伪共享的定义:伪共享(False Sharing) 是指多个处理器核心或线程在并发执行时,由于共享相同缓存行而导致不必要的性能下降的现象。当多个处理器核心或线程同时访问共享的内存区域,即使它们在不同的变量上操作,但这些变量处于同一个缓存行中,会导致频繁的缓存行无效化,从而降低性能。
一、CPU的物理缓存架构
由于CPU的运算速度比主存(物理内存)的存取速度快很多,为了提高处理速度,现代CPU不直接和主存进行通信,而是在CPU和主存之间设计了多层的Cache(高速缓存),越靠近CPU的高速缓存越快,容量也越小。
CPU 的物理缓存架构通常由三个级别的缓存组成:L1 缓存、L2 缓存和 L3 缓存。
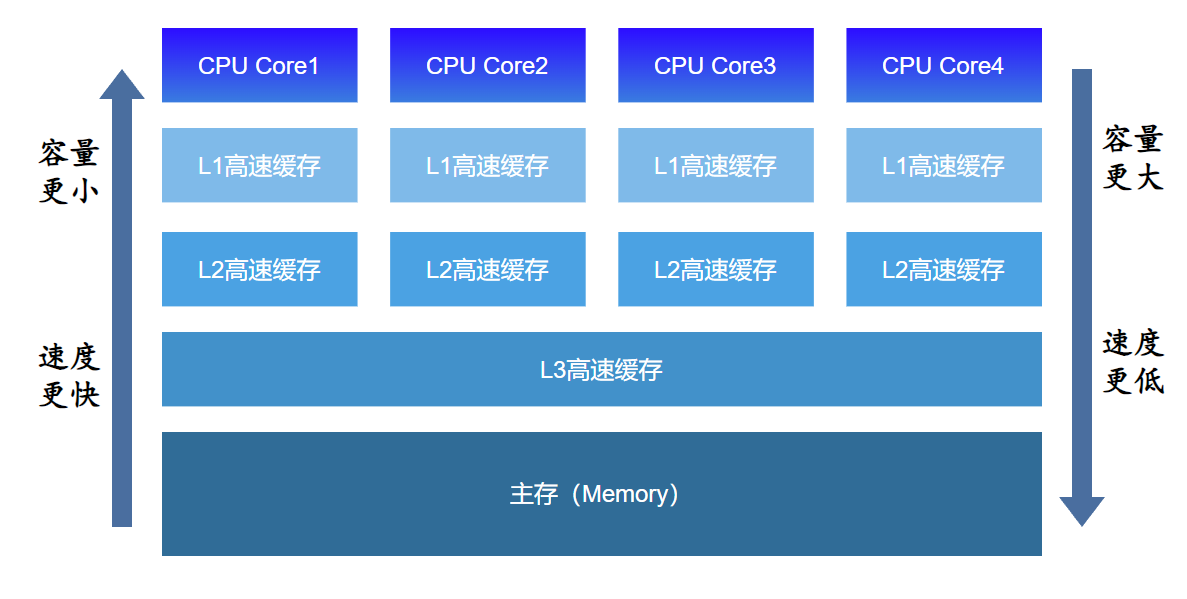
三级缓存架构是当前CPU的主流缓存架构
L1缓存:L1缓存常分为L1 数据缓存(L1 Data Cache)以及L1 指令缓存(L1 Instruction Cache),用于存储最频繁访问的数据和指令。L1 缓存是私有的,每个 CPU 核心都有自己的 L1 缓存,大小为32KB、48KB不等,速度也是最快的。
L2缓存:L2高速缓存容量更大(如256KB)、速度低些,L2缓存也是CPU内核独享的,每个内核上都有一个独立的L2高速缓存。
L3缓存:L3高速缓存最接近主存,容量最大(如12MB)、速度最低,由在同一个CPU芯片板上的不同CPU内核共享
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。每一级高速缓存中所存储的数据都是下一级高速缓存的一部分,越靠近CPU的高速缓存读取越快,容量也越小。所以L1高速缓存容量很小,但存取速度最快,并且紧靠着使用它的CPU内核。L2容量大一些,存取速度也慢一些,并且仍然只能被一个单独的CPU核使用。L3在现代多核CPU中更普遍,容量更大、读取速度更慢些,能被同一个CPU芯片板上的所有CPU内核共享。最后,系统还拥有一块主存(即主内存),由系统中的所有CPU共享。拥有L3高速缓存的CPU,CPU存取数据的命中率可达95%,也就是说只有不到5%的数据需要从主存中去存取。
