从上一篇文章《深入理解偏向锁、轻量级锁、重量级锁》中已经介绍了关于锁升级相关的知识,在其中研究偏向锁的过程中,无意中调用了hashCode方法,然后锁的状态发生了明显不符合预期的变化。
一、偏向锁回顾
首先看下偏向锁的案例,这个之前已经介绍过了,这里重新拿出来的目的是为了作为对照组比较实验结果
需要加入依赖
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.32</version>
</dependency>
<!--Java Object Layout -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>
下面是偏向锁案例的代码
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import lombok.extern.slf4j.Slf4j;
import org.openjdk.jol.info.ClassLayout;
/**
* 启动前注意加上jvm启动参数:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
*
* @author kdyzm
* @date 2024/10/28
*/
@Slf4j
public class HashCodeEffect {
public static void main(String[] args) throws InterruptedException {
User lock = new User();
Thread threadA = new Thread(() -> {
//① lock.hashCode();
log.info("抢占锁前lock的状态:\n{}", lock.getObjectStruct());
for (int i = 0; i < 100; i++) {
synchronized (lock) {
if (i == 99) {
//② lock.hashCode();
log.info("占有锁lock的状态:\n{}", lock.getObjectStruct());
}
}
}
//③ lock.hashCode();
log.info("释放锁后lock的状态:\n{}", lock.getObjectStruct());
}, "A");
Thread threadB = new Thread(() -> {
//④ lock.hashCode();
log.info("抢占锁前lock的状态:\n{}", lock.getObjectStruct());
for (int i = 0; i < 100; i++) {
synchronized (lock) {
if (i == 99) {
//⑤ lock.hashCode();
log.info("占有锁lock的状态:\n{}", lock.getObjectStruct());
}
}
}
//⑥ lock.hashCode();
log.info("释放锁后lock的状态:\n{}", lock.getObjectStruct());
}, "B");
threadA.start();
threadA.join();
threadB.start();
threadB.join();
}
@ToString
@Setter
@Getter
public static class User {
private String userName;
//对象结构字符串
public String getObjectStruct() {
return ClassLayout.parseInstance(this).toPrintable();
}
}
}
使用两个线程串行对一个对象获取锁、释放锁,其中不断使用JOL工具打印锁对象的内存结构以观察锁状态,最后结果是
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | biasable(可偏向的) | biased(偏向锁,偏向线程A) | biased(偏向锁,偏向线程A) |
