上一篇文章《CentOS安装Redis》已经安装好了Redis,本篇文章将讲解Redis的基本使用以及五种数据类型。
注意:本篇文章使用的redis版本是6.2.1,到今天为止,redis8.0已经GA了,但是实际上基础使用命令差别不大。
一、常用命令
1、redis命令行
REDIS是一种NoSQL数据库,它和MySQL数据库一样,都有和Server端交互的命令行工具,而且在这个命令行工具下,还有非常友好的命令提示。
我安装的是docker版本的redis,可以先使用命令docker exec -it 容器名 /bin/bash进入容器,然后打开/usr/local/bin目录,就可以看到redis安装后提供的相关工具了
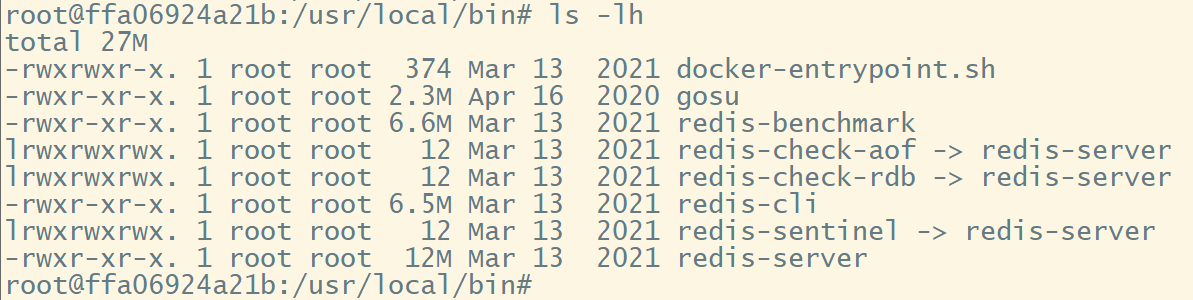
直接运行./redis-cli就可以进入命令行

2、认证命令auth
进入命令行以后,如果redis设置了密码,则直接运行相关的命令会提示报错,需要先执行auth命令认证,auth命令的格式如下:
AUTH [username] password
username可选。

3、查看信息命令info
info是个很有用的命令,可以使用该命令查看当前运行的redis server的所有状态,包括:redis server的版本号、CPU信息、内存信息、持久化信息、数据库信息等等
info [section]
使用info命令默认显示如下:
# Server
redis_version:6.2.1
redis_git_sha1:00000000
redis_git_dirty:0
......
# Clients
connected_clients:2
cluster_connections:0
maxclients:10000
......
# Memory
used_memory:894792
used_memory_human:873.82K
used_memory_rss:10809344
......
# Persistence
loading:0
current_cow_size:0
current_fork_perc:0.00%
......
# Stats
total_connections_received:3
total_commands_processed:283
instantaneous_ops_per_sec:0
......
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
......
# CPU
used_cpu_sys:4.598728
used_cpu_user:4.760232
used_cpu_sys_children:0.003479
......
# Modules
# Errorstats
errorstat_ERR:count=1
errorstat_NOAUTH:count=2
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
db1:keys=1,expires=0,avg_ttl=0
info命令的输出很长,而且输出是带注释的,注释中的内容表示“模块名”,共分为10个模块,info [section]中的section正是模块名:
| 模块 | 查询命令 | 作用 |
|---|---|---|
| Server | info server | 提供Redis服务器基本信息,如版本号、运行时间、操作系统、进程ID、配置文件路径等。 |
| Clients | info clients | 显示客户端连接状态,包括连接数、阻塞客户端数量、输入/输出缓冲区大小等。 |
| Memory | info memory | 展示内存使用详情,包括已用内存、内存碎片率、峰值内存、分配器等,用于监控内存优化。 |
| Persistence | info persistence | 记录RDB和AOF持久化状态,如最近保存时间、后台操作状态、AOF重写进度等。 |
| Stats | info stats | 统计命令处理数量、连接数、键过期/驱逐情况、每秒操作数等性能指标。 |
| Replication | info replication | 主从复制信息,包括角色(master/slave)、从节点列表、复制偏移量、延迟等。 |
| CPU | info cpu | 统计CPU消耗,包括用户态和系统态时间、子进程CPU占用等。 |
| Modules | info modules | 用于查看当前 Redis 服务器加载的模块信息 |
| Cluster | info cluster | 显示集群状态,如节点信息、槽分配情况(仅集群模式有效)。 |
| Keyspace | info keyspace | 统计各数据库的键数量、过期键数量及平均TTL。 |
4、切换数据库命令select
redis数据库默认有16个,编号从0到15,对redis的读写操作实际上是针对某个redis库的读写操作,使用select命令切换使用的数据库:
select index
index是从0到15的整数。
在redis-cli下,在没有选择数据库的情况下,默认读写操作都是在数据库0下操作的:
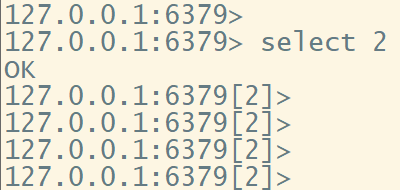
使用select命令选择非0的数据库之后,将会在命令行中显示当前使用的数据库:
另外,可以使用client info命令更直观的看到当前链接使用的客户端信息(包含使用的数据库)