1、查看Windows机器的CPU信息
可以使用CPU-Z软件查看Windows机器的CPU信息,CPU-Z官网地址:https://www.cpuid.com/
以我的12700H处理器为例,它的信息如下所示
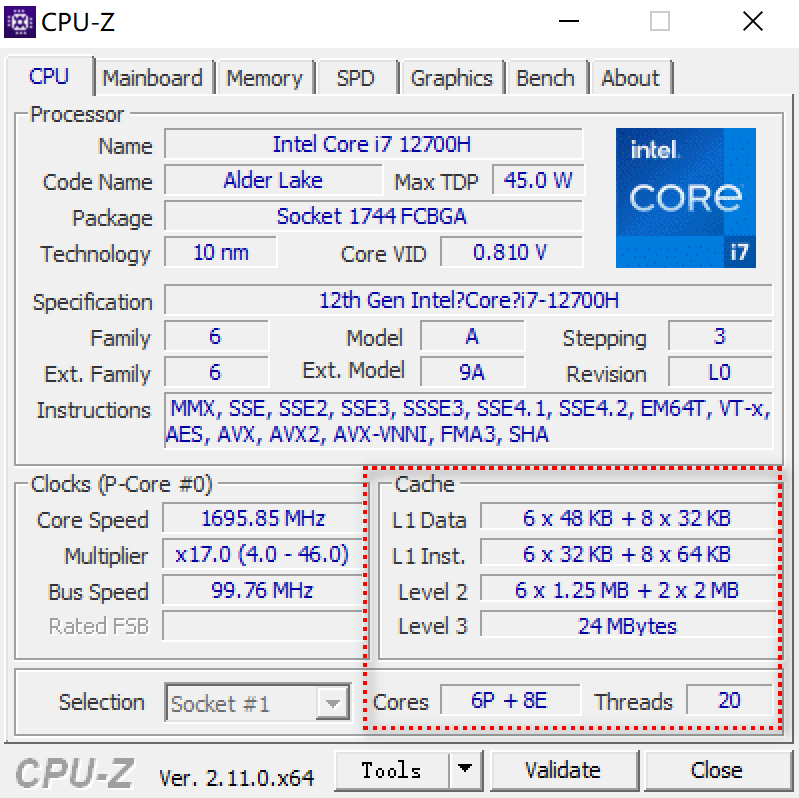
可以看到我的处理器是14核20线程处理器,分为三级缓存,每个缓存的大小也标记的很清楚。这里有疑问的是6P和8E,这14核处理器里面的核心还分成了两种:P-Core和E-Core
P-Core:性能核心 ,性能核心主要用于处理高性能任务,如游戏、视频编辑和其他需要大量计算的应用;支持超线程(Hyper-Threading),即每个核心可以同时处理两个线程;功耗较高,适合在负载较重时使用。
E-core:效率核心 ,效率核心主要用于优化能效,处理轻量级任务,如后台进程和多任务处理。通常具有较低的时钟速度;不支持超线程,通常每个核心处理一个线程;功耗较低,适合在负载较轻时使用。
这20线程就是6个性能核心X2+8个效率核心X1=20得到的。
2、查看Linux机器的CPU信息
通过一个命令可以看到:lscpu,该命令的输出信息如下所示
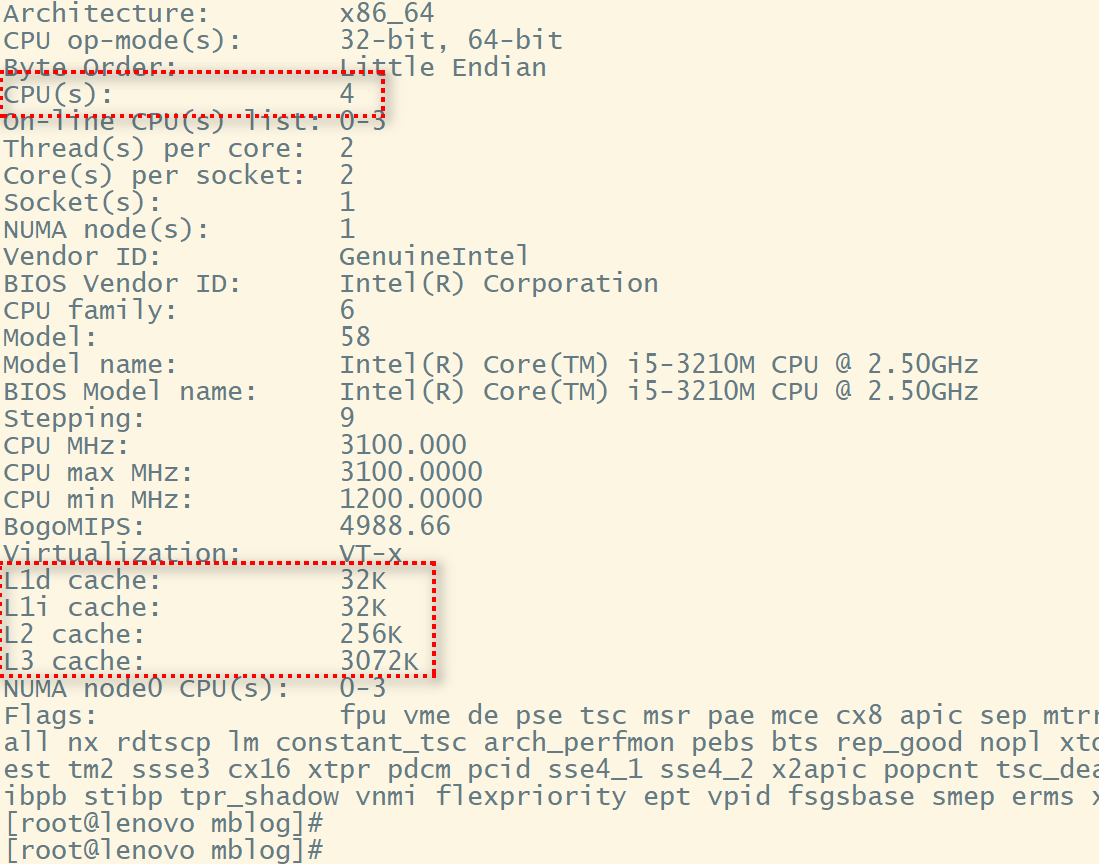
我这个linux机器的CPU是十几年前的产物了,可以看到无论是核心数还是缓存大小,和现在的处理器都没法比了。
二、缓存行
可以将CPU-Z的检测详情导出到Html文件中
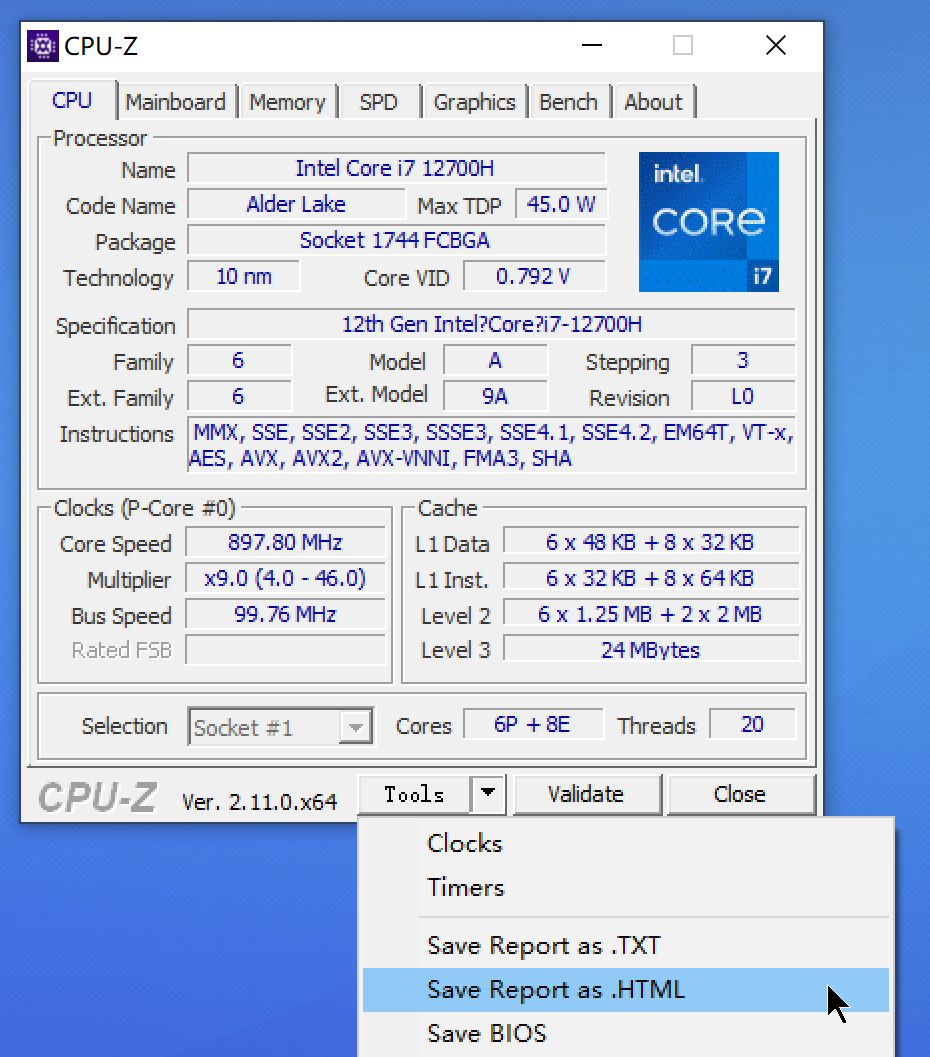
导出来后,看看关于缓存部分它的详细检测信息

这部分检测的结果括号中有类似"xx-way"以及"64-byte line"的字样,这是什么意思?以L2 cache为例:
