用一种抽样的方式来统计基准测试方法的性能结果,与我们常见的Histogram图(直方图)几乎是一样的,它会收集所有的性能数据,并且将其分布在不同的区间中。 |
| SingleShotTime | SingleShotTime主要可用来进行冷测试,不论是Warmup还是Measurement,在每一个批次中基准测试方法只会被执行一次,一般情况下,我们会将Warmup的批次设置为0。 |
| All | 上述所有模式的集合 |
2、@Warmup和@Measurement注解
Warmup可直译为“预热”的意思,在JMH中,Warmup所做的就是在基准测试代码正式度量之前,先对其进行预热,使得代码的执行是经历过了类的早期优化、JVM运行期编译、JIT优化之后的最终状态,从而能够获得代码真实的性能数据。Measurement则是真正的度量操作,在每一轮的度量中,所有的度量数据会被纳入统计之中(预热数据不会纳入统计之中)。
Warmup注解和Measurement注解是JMH中最重要的两个注解,注解定义如下
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface Warmup {
int BLANK_ITERATIONS = -1;
int BLANK_TIME = -1;
int BLANK_BATCHSIZE = -1;
/** @return Number of warmup iterations */
int iterations() default BLANK_ITERATIONS;
/** @return Time for each warmup iteration */
int time() default BLANK_TIME;
/** @return Time unit for warmup iteration duration */
TimeUnit timeUnit() default TimeUnit.SECONDS;
/** @return batch size: number of benchmark method calls per operation */
int batchSize() default BLANK_BATCHSIZE;
}
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Measurement {
int BLANK_ITERATIONS = -1;
int BLANK_TIME = -1;
int BLANK_BATCHSIZE = -1;
/** @return Number of measurement iterations */
int iterations() default BLANK_ITERATIONS;
/** @return Time of each measurement iteration */
int time() default BLANK_TIME;
/** @return Time unit for measurement iteration duration */
TimeUnit timeUnit() default TimeUnit.SECONDS;
/** @return Batch size: number of benchmark method calls per operation */
int batchSize() default BLANK_BATCHSIZE;
}
可以看到,两个注解的定义一模一样,都有四个属性:
| 属性名称 | 释义 |
|---|---|
| iterations | 执行的批次数量,比如5,那就是执行5个批次,每个批次执行的微基准方法次数取决于time参数和当前处理器性能高低 |
| time | 每批次执行的微基准方法的时间,相当于在一定时间内循环调用微基准方法 |
| timeUnit | 时间单位 |
| batchSize | 相当于每次调用微基准方法的时候给它加一个for循环,batchSize就是循环次数 |
这几个参数很具有迷惑性,有些人搞不清楚这四个参数之间如何搭配使用,举个例子:我要想让基准测试执行5个批次,每批次执行最长不超过1秒钟,每批次中每次调用基准方法,都要批量执行100次,那注解就要这样写:
@Measurement(iterations=5,time=1,timeUnit=TimeUnit.SECONDS,batchSize=100)
需要注意的是,batchSize这个参数会直接影响所有类型的测试结果,比如平均执行时间AverageTime,对于以下微基准测试
@Benchmark
public String stringAdd() {
s = s + DATA;
return s;
}
@Benchmark
public StringBuilder stringBuilderAdd() {
sb.append(DATA);
return sb;
}
当不设置batchSize的时候
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
运行结果

当设置了batchSize的值为10的时候
@Measurement(iterations = 5, time = 1, batchSize = 10, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, batchSize = 10, timeUnit = TimeUnit.SECONDS)
运行结果

可以看到执行效率相差了10倍,正好和batchSize的设置大小相对应,也就是说,统计的op操作是batchSize大小的循环打包的操作,被JMH视为一个整体操作了。用微基准测试应当尽量不要在测试方法中使用for循环,防止JVM在运行时做的循环展开优化影响测试结果。而使用batchSize可以避免这种影响。
3、@Threads注解
@Threads 注解用于指定每个基准测试方法执行时所使用的线程数量。
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Threads {
/**
* The magic value for MAX threads.
* This means Runtime.getRuntime().availableProcessors() threads.
*/
int MAX = -1;
/**
* @return Number of threads; use Threads.MAX to run with all available threads.
*/
int value();
}
该注解只有一个属性value,用于指定线程数量。比如@Threads(5)表示每个基准测试方法执行时使用了5个线程并行处理批次任务。需要注意的是@Warmup以及@Measurement注解注解的iterations属性大小不会影响线程的创建数量,线程创建数量仅受限于Threads注解的value属性。
4、@State注解
State注解用于描述微基准测试方法的状态
@Inherited
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface State {
/**
* State scope.
