博客园的博友们不知道有没有用过Markdown编辑器下方的“提取图片”功能,该功能就是解析Markdown编辑器中的所有图片链接,将其重新上传到博客园,生成博客园的图片链接后替换掉Markdown中的图片链接。功能是不错的功能,但是这个功能非常慢,而且最近总是会失败。
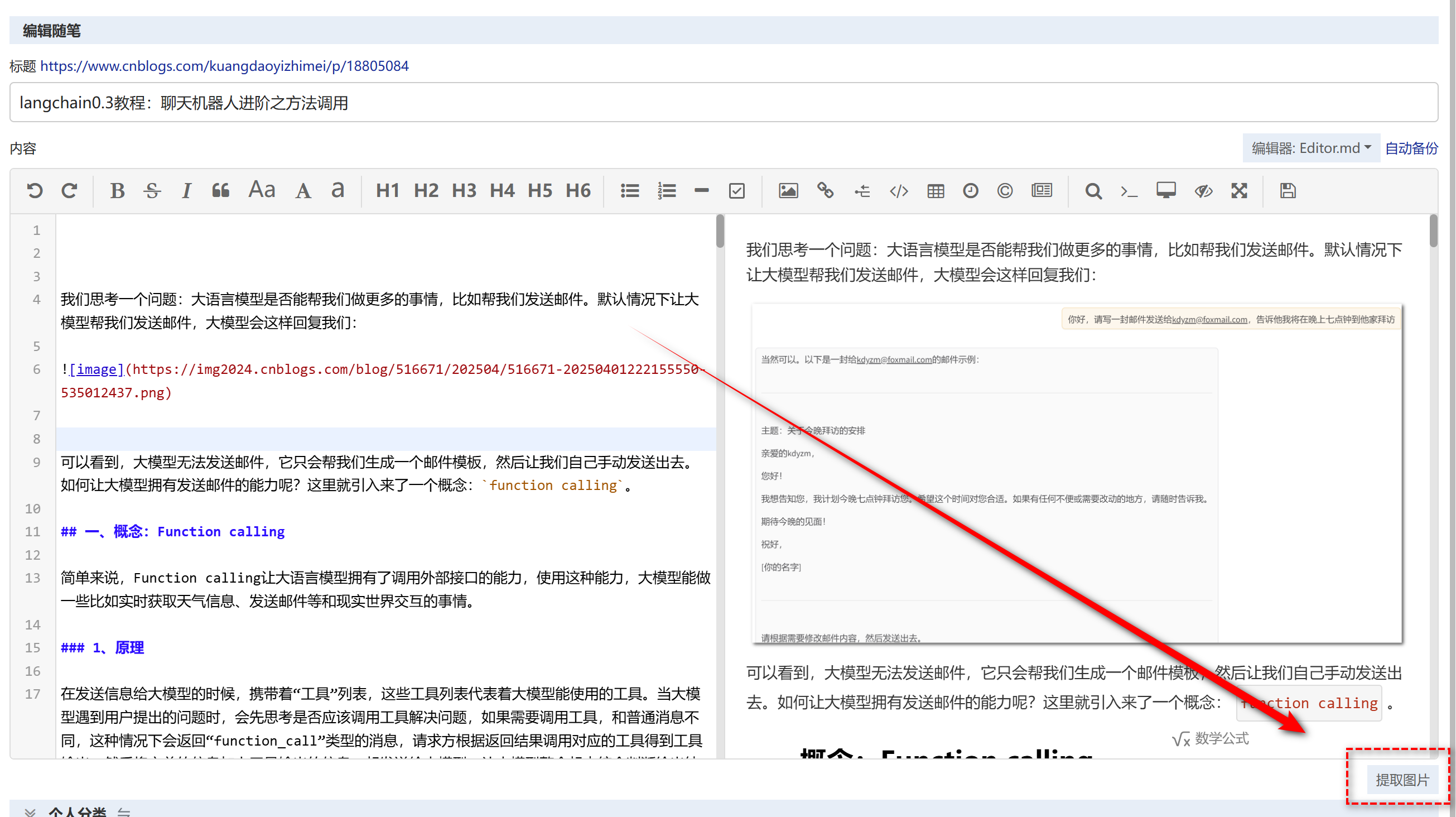
我一开始的解决方案是一个图片一个图片的在编辑器中重新上传(在编辑器中直接上传速度很快),但是这种方法效率太低了。。。为了解决这个问题,我写了一个Python脚本,脚本模拟在编辑器直接上传图片,上传成功后将图片链接替换成接口返回的链接。
一、Python脚本
运行脚本前,需要先安装第三方模块:
pip install requests
完整Python脚本如下所示:
"""
解析markdown文件中的图片并将图片上传到博客园图床,之后替换掉markdown文件中的图片链接
注意:使用该脚本需要替换掉代码中的cookie信息
"""
import tkinter as tk
from pathlib import Path
from tkinter import filedialog
import os
from typing import List, Dict
import re
import json
import requests
import uuid
import mimetypes
import shutil
#需要替换cookie值
cookie = ""