10-way: 表示该L2缓存中每组有10个缓存行。
64-byte line: 表示每个缓存行大小是64字节。
缓存行(Cache Line)是缓存(Cache)中存储数据的基本单位。每个缓存行的大小通常是固定的,一般是64字节。
三、伪共享
在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节,即一个缓存行。假设有1到8,一共8个long类型的数字(64字节,一个缓存行)在主内存中连续的内存地址块中,如果我们读取了1,则1到8这8个数字都会被缓存到一个缓存行中。
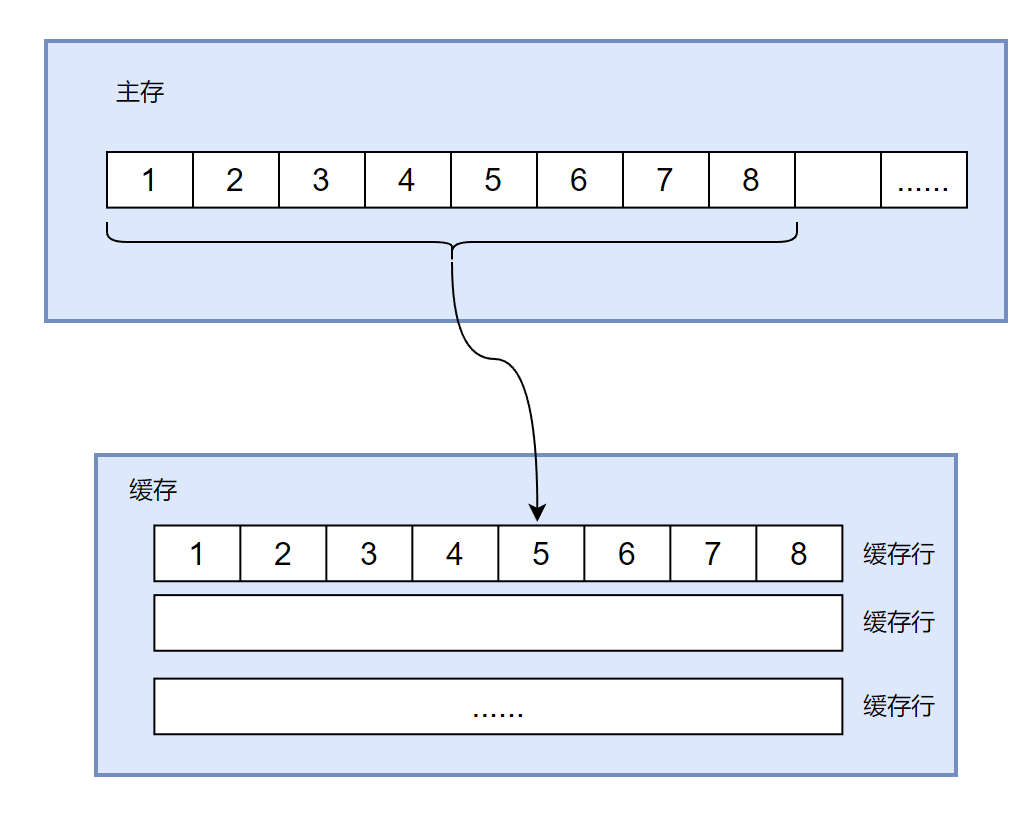
失效也是,如果缓存行中某个变量缓存失效了,则整个缓存行都会失效。而这会带来问题,看下面的例子:
如果我们有个 long 类型的变量 a,还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。一开始的时候,a和b在CPU核心1和CPU核心2的缓存中都存在。在这种情况下,如果一个CPU核心的线程更新a,另外一个处理器核心线程读取b,则会出现“伪共享”问题。当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。
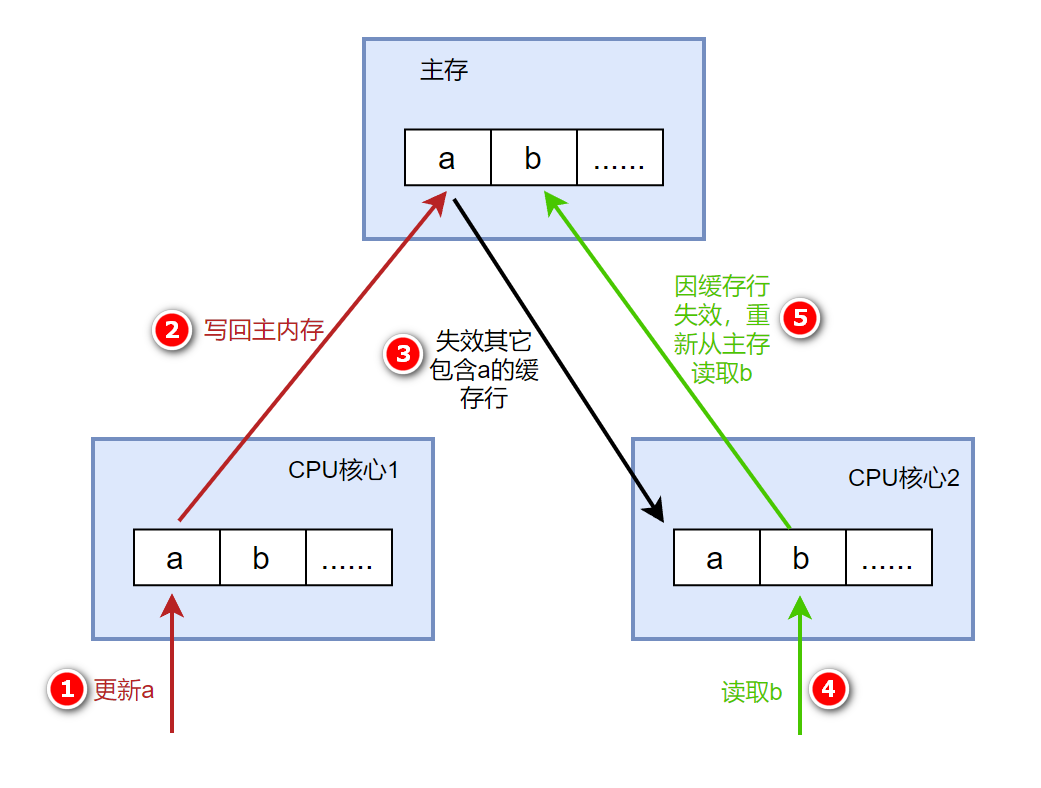
我们的缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取b,b被a的缓存失效给拖累了。
接下来看看伪共享问题的解决方案。
为了凸显解决方案的正确性,先使用微基准测试方法(详情看文章:《微基准测试工具JMH》 )统计相邻两个变量自增一亿次的平均时间
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Group)
@Fork(1)