5、客户端管理命令client
client命令用于查看和管理连接到redis server的客户端信息。
client list
列出当前所有连接到 Redis 的客户端信息:
CLIENT LIST
主要输出字段及说明:
| 字段 | 说明 |
|---|---|
id |
客户端唯一 ID |
addr |
客户端 IP 和端口 |
name |
客户端名称(可自定义) |
db |
当前使用的数据库编号 |
age |
连接已建立时间(秒) |
idle |
空闲时间(秒) |
flags |
连接类型(N=普通客户端,M=主节点,S=从节点等) |
cmd |
最近执行的命令 |
client info
查看当前连接到Redis的客户端信息,其输出格式和client list命令一样,但是只显示当前连接的客户端信息。
client setname
为当前连接设置一个易读的名称,方便管理:
client setname kdyzm-connection
client getname
查看当前连接的客户端名称。

client kill
该命令用于终止某个客户端的连接,完整命令格式如下:
client kill [ip:port] [ID client-id] [TYPE normal|master|slave|pubsub] [USER username] [ADDR ip:port] [SKIPME yes/no]
从命令格式中就可以看得出,该命令可以通过多种方式终止客户端的连接。
比如想终止id为5的连接,可以使用命令client kill id 5
6、数据清理命令
| 命令 | 作用 |
|---|---|
flushdb [ASYNC|SYNC] |
删除当前数据库的所有键 |
flushall [ASYNC|SYNC] |
删除所有数据库的所有键 |
这两个命令往往会触发安全策略被禁止执行。
二、五种数据类型
Redis的存储是以Key-Value形式存储的,value有五种类型:string、hash、list、set、zset 以应对不同数据格式的存储。
1、string
String类型是最简单的数据类型,它的值是字符串类型或者数字类型。
赋值
| 命令 | 作用 |
|---|---|
SET key value |
设置指定 key 的值。 |
MSET key value [key value ...] |
同时设置一个或多个 key-value 对。 |
APPEND key value |
APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾,返回值是追加后字符串长度 |
SETNX key value |
仅当不存在时赋值,使用该命令可以实现【分布式锁】的功能 |
查询
| 命令 | 作用 |
|---|---|
GET key |
查询指定 key 的值。 |
MGET key [key ...] |
同时获取一个或多个key值 |
STRLEN key |
返回键值的长度,如果键不存在则返回0 |
GETRANGE key start end |
获取key值的子串,坐标从0开始,start到end为闭区间;end为-1表示最后一个字符 |
更新
| 命令 | 作用 |
|---|---|
GETSET key value |
为key设置新值value,并返回旧值 |
INCR key |
自增命令。 当value为整数数据时,才能使用该命令,该命令是原子操作,返回值是自增后的新值 |
INCRBY key increment |
增加increment命令。 当value为整数数据时,才能使用该命令,该命令是原子操作,返回值是增加后的新值 |
DECR key |
自减命令。 当value为整数数据时,才能使用该命令,该命令是原子操作,返回值是自减后的新值 |
DECRBY key decrement |
减少decrement命令。 当value为整数数据时,才能使用该命令,该命令是原子操作,返回值是减少后的新值 |
2、hash
hash 类型也叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等 其它类型,它的数据结构和java中的Map或者Python中的字典比较像,hash 特别适合用于存储对象。
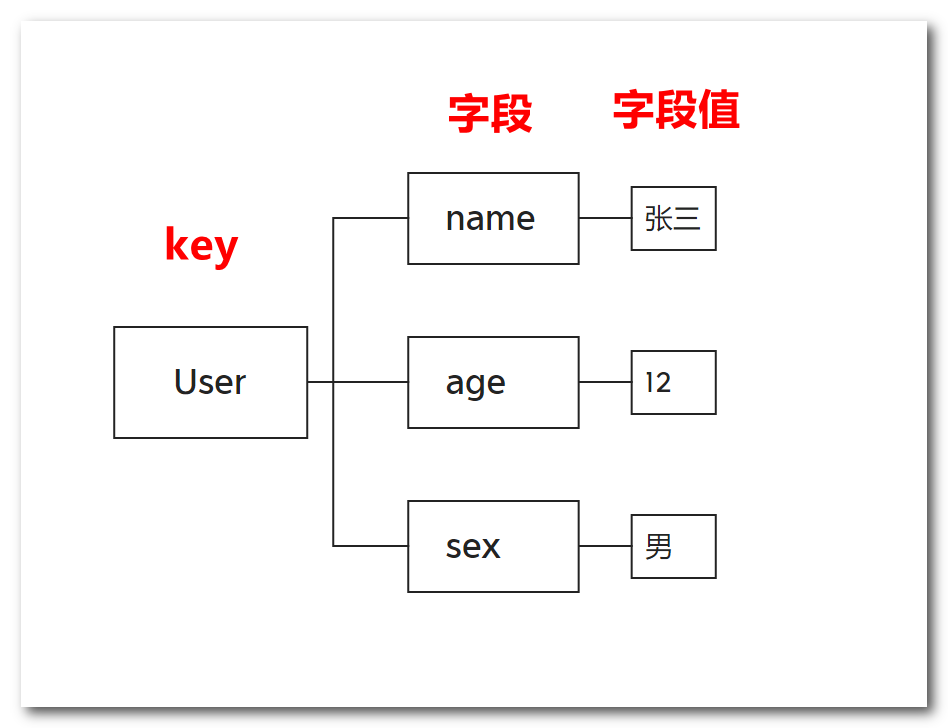
赋值
| 命令 | 作用 |
|---|---|
hset key field value [field value ...] |
设置多个属性值,例如hset user name zhangsan age 14,返回值是一个整数表示新增的字段数量 |
hmset key field value [field value ...] |
设置多个属性值,返回值为成功或者失败; 新版本已经不推荐使用该方法设置了,推荐使用hset。 |
hsetnx key field value |
类似 HSET ,区别在于如果字段存在,该命令不执行任何操作。 |
查询
| 命令 | 作用 |
|---|---|
hget key field |
获取一个字段值,例如:hget user name |
hmget key field [field ...] |
获取多个字段值,例如:hmget user name age |
hgetall key |
获取所有字段值,例如:hgetall user |