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
default_work_dir = "C:\\Users\\kdyzm\\Documents"
default_charset = "UTF-8"
def choose_markdown_files() -> str:
# 创建Tkinter根窗口并隐藏
root = tk.Tk()
root.withdraw()
# 配置文件对话框参数
file_path = filedialog.askopenfilename(
title="请选择markdown文件", # 对话框标题
initialdir=os.path.expanduser(default_work_dir), # 初始目录为用户主目录
filetypes=[ # 文件类型过滤
("Markdown文件", "*.md")
],
# multiple=True
)
# 销毁根窗口
root.destroy()
return file_path
def parse_content(content: str) -> List[str]:
origin_urls: List[str] = re.findall(r"https?://.+\.(?:jpg|png|gif|jpeg)", content, flags=re.IGNORECASE)
filter_urls = [url for url in origin_urls if "cnblogs.com" not in url]
return filter_urls
def download_file_to_temp_dir(image_url: str) -> Path:
"""
下载图片到本地
:param image_url: 远程url地址
:return: 下载到本地的绝对路径
"""
parent_dir = Path("temp")
if not parent_dir.exists():
parent_dir.mkdir()
random_name = uuid.uuid4()
suffix = image_url.split(".")[-1]
local_image_path = parent_dir.joinpath(str(random_name).lower() + "." + suffix)
print(f"正在下载图片:{image_url}")
with local_image_path.open("wb") as file:
response = requests.get(image_url)
file.write(response.content)
print(f"图片已下载到 {local_image_path.absolute()}")
return local_image_path
def do_upload_file(image_url: str) -> dict:
headers = {
"user-agent": user_agent,
"cookie": cookie
}
local_file = download_file_to_temp_dir(image_url)