@Warmup(iterations = 5, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Timeout(time = 10, timeUnit = TimeUnit.SECONDS)
public class JmhFalseSharingOrigin {
//保证可见性使用volatile
private volatile long a, b;
@Benchmark
@GroupThreads
@Group("falseSharing")
public void aIncrease() {
a++;
}
@Benchmark
@GroupThreads
@Group("falseSharing")
public void bIncrease() {
b++;
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JmhFalseSharingOrigin.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
输出结果:

可以看到,变量a和变量b自增一亿次大概需要27秒左右。按照之前的分析,其结果应当是受到了伪共享问题的影响,效率是非常低的,现在将其结果作为对照组,接下来使用两种方式解决伪共享问题。
1、解决方式一:@Contented注解
最简单的方式就是使用@Contented注解方式,将该注解加在变量上,然后JVM虚拟机加上启动参数:-XX:-RestrictContended 即可生效。
完整代码如下
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import sun.misc.Contended;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Group)
@Fork(value = 1,jvmArgsAppend = "-XX:-RestrictContended")
@Warmup(iterations = 5, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Timeout(time = 10, timeUnit = TimeUnit.SECONDS)
public class JmhFalseSharingOrigin {
//保证可见性使用volatile
@Contended
private volatile long a, b;
@Benchmark
@GroupThreads
@Group("falseSharing")
public void aIncrease() {
a++;
}
@Benchmark
@GroupThreads
@Group("falseSharing")
public void bIncrease() {
b++;
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JmhFalseSharingOrigin.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
运行结果:

可以看到,平均时间从27秒降到了6秒左右。侧面反应了对照组的结果确实受到了伪共享的影响。
2、解决方式二:字节填充
为了让伪共享不影响到a变量和b变量,将a变量和b变量放在两个缓存行中就可以了,这样变量a和变量b就不会相互影响了。
我们知道一个缓存行是64字节大小,正好是8个long类型数字所占据的大小,但是缓存行的构成还有标记位等数据占据了相应空间,不到一个long类型的大小,所以实际上一个缓存行实际能存储7个long类型的数字,剩余空间不到8字节存储不了一个long类型的数字了;所以在a和b变量之间只需要插入6个long类型的变量,这样就可以保证a和b分别在不同的缓存行中了。
完整代码如下
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import sun.misc.Contended;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/10/9
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Group)
@Fork(1)
@Warmup(iterations = 5, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 1, batchSize = 1000000000, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Timeout(time = 10, timeUnit = TimeUnit.SECONDS)
public class JmhFalseSharingOrigin {
//保证可见性使用volatile
private volatile long a, x1, x2, x3, x4, x5, x6, x7, b;
@Benchmark
@GroupThreads
@Group("falseSharing")
public void aIncrease() {
a++;
}
@Benchmark
@GroupThreads
@Group("falseSharing")
public void bIncrease() {
b++;
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(JmhFalseSharingOrigin.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
运行结果:

很明显,字节填充方案比较麻烦,还是直接用@Contented注解比较好。
END.
注意:本文归作者所有,未经作者允许,不得转载