hexists key field |
判断某个属性是否存在 |
hkeys key |
获取所有属性 |
hvals key |
获取所有值 |
hlen key |
获取字段数量 |
更新
| 命令 | 作用 |
|---|---|
hdel key field [field ...] |
删除key的属性字段 注意并非删除key,删除key应当使用通用的del命令。 |
hincrby key field increment |
增加increment命令。 当属性值为整数数据时,才能使用该命令,该命令是原子操作,返回值是增加后的新值 |
hincrbyfloat key field increment |
增加increment命令。 当属性值为数字类型时,才能使用该命令,该命令是原子操作,返回值是增加后的新值 相对于hincrby,它支持浮点数的运算,但是可能存在精度丢失的问题。 |
3、list
redis中的list可以存储一个有序的字符串列表,它的内部是一个双向链表所以向列表两端添加元素的时间复杂度为0(1) ,获取越接近两端的元素速度就越快。基于此特性,list数据类型可被用于消息队列操作。
入队出队
| 命令 | 作用 |
|---|---|
lpush key element [element ...] |
从左侧入队。比如lpush list 1 2 3 实际上在list中存储的顺序是3 2 1 |
rpush key element [element ...] |
从右侧入队。比如rpush list 1 2 3实际上在list中存储的也是1 2 3 |
lpop key [count] |
左侧弹出一个元素或者count个元素。 |
rpop key [count] |
右侧弹出一个元素或者count个元素。 |
更新
| 命令 | 作用 |
|---|---|
lrem key count element |
删除列表中指定个数的值。 LREM 命令会删除列表中前 count 个值为 value 的元素,返回实际删除的元素个数。 根据 count 值的不同,该命令的执行方式会有所不同: 当count>0时, LREM会从列表左边开始删除。 当count<0时, LREM会从列表后边开始删除。 当count=0时, LREM删除所有值为value的元素。 |
lset key index element |
设置index下标(正向)的数组值为element |
linsert key BEFORE|AFTER pivot element |
向列表中插入元素。 该命令首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是BEFORE还是AFTER来决定将value插入到该元素的前面还是后面。 |
ltrim key start stop |
只保留列表指定片段,指定范围和LRANGE一致 |
rpoplpush source destination |
将source的最后一个元素转移到destination的头部 |
查询
| 命令 | 作用 |
|---|---|
lrange key start stop |
查询指定范围(闭区间)的元素列表 |
lindex key index |
查询指定元素下标的值 |
llen key |
查询列表元素长度 |
4、set
set 类型即集合类型,其中的数据是不重复且没有顺序。
集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型的 Redis 内部是使用值 为空的散列表实现,所有这些操作的时间复杂度都为 0(1) 。
Redis 还提供了多个集合之间的交集、并集、差集的运算。
基础命令
| 命令 | 作用 |
|---|---|
sadd key member [member ...] |
向集合中添加元素 |
srem key member [member ...] |
从集合中移除元素 |
smembers key |
获得集合中的所有元素 |
sismember key member |
判断元素是否在集合中 |
scard key |
获得集合中元素的个数 |
spop key [count] |
随机从集合中移除count个元素 |
集合运算
假设我们有A集合{1,2,3}和B集合{3,4,5}
| 命令 | 作用 |
|---|---|
sdiff key [key ...] |
取差集。sdiff A B相当于A-B,结果为{1,2} |
sinter key [key ...] |
取交集。sinter A B相当于A∩B,结果为{3} |
sunion key [key ...] |
取并集。suion A B相当于A∪B,结果为{1,2,3,4,5} |
5、zset
zet又称为sorted set,即有序集合,它是在 set 集合类型的基础上,为集合中的每个元素都关联一个分数 ,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。在某些方面有序集合和列表类型有些相似:
- 二者都是有序的。
- 二者都可以获得某一范围的元素。
但是,二者有着很大区别:
- 列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
- 有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