with open(local_file.absolute(), "rb") as f:
mimetype, encoding = mimetypes.guess_type(local_file.name)
files = {
"imageFile": (local_file.name, f, mimetype)
}
post_data = {
"host": "www.cnblogs.com",
"uploadType": "Paste"
}
result = requests.post(
"https://upload.cnblogs.com/imageuploader/CorsUpload",
data=post_data,
files=files,
headers=headers
)
content = result.content.decode(default_charset)
return json.loads(content)
def upload_file(files: List[str]) -> Dict[str, str]:
if not files:
return dict()
file_map = {file: do_upload_file(file)["message"] for file in files}
return file_map
def replace_all(path: Path, image_map: dict):
"""
解析markdown文件并将所有旧文件链接替换为新文件链接
:param path: markdown文件路径
:param image_map: 文件map
:return:
"""
content = path.read_text(encoding=default_charset)
for key, value in image_map.items():
content = content.replace(key, value)
path.write_text(content, encoding=default_charset)
def clean_temp_file():
path = Path("temp")
if path.is_file():
path.unlink() # 删除文件
elif path.is_dir():
# 删除非空目录需要递归删除
shutil.rmtree(path)
else:
print("路径不存在或无效")
def open_file(path: Path):
os.startfile(path.absolute())
def process():
file_path = choose_markdown_files()
# 处理用户选择结果
if not file_path:
print("用户取消选择")
return
path = Path(file_path)
content = path.read_text(encoding=default_charset)
origin_urls = parse_content(content)
print("解析markdown文件获取到如下图片列表:")