| 线程B | biased(偏向锁,偏向线程A) | thin lock(轻量级锁) | non-biasable(无锁) |
在这个案例中,锁状态的变化流程图如下
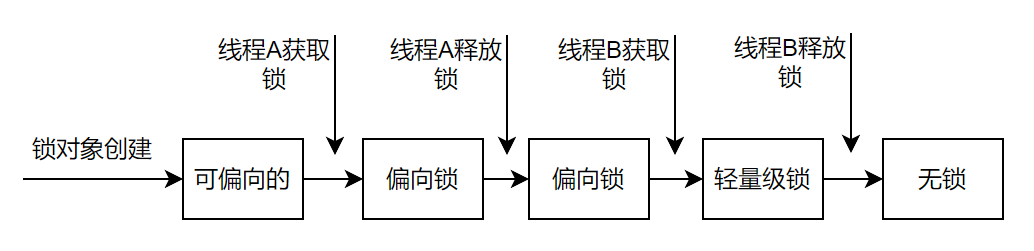
在代码中有标记hashCode插入的地方①②③④⑤⑥,对应流程图中的标记如下
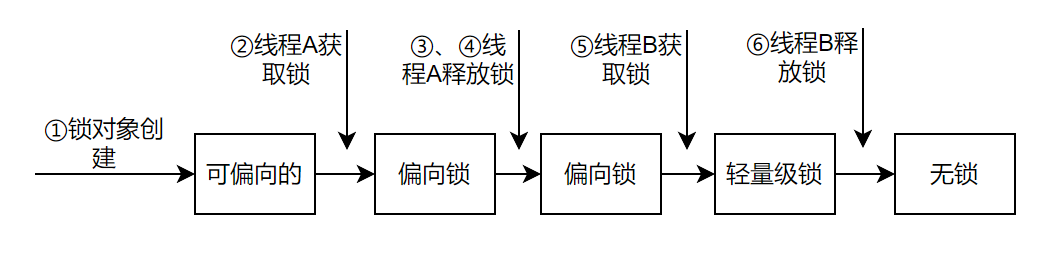
接下来对这些地方依次插入lock.hashCode()方法调用,观察调用hashCode方法对锁状态的影响。
二、hashCode方法调用的影响
① 线程A获取锁前调用hashCode方法
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | 可偏向->调用hashCode方法->无锁 | thin lock(轻量级锁) | 无锁 |
| 线程B | 无锁 | thin lock(轻量级锁) | non-biasable(无锁) |
其流程图状态变化
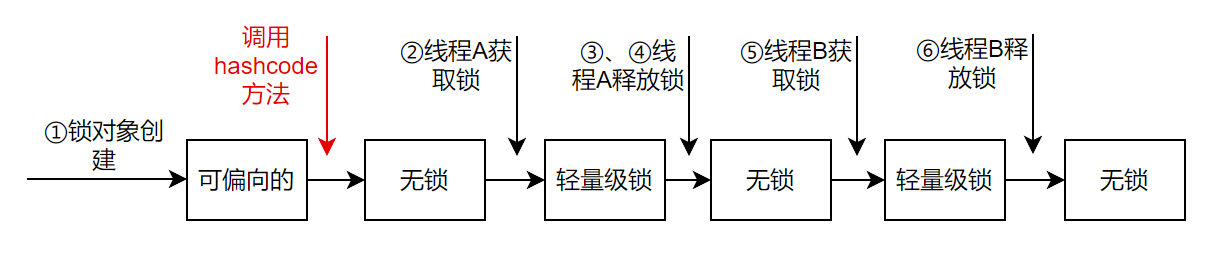
可以看到如果当前锁状态是“可偏向”状态,这时候调用hashCode方法,锁状态会变成“无锁”状态,之后线程A再获取锁,锁状态无法偏向成偏向锁,直接成为轻量级锁。
② 线程A获取锁后调用hashCode方法
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | biasable(可偏向的) | 偏向锁->调用hashCode方法->fat lock(重量级锁) | fat lock(重量级锁)->无锁 |
| 线程B | 无锁 | thin lock(轻量级锁) | 无锁 |
其流程图状态变化

同步代码块内,线程A获取到锁之后锁已经变成了偏向锁状态,但是这时候调用hashCode方法,会让偏向锁跳过轻量级锁直接膨胀成重量级锁,重量级锁在释放锁后并没有立即变成无锁状态,而是稍等了一下才变成无锁状态。
③线程A释放锁,④线程B获取锁前调用hashCode方法
③、④位置均是偏向锁状态,所以可以任意放开其中之一注释即可。
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | biasable(可偏向的) | biased(偏向锁,偏向线程A) | biased(偏向锁,偏向线程A) |
| 线程B | 偏向锁->调用hashCode方法->无锁 | thin lock(轻量级锁) | 无锁 |
其流程图状态变化

同步代码块外,偏向锁状态下调用hashCode方法,锁会变成无锁状态。
⑤ 线程B获取锁后调用hashCode方法
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | biasable(可偏向的) | biased(偏向锁,偏向线程A) | biased(偏向锁,偏向线程A) |
| 线程B | biased(偏向锁,偏向线程A) | 轻量级锁->调用hashCode方法->重量级锁 | 重量级锁->无锁 |
其流程图状态变化

在同步代码块内,B线程获取到锁之后,锁状态先变成轻量级锁状态,之后调用hashCode方法后,就变成了重量级锁状态,释放锁后过了一段时间才变成了无锁状态。
⑥ 线程B释放锁后调用hashCode方法
| 线程名 | 加锁前 | 加锁中 | 释放锁后 |
|---|---|---|---|
| 线程A | biasable(可偏向的) | biased(偏向锁,偏向线程A) | biased(偏向锁,偏向线程A) |
| 线程B | biased(偏向锁,偏向线程A) | thin lock(轻量级锁) | non-biasable(无锁)->无锁(带hashCode) |
其流程图状态变化

虽然都是无锁,但是还是有些变化,调用hashCode方法之后,无锁状态的MarkWord中的hashCode字段就被填充了。