* @return state scope
* @see Scope
*/
Scope value();
}
它仅有一个Scope类型的参数,用于描述该状态的共享范围
public enum Scope {
Benchmark,
Group,
Thread,
}
Scope共有三种类型
| Scope类型 | 释义 |
|---|---|
| Thread | Thread独享的State。所谓线程独享的State是指,每一个运行基准测试方法的线程都会持有一个独立的对象实例,该实例既可能是作为基准测试方法参数传入的,也可能是运行基准方法所在的宿主class,将State设置为Scope.Thread一般主要是针对非线程安全的类。 通俗的来讲,创建的实例数量和@Threads注解的value属性相同。 |
| Benchmark | Thread共享的State。有时候,我们需要测试在多线程的情况下某个类被不同线程操作时的性能,比如,多线程访问某个共享数据时,我们需要让多个线程使用同一个实例才可以。因此JMH提供了多线程共享的一种状态Scope.Benchmark。 换句通俗的话来讲,有几个微基准方法,就会创建几个实例,微基准方法的Warmup以及Measurement都用这一个实例。使用该模式,需要注意共享变量是否会溢出的情况,如果有累加操作,需要适当调小iterations属性。 |
| Group | 线程组共享的State。它允许多线程共享单个实例,并且允许一个以上的基准测试方法并发并行地运行。 |
Thread模式和Benchmark模式比较好理解,这里说下Group模式,直接看案例:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Group)
@Fork(1)
@Measurement(iterations = 1, time = 1, batchSize = 10, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 2, time = 1, batchSize = 10, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class JMHThreadGroup {
public JMHThreadGroup() {
System.out.println("create instance");
}
@Benchmark
@Group("test")
@GroupThreads(3)
public void read(Blackhole blackhole) {
blackhole.consume("read");
}
@Benchmark
@Group("test")
@GroupThreads(3)
public void write(Blackhole blackhole) {
blackhole.consume("write");
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JMHThreadGroup.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
输出结果:
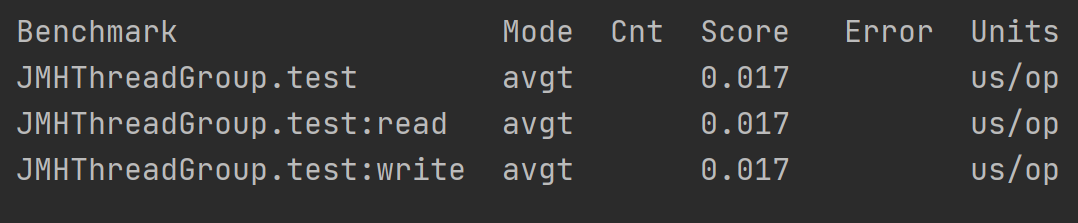
共用一个线程组的情况下,当前实例只创建了一个,输出结果中展示线程组中所有线程的操作平均时间以及每个微基准测试方法的读写线程平均操作时间。
5、@Fork注解
@Fork注解的作用是“启动几个JVM虚拟机测试”,常用的写法就一个
@Fork(1)
表示启动一个JVM虚拟机测试,这样就按照其它注解的作用执行一次,如果大于1,则微基准测试会在多个JVM实例中重复执行。一般情况下,使用@Fork(1)即可。
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Fork {
int BLANK_FORKS = -1;
String BLANK_ARGS = "blank_blank_blank_2014";
/** @return number of times harness should fork, zero means "no fork" */
int value() default BLANK_FORKS;
/** @return number of times harness should fork and ignore the results */
int warmups() default BLANK_FORKS;
/** @return JVM executable to run with */
String jvm() default BLANK_ARGS;
/** @return JVM arguments to replace in the command line */
String[] jvmArgs() default { BLANK_ARGS };
/** @return JVM arguments to prepend in the command line */
String[] jvmArgsPrepend() default { BLANK_ARGS };
/** @return JVM arguments to append in the command line */
String[] jvmArgsAppend() default { BLANK_ARGS };
}
该注解还有其他参数,用于指定虚拟机启动参数,比如可以使用jvmArgsAppend参数指定堆大小
@Fork(value = 1,jvmArgsAppend = "-Xmx=2g")
6、@OutputTimeUnit
@Inherited
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface OutputTimeUnit {
/**
* @return Time unit to use.