print(f"{json.dumps(origin_urls, indent=4)}")
if not origin_urls:
print("未解析到符合条件的图片链接,即将退出程序")
return
image_map = upload_file(origin_urls)
print("获取到旧文件和新文件的字典:")
print(json.dumps(image_map, indent=4))
replace_all(path, image_map)
print("替换文件完成")
print("开始清理暂存文件")
clean_temp_file()
print("暂存文件清理完成")
print("即将打开目标文件")
open_file(path)
if __name__ == '__main__':
input("使用须知:使用此脚本必须修改脚本cookie字段,若已知晓,回车继续:")
process()
运行这个脚本前,需要先修改代码中的cookie值:登录博客园后,从浏览器中复制。
二、运行界面
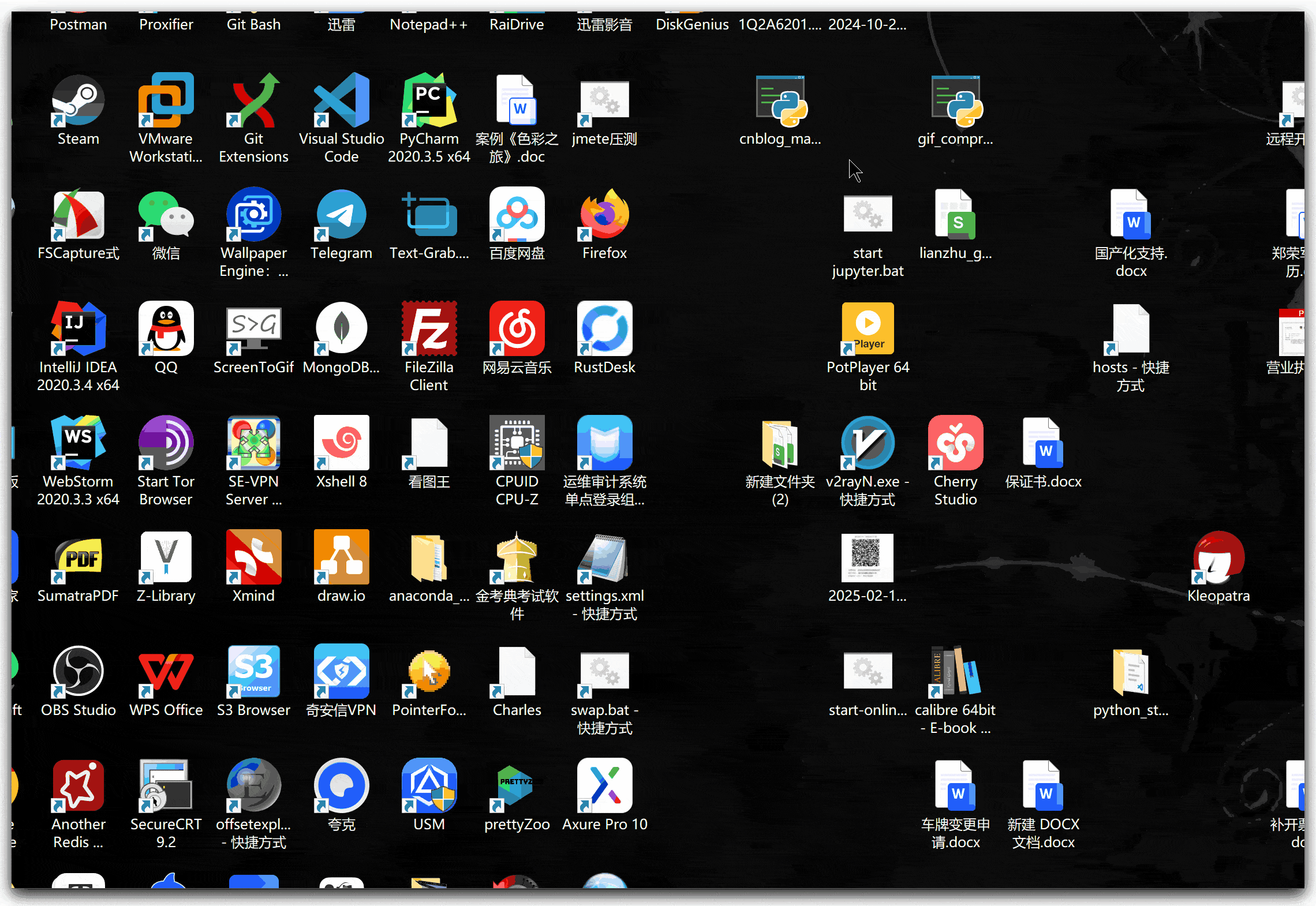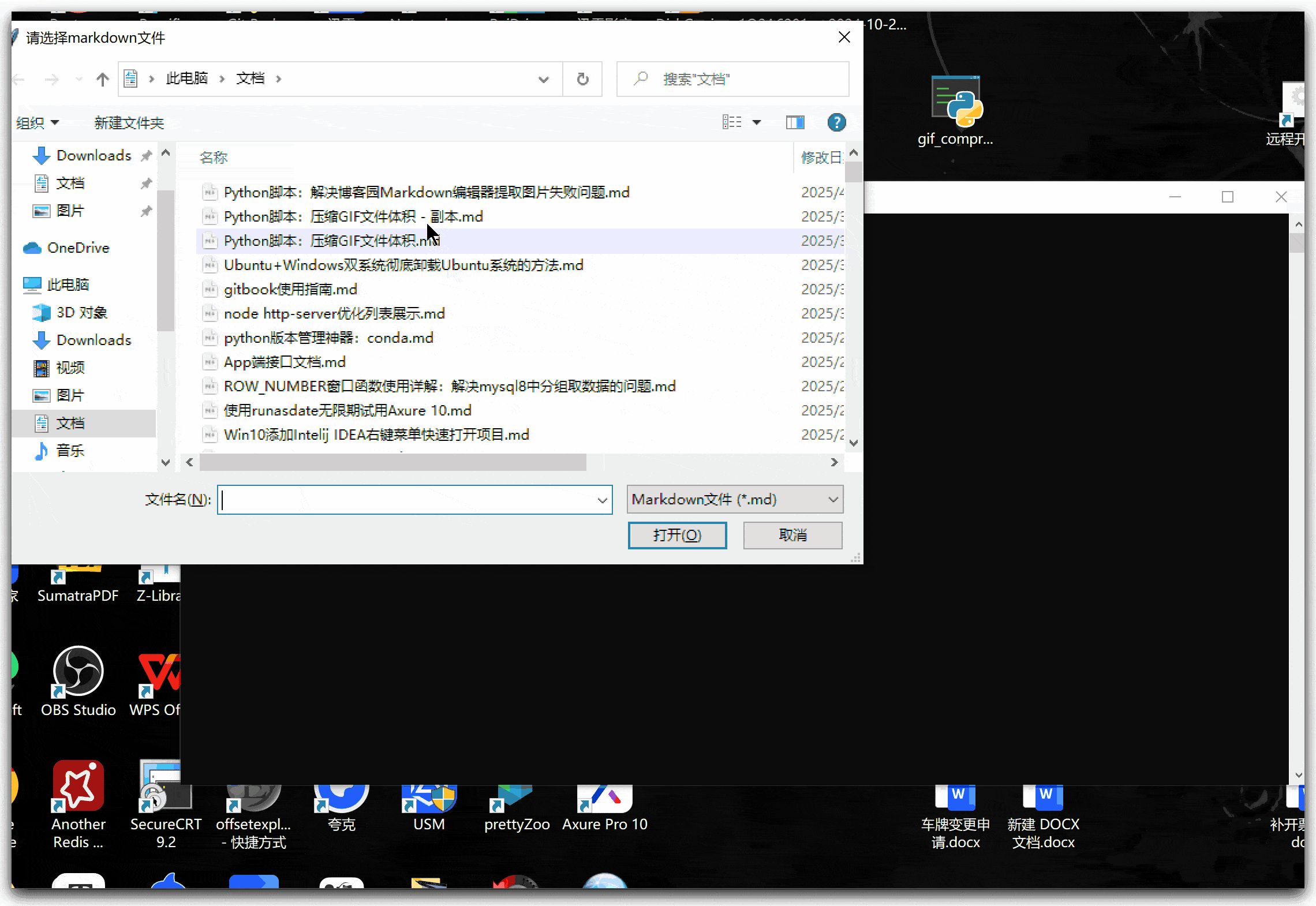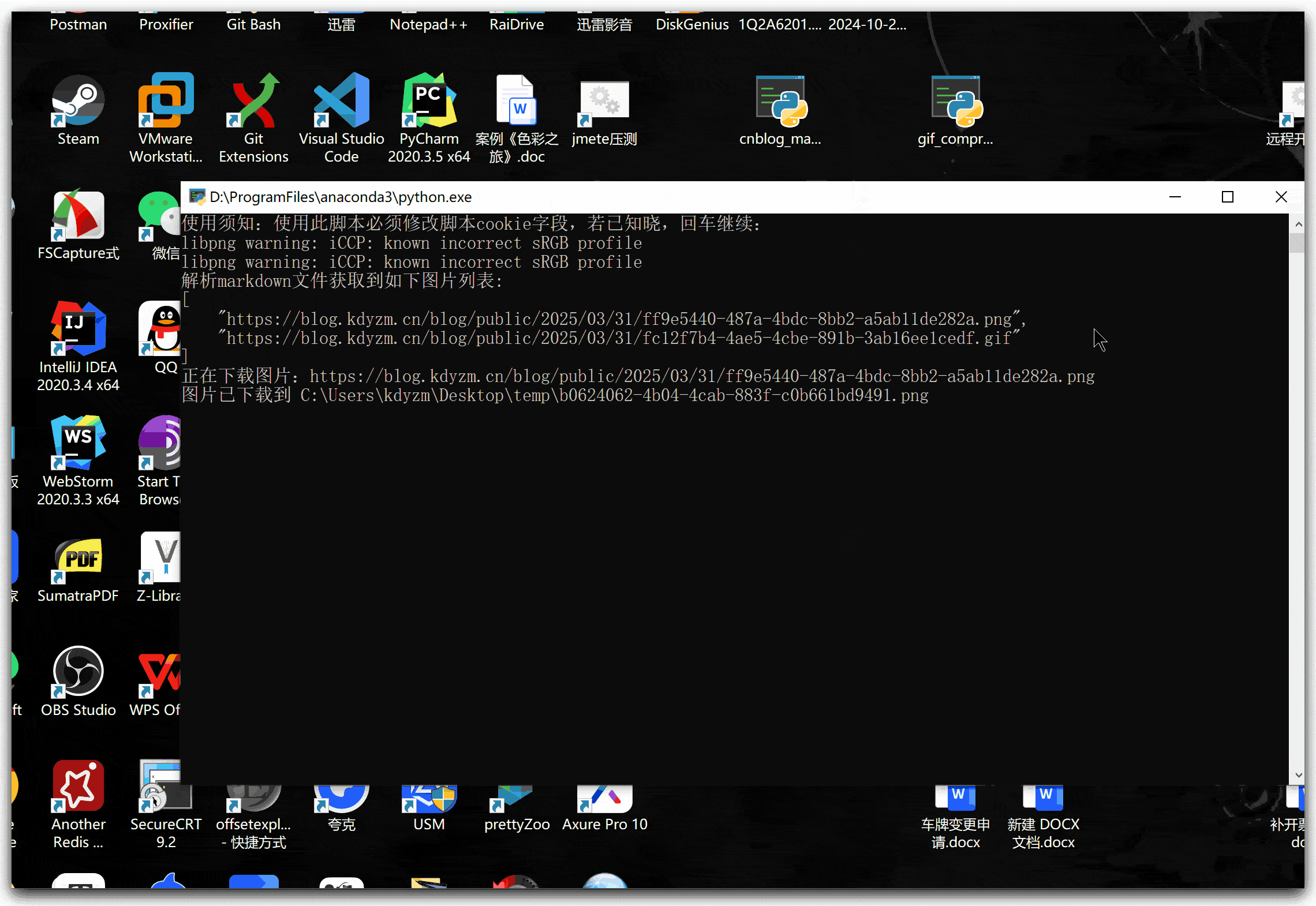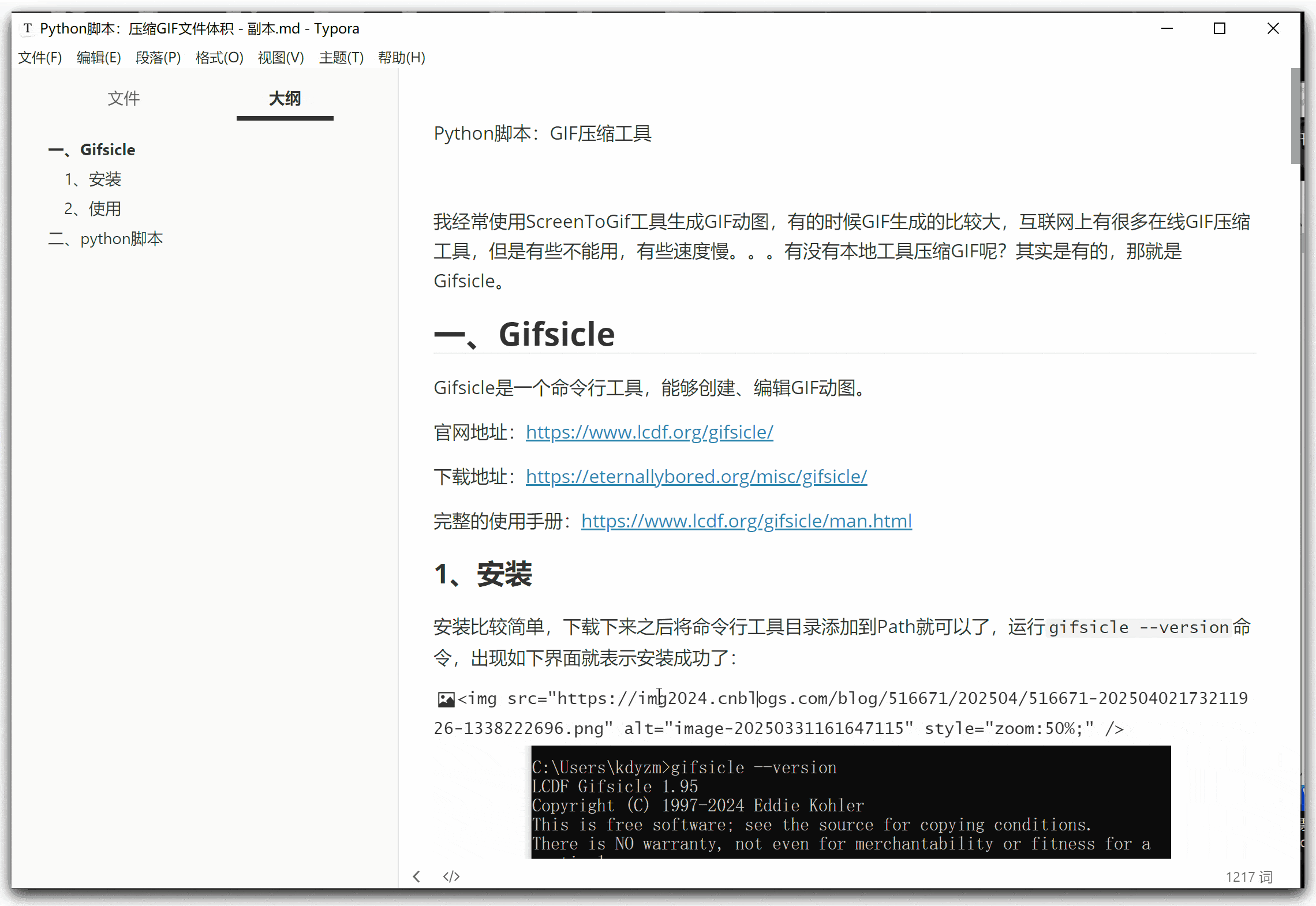
脚本运行时会在脚本所在目录创建一个temp文件夹,用于暂时存放下载的图片,脚本运行结束会自动删除该文件夹。
END.
注意:本文归作者所有,未经作者允许,不得转载