重写hashCode方法的影响
重写锁类的hashCode方法后,调用锁对象的hashCode方法,并不会影响Mark Word中的hashCode字段的值。换句话说,重写hashCode后,调用或者不调用hashCode方法都不会影响锁的状态了。
三、总结
若锁类没有重写hashCode方法,锁状态将受hashCode方法调用的影响,这分为两种情况:
- 同步代码块内,调用hashCode方法,无论当前锁状态是什么,都会立即变成重量级锁。
- 同步代码块外,调用hashCode方法,无论当前锁状态是什么,都会立即变成无锁状态。
四、探究原因
hashCode方法的调用为什么会影响锁状态呢?几乎所有的多线程开发的书籍中都没有给出原因,但是在周志明的《深入理解Java虚拟机:JVM高级特性与最佳实践(第三版)》中却给出了答案,第五部分第13章第13.3.5节:偏向锁中有这么一段话
当对象进入偏向状态的时候,Mark Word大部分的空间(23个比特)都用于存储持有锁的线程ID了,这部分空间占用了原有存储对象哈希码的位置,那原来对象的哈希码怎么办呢?
在Java语言里面一个对象如果计算过哈希码,就应该一直保持该值不变(强烈推荐但不强制,因为用户可以重载hashCode()方法按自己的意愿返回哈希码),否则很多依赖对象哈希码的API都可能存在出错风险。而作为绝大多数对象哈希码来源的Object::hashCode()方法,返回的是对象的一致性哈希码(Identity Hash Code),这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。因此,当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求 [1] 时(注意,这里说的计算请求应来自于对Object::hashCode()或者System::identityHashCode(Object)方法的调用,如果重写了对象的hashCode()方法,计算哈希码时并不会产生这里所说的请求。),它的偏向状态会被立即撤销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码。
翻译下这是什么意思:
对象头中存储的是一致性哈希码,它是未重写hashCode方法的前提下通过Object::hashCode()或者System::identityHashCode(Object)方法计算得到的,这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。
这样可以解释第一个问题了:为什么无锁状态无法升级成偏向锁
偏向锁由于其作用机制原因无法存储计算出来的hashCode码,所以一旦无锁状态下调用hashCode方法,当前锁就再也无法进入偏向锁状态了,也可能由于此原因,偏向锁被释放后偏向锁状态也不会被撤销。而轻量级锁可以将整个Mark Word备份到栈帧中的Displaced Mark Word中,等释放锁就可以将其还原回去;重量级锁则有ObjectMonitor类记录非加锁状态下的MarkWord。轻量级锁和重量级锁均支持记录无锁状态的MarkWord,而偏向锁则无法记录,所以无锁状态不能转化为偏向锁,只能跳过偏向锁直接升级轻量级锁。
这样还有两个问题没有解决:
- 在同步代码块下偏向锁调用hashCode方法为什么会跳过轻量级锁直接膨胀为重量级锁
- 在同步代码块下轻量级锁调用hashCode方法为什么会膨胀为重量级锁
轻量级锁升级重量级锁可能还有原因可循:轻量级锁栈帧中已经保存了无锁状态的MarkWord(不包含hashCode码),一旦生成hashCode,当前状态下的轻量级锁肯定无法满足条件,要么撤销轻量级锁,重新加轻量级锁,要么就升级重量级锁,选择升级重量级锁倒也无可厚非。
至于在同步代码块下偏向锁调用hashCode方法为什么会跳过轻量级锁直接膨胀为重量级锁,就不得而知了。
END.
注意:本文归作者所有,未经作者允许,不得转载