- 列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
- 有序集合要比列表类型更耗内存。
zadd命令
zadd命令用于向有序集合中新增或更新元素,它是有序集合中最重要的一个命令,其格式如下所示:
zadd key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]
可以看到它有很多可选参数,这导致该命令比较复杂。
基础使用命令
刨除可选参数,zadd的基础命令就是
zadd key score member [score member ...]
注意,分数在前,元素在后。
127.0.0.1:6379> zadd scoreboard 80 zhangsan 89 lisi 94 wangwu
(integer) 3
可选参数[NX|XX]
NX:不存在则添加,否则忽略
XX:存在则更新分数,否则忽略
127.0.0.1:6379> zadd z nx 90 zhangsan #zhangsan不存在则新增
(integer) 1
127.0.0.1:6379> zadd z nx 90 zhangsan #zhangsan已存在则忽略
(integer) 0
127.0.0.1:6379> zadd z xx 80 lisi #lisi不存在则忽略
(integer) 0
127.0.0.1:6379> zadd z xx 80 zhangsan #lisi已存在则更新
(integer) 0
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "80"
可选参数[GT|LT]
GT:当新分数大于原分数时才更新
LT:新分数小于原分数时才更新
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "80"
127.0.0.1:6379> zadd z GT 79 zhangsan # zhangsan新分数79大于原分数80才更新,所以没更新
(integer) 0
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "80"
127.0.0.1:6379> zadd z GT 81 zhangsan # zhangsan新分数81大于原分数80才更新,所以更新了
(integer) 0
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "81"
可选参数[CH]
CH参数的作用:返回值改为所有被修改的成员数量(包括新增和更新的成员)。zadd的默认行为是仅统计新添加的成员。
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "90"
127.0.0.1:6379> zadd z 91 zhangsan #修改了zhangsan的分数为91但是返回0
(integer) 0
127.0.0.1:6379> zadd z CH 91 zhangsan #虽然加了CH参数,但是新旧分数都一样都是91所以并没有执行修改动作
(integer) 0
127.0.0.1:6379> zadd z CH 92 zhangsan #加了CH参数,新分数92修改后返回了影响行数
(integer) 1
可选参数INCR
将成员的分数累加指定值(类似 ZINCRBY),此时只能操作一个成员。返回值是更新后的分数值。建议使用zincrby。
127.0.0.1:6379> zrange z 0 -1 withscores
1) "zhangsan"
2) "95"
127.0.0.1:6379> zadd z incr 3 zhangsan #zhangsan增加3
"98"
更新
| 命令 | 作用 |
|---|---|
zincrby key increment member |
有序集合中对指定成员的分数加上增量 increment |
zrem key member [member ...] |
移除有序集合中的一个或多个成员 |
zremrangebyscore key min max |
根据分值范围删除范围内的所有成员 |
zremrangebylex key min max |
移除有序集合中给定的字典区间的所有成员 |
zremrangebyrank key start stop |
移除有序集合中给定的排名区间的所有成员 |
查询
| 命令 | 作用 |
|---|---|
zrange key min max [BYSCOREBYLEX] [REV] [LIMIT offset count] [WITHSCORES] |
获取索引在min和max之间的成员。 比如 zrange z 0 -1 withscores命令将查询z集合的全部成员。 |
zcard key |
获取有序集合的成员数 |
zcount key min max |
计算在有序集合中指定区间分数的成员数 |
zrangebyscore key min max [WITHSCORES] [LIMIT offset count] |
通过分数返回有序集合指定区间内的成员 |
zrank key member |
查询member的索引 |
zscore key member |
查询成员分值 |
集合运算
| 命令 | 作用 |
|---|---|
zdiff numkeys key [key ...] [WITHSCORES] |