*/
TimeUnit value();
}
该注解比较简单,用于指定输出显示的时间单位
基本用法:
@OutputTimeUnit(TimeUnit.MICROSECONDS)
在这里TimeUnit各种时间单位如下
| TimeUnit | 释义 |
|---|---|
| NANOSECONDS | 纳秒,1 秒=10,0000,0000 纳秒(十亿) |
| MICROSECONDS | 微秒,1秒=100,0000 微秒(100万),1微秒=1000 纳秒 |
| MILLISECONDS | 毫秒,1 秒=1000 毫秒,1 毫秒=1000 微秒 |
| SECONDS | 秒 |
| MINUTES | 分钟 |
7、@Timeout注解
该注解用于设置一个批次执行的超时时间,使用方式如下
@Timeout(time = 10,timeUnit = TimeUnit.SECONDS)
有些时候,由于堵塞等情况JMH运行可能会“卡住”,这时候使用该注解在10秒钟之后会自动结束当前批次。
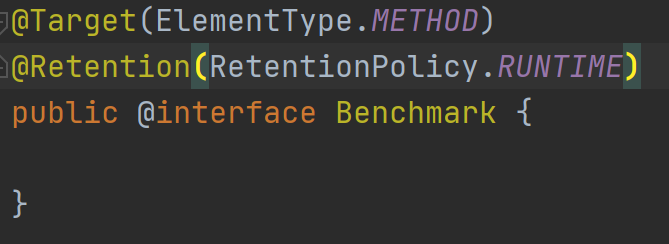
8、@Benchmark注解
该注解标记在方法上,用于标记微基准测试方法,它是个标记注解,本身没有任何属性
9、@Param注解
@Param 注解用于定义基准测试方法的参数,允许在运行基准测试时以不同的参数值多次运行同一个基准测试方法,从而评估代码在不同参数设置下的性能表现。
直接看案例:比对四种map在并发情况下的性能表现。
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Benchmark)
@Fork(value = 1)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Threads(5)
public class JMHParamsTest {
@Param({"hashTable", "concurrentHashMap", "synchronizedMap", "concurrentSkipListMap"})
private String type;
private Map<Long, Long> map;
@Setup
public void setUp() {
switch (type) {
case "hashTable":
this.map = new Hashtable<>();
break;
case "concurrentHashMap":
this.map = new ConcurrentHashMap<>();
break;
case "synchronizedMap":
this.map = Collections.synchronizedMap(new HashMap<>());
break;
case "concurrentSkipListMap":
this.map = new ConcurrentSkipListMap<>();
break;
default:
throw new IllegalArgumentException("参数错误");
}
}
@Benchmark
public void putTest() {
this.map.put(System.nanoTime(), System.currentTimeMillis());
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JMHParamsTest.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
输出结果:

JMH会遍历参数依次调用方法分批次做微基准测试。
10、@Setup和@TearDown注解
JMH提供了两个注解@Setup和@TearDown用于在基准测试方法执行前后执行相关的操作,其中@Setup会在每一个基准测试方法执行前被调用,通常用于资源的初始化,@TearDown则会在基准测试方法被执行之后被调用,通常可用于资源的回收清理工作。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Setup {
/**
* @return Level of this method.
* @see Level
*/
Level value() default Level.Trial;
}
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TearDown {
/**
* @return At which level to run this fixture.