求差集 |
zinter numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] [WITHSCORES] |
求交集 |
zunion numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] [WITHSCORES] |
求并集 |
zdiffstore destination numkeys key [key ...] |
求差集并将结果存入有序集合destination |
zinterstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] |
求交集并将结果存入有序集合destination |
zunionstore destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] |
求并集并将结果存入有序集合destination |
三、key操作命令
以上五种数据类型都没有介绍删除命令,因为它们都使用统一的key删除命令。
1、常见命令
以下是常见的key命令:
| 命令 | 作用 |
|---|---|
del key [key ...] |
删除一个或多个key |
exists key [key ...] |
判断一个key或者多个key是否存在 |
expire key seconds |
为key设置过期时间,单位秒 |
keys pattern |
查询指定模式的key列表,比如常见的keys *查询所有key,注意该命令可能会导致redis server被阻塞。 |
move key db |
将key移动到别的db |
persist key |
移除key的过期时间,key将持久保存 |
ttl key |
以秒为单位返回key的剩余有效期事件,有效期过后key将被删除 |
pttl key |
以毫秒为单位返回key的剩余有效期事件,有效期过后key将被删除 |
rename key newkey |
将key重命名 |
renamenx key newkey |
在newkey不存在的情况下将key重命名为newkey |
type key |
查询某个key的类型 |
除了以上常见命令,还有一个比较重要的常见命令scan。
2、scan命令
Redis 的 SCAN 命令是一种**非阻塞式、渐进式遍历键空间(key space)**的迭代器命令,用于替代阻塞式的 KEYS 命令,特别适合生产环境中处理大数据量的键遍历需求。
scan命令格式如下:
scan cursor [MATCH pattern] [COUNT count] [TYPE type]
cursor:游标值,初始为 0,每次调用返回新的游标,直到返回 0 表示遍历完成
MATCH pattern(可选):通配符模式匹配键名(如 user:* 匹配以 user: 开头的键)
COUNT count(可选):提示每次迭代返回的键数量(默认约 10 个,实际可能浮动)
TYPE type(Redis 6.0+):按数据类型过滤(如 string、hash 等)
来看一个例子。
现在我有如下keys
127.0.0.1:6379> keys *
1) "c"
2) "g"
3) "d"
4) "f"
5) "a"
6) "e"
7) "h"
8) "b"
127.0.0.1:6379>
我要用scan命令来遍历它:
127.0.0.1:6379> scan 0 match * count 1 type string #初始从0开始遍历
1) "4" #下一个游标是4
2) 1) "c" #本次返回的结果是c
127.0.0.1:6379> scan 4 match * count 1 type string #从4开始下一个迭代查询
1) "2" #下一个游标是2
2) 1) "h" #本次返回两个值:h、b
2) "b"
127.0.0.1:6379> scan 2 match * count 1 type string
1) "6"
2) 1) "g"
2) "d"
127.0.0.1:6379> scan 6 match * count 1 type string
1) "7"
2) 1) "f"
2) "a"
3) "e"
127.0.0.1:6379> scan 7 match * count 1 type string
1) "0"
2) (empty array)
注意,虽然指定了每次返回的数量是1,但是返回的数量大部分并不是1,似乎count参数设置的并没有生效:这是因为COUNT 不保证精确性,它是性能优化的提示,非强制限制。SCAN 使用高位进位加法遍历哈希槽,避免因扩容/缩容遗漏数据。此算法可能导致单次遍历多个槽位,从而返回更多元素。
scan命令只用于key的遍历,对于么比如hash、set、zset类型的,它们本身也是可以遍历的,所以还有scan的变种命令:
| 命令 | 作用 |
|---|---|
hscan key cursor [MATCH pattern] [COUNT count] |
hash类型的key遍历 |
sscan key cursor [MATCH pattern] [COUNT count] |
set类型的key遍历 |
zscan key cursor [MATCH pattern] [COUNT count] |
zset类型的key遍历 |
注意:本文归作者所有,未经作者允许,不得转载