* @see Level
*/
Level value() default Level.Trial;
}
两个注解都加在方法上,而且其属性定义也都一样,都只有一个Level类型的属性,表示作用触发时机
| Level级别 | 释义 |
|---|---|
| Trial | Setup和TearDown默认的配置,该套件方法会在每一个基准测试方法的所有批次执行的前后被执 |
| Iteration | 由于我们可以设置Warmup和Measurement,因此每一个基准测试方法都会被执行若干个批次,如果想要在每一个基准测试批次执行的前后调用套件方法,则可以将Level设置为Iteration。 |
| Invocation | 将Level设置为Invocation意味着在每一个批次的度量过程中,每一次对基准方法的调用前后都会执行套件方法。 |
一般来说,使用默认的Trial即可满足绝大多数场景需求。
三、编写正确的微基准测试用例
现代的Java虚拟机已经发展得越来越智能了,它在类的早期编译阶段、加载阶段以及后期的运行时都可以为我们的代码进行相关的优化,比如Dead Code的擦除、常量的折叠,还有循环的打开,甚至是进程Profiler的优化,等等,因此要掌握如何编写良好的微基准测试方法,首先我们要知道什么样的基准测试代码是有问题的。
1、避免Dead Code Elimination
所谓Dead Code Elimination是指JVM为我们擦去了一些上下文无关,甚至经过计算之后确定压根不会用到的代码,比如下面这样的代码片段。
public void test(){
int x=10;
int y=10;
int z=x+y;
}
这段代码犯了一个错误:定义了局部变量z,计算完成后没有返回结果,这会导致JVM可能会将test()方法当作一个空的方法来看待,也就是说会擦除对x、y的定义,以及计算z的相关代码。看下面的代码
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Thread)
@Fork(1)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class JMHDeadCodeTest {
@Benchmark
public void test1() {
}
@Benchmark
public void test2() {
double log = Math.log(Math.PI);
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JMHDeadCodeTest.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
test1和test2方法一个是空方法,一个是做了运算的方法,两个方法做微基准测试肯定结果不应该一样,以下是运行结果

然而两个方法运行效率是相同的,这正是因为JVM对Dead Code做了代码擦除,为了解决这个问题,可以在test2方法上加上下面的代码以避免JVM优化
@CompilerControl(CompilerControl.Mode.EXCLUDE)
再次运行代码

可以看到禁止JVM优化之后,test2方法得到了正常的执行。
通过这个例子我们可以发现,若想要编写性能良好的微基准测试方法,则不要让方法存在Dead Code,最好每一个基准测试方法都有返回值。
但是如果不想写返回值,又该怎么办呢?答案就是: 使用Blackhole
Blackhole直译过来就是“黑洞”,可以吞噬一切的东西,使用它可以不用写返回值代码Dead Code还不会被JVM优化擦除,使用示例如下
@Benchmark
public void write(Blackhole blackhole) {
blackhole.consume("write");
}
2、避免常量折叠
常量折叠(Constant Folding)是Java编译器早期的一种优化——编译优化。在javac对源文件进行编译的过程中,通过词法分析可以发现某些常量是可以被折叠的,也就是可以直接将计算结果存放到声明中,而不需要在执行阶段再次进行运算。比如:
private final int x = 10;
private final int y = x*20;
在编译阶段,y的值将被直接赋予200,这就是所谓的常量折叠。看下面的案例:定义了两个常量x、y,两个变量a、b,它们的数值对应是相同的;分别计算直接返回的结果、常量计算的结果、变量计算的结果
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Thread)
@Fork(1)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class JMHConstantsTest {
private final double x = 3.1415926;
private final double y = 3.1415927;
private double a = 3.1415926;
private double b = 3.1415927;
/**
* 基准测试方法
*/
@Benchmark
public double baseTest() {
return 1.3104065089406907;
}
/**
* final常量算术
*/
@Benchmark
public double test1() {
return Math.log(x) * Math.log(y);
}
/**
* 非final变量算术
*/
@Benchmark
public double test2() {
return Math.log(a) * Math.log(b);
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JMHConstantsTest.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
运行结果如下

可以看到常量计算的微基准测试方法和直接返回计算结果的微基准测试方法两者的效率是相同的,而虽然是相同的数值,非常量测试方法test2则明显耗时更长。
为了解决这个问题,同样可以使用加上@CompilerControl(CompilerControl.Mode.EXCLUDE)注解防止编译优化的手段,运行结果如下

可以看到常量计算的效率比变量计算的效率更低一些。。说明变量计算方法还有其他JVM优化措施,给两个方法都加上@CompilerControl(CompilerControl.Mode.EXCLUDE)
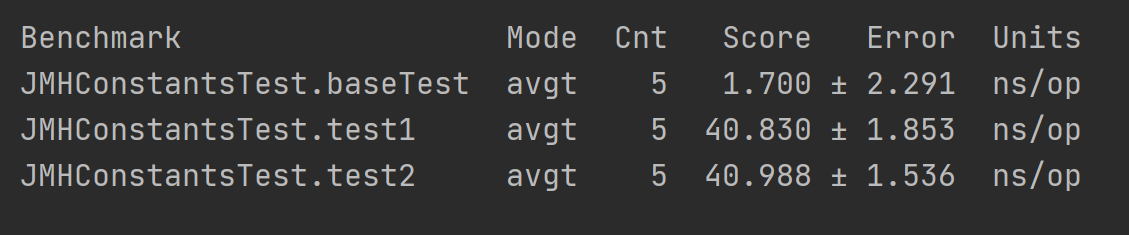
可以看到,终于两个方法的效率一样了。
3、避免循环展开
循环展开(Loop Unrolling)是一种优化技术,通常用于提高计算机程序中循环结构的性能。该技术的核心思想是减少循环迭代的开销,通过在编译器或汇编器级别将循环体内的代码复制多次来减少循环迭代次数。
举个例子:
int[] array = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
// 循环求和
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
System.out.println("Sum: " + sum);
这段计算数组元素累加和的代码有可能被优化成以下样子
// 使用循环展开的优化
for (int i = 0; i < array.length; i += 2) {
sum += array[i];
sum += array[i + 1];
}
下面看看循环展开优化的案例:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1)
@Measurement(iterations = 10, time = 1)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(1)
public class JMHExample16 {
private int x = 1;
private int y = 2;
@Benchmark
public int measure() {
return (x + y);
}
private int loopCompute(int times) {
int result = 0;
for (int i = 0; i < times; i++) {
result += (x + y);
}
return result;
}
@OperationsPerInvocation
@Benchmark
public int measureLoop_1() {
return loopCompute(1);
}
@OperationsPerInvocation(10)
@Benchmark
public int measureLoop_10() {
return loopCompute(10);
}
@OperationsPerInvocation(100)
@Benchmark
public int measureLoop_100() {
return loopCompute(100);
}
@OperationsPerInvocation(1000)
@Benchmark
public int measureLoop_1000() {
return loopCompute(1000);
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JMHExample16.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
以上案例分别对两个变量进行了单独的加法计算、循环1次、10次、100次、1000次累加和运算,最后统计在各种情况下单次运算的执行效率。运行结果如下
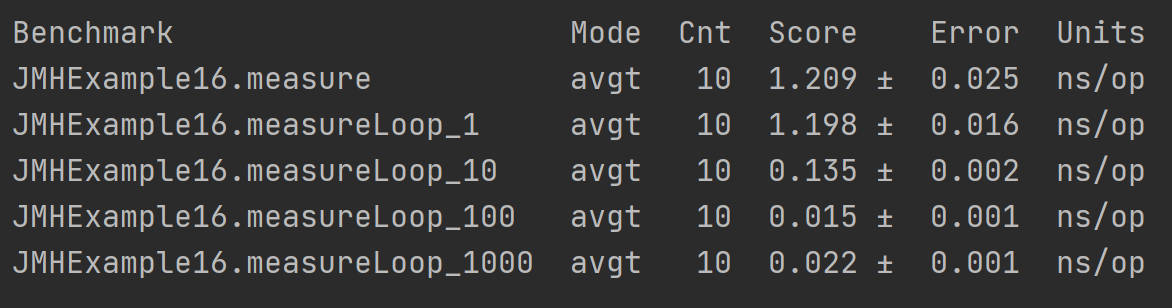
可以看到,随着循环次数增加,单次计算的效率甚至有越来越高的趋势。
这里说下@OperationsPerInvocation注解,这个注解是用于标记微基准测试方法里面有多少个循环的,使用了这个注解标记的方法,最终统计单次执行时间,会将循环内的单次操作视为一个op。这和@Measurement注解的batchSize正好相反。
总之,一般情况下不要在微基准测试方法中写循环,避免循环展开带来的影响
四、JMH的Profile
JMH提供了一些非常有用的Profiler可以帮助我们更加深入地了解基准测试,甚至还能帮助开发者分析所编写的代码,JMH目前提供了如下所示的一些Profiler以供使用。
常见的Profile如下图所示
| Profile名字 | 释义 |
|---|---|
| StackProfiler | StackProfiler不仅可以输出线程堆栈的信息,还能统计程序在执行的过程中线程状态的数据,比如RUNNING状态、WAIT状态所占用的百分比等 |
| GCProfiler | GcProfiler可用于分析出在测试方法中垃圾回收器在JVM每个内存空间上所花费的时间 |
| ClassloaderProfiler | ClassLoaderProfiler可以帮助我们看到在基准方法的执行过程中有多少类被加载和卸载 |
| CompilerProfiler | CompilerProfiler将会告诉你在代码的执行过程中JIT编译器所花费的优化时间 |
使用方式:
在启动类中使用addProfile方法,入参则是一个class对象
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.addProfiler(StackProfiler.class)
.include(JMHConstantsTest.class.getSimpleName())
.build();
new Runner(opts).run();
}
关于Profile部分不再展开,略。
参考文档:
《Java高并发编程详解:深入理解并发核心库》汪文君
https://www.cnkirito.moe/java-jmh/
END.
注意:本文归作者所有,未经作者允许,不得转载