Redis多机部署有三种模式:主从复制模式、Sentinel(哨兵)模式、Cluster模式,本篇文章将基于Redis6.2.1讲解主从复制模式的部署、使用、常见问题等。
一、主从复制模式的部署
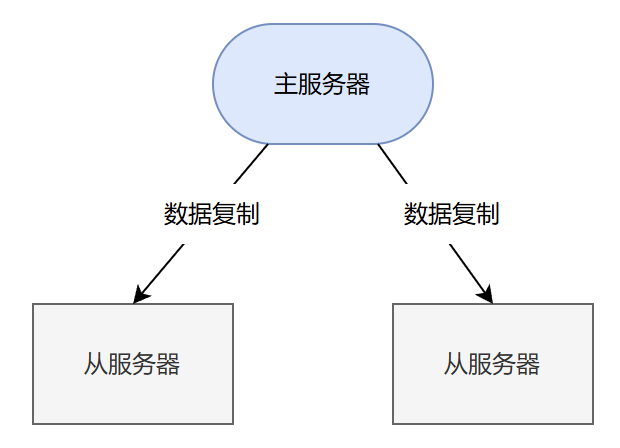
一般来说主从复制模式要用多台机器部署,由于资源有限,下面在一台机器上部署一主两从的主从复制架构。其架构图如下所示:
1、独立启动三个服务
创建3个文件夹:6379、6380、6381,参考单台Redis的安装教程:CentOS安装Redis (只看前三步到运行即可),将redis.conf配置文件以及redis-server、redis-cli配置文件复制到每个文件夹
├── 6379
│ ├── redis-cli
│ ├── redis.conf
│ ├── redis-server
├── 6380
│ ├── redis-cli
│ ├── redis.conf
│ ├── redis-server
└── 6381
├── redis-cli
├── redis.conf
└── redis-server
然后逐个使用命令./reids-server ./redis.conf启动服务,每个服务的启动日志类似如下所示:
2520:C 11 Jul 2025 11:11:08.314 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2520:C 11 Jul 2025 11:11:08.314 # Redis version=6.2.1, bits=64, commit=00000000, modified=0, pid=2520, just started
2520:C 11 Jul 2025 11:11:08.314 # Configuration loaded
2520:M 11 Jul 2025 11:11:08.316 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2520:M 11 Jul 2025 11:11:08.316 * monotonic clock: POSIX clock_gettime
2520:M 11 Jul 2025 11:11:08.317 * Running mode=standalone, port=6379.
2520:M 11 Jul 2025 11:11:08.317 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2520:M 11 Jul 2025 11:11:08.317 # Server initialized
2520:M 11 Jul 2025 11:11:08.317 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2520:M 11 Jul 2025 11:11:08.318 * Ready to accept connections
这时候启动的三个服务全都是主服务器,即master节点。 它们都是独立的server,相互之间并没有任何关系。
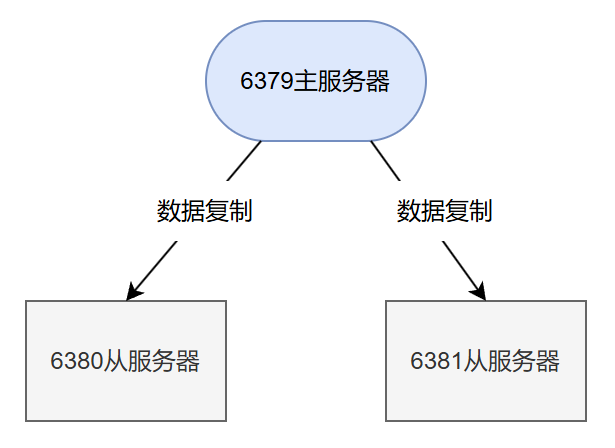
2、主从模式架构部署
上一步已经启动了三个独立的Redis Server,现在将6379端口号的服务作为master节点,将6380、6381端口号的服务作为从节点做主从复制模式配置,其结构图如下所示:
方法一:replicaof命令
第一种方式就是使用redis-cli连接6380、6381服务,运行 replicaof 命令:
REPLICAOF localhost 6379
以6380服务运行该命令为例,运行该命令的时候,6379服务的server.log日志会打印如下输出:
2520:M 11 Jul 2025 11:22:13.107 * Replica [::1]:6380 asks for synchronization
2520:M 11 Jul 2025 11:22:13.107 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'a1659b41814b4c2efffd56d4e1d4eb175a66f458', my replication IDs are '2cd002f50c115cfad4235840a1d16b047d05c097' and '0000000000000000000000000000000000000000')
2520:M 11 Jul 2025 11:22:13.107 * Replication backlog created, my new replication IDs are '63830caba228eb487be0aaaf561cee0258e21c3e' and '0000000000000000000000000000000000000000'
2520:M 11 Jul 2025 11:22:13.107 * Starting BGSAVE for SYNC with target: disk
2520:M 11 Jul 2025 11:22:13.141 * Background saving started by pid 2580
2580:C 11 Jul 2025 11:22:13.169 * DB saved on disk
2580:C 11 Jul 2025 11:22:13.169 * RDB: 4 MB of memory used by copy-on-write
2520:M 11 Jul 2025 11:22:13.198 * Background saving terminated with success
2520:M 11 Jul 2025 11:22:13.198 * Synchronization with replica [::1]:6380 succeeded
从日志中可以看到,6380运行preplicaof命令后,6379服务首先运行BGSAVE命令将自己的完整数据以RDB的格式备份到了硬盘上,然后将该文件传输给了6380服务。
看看6380服务的日志:
2529:S 11 Jul 2025 11:22:13.105 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2529:S 11 Jul 2025 11:22:13.105 * Connecting to MASTER localhost:6379
2529:S 11 Jul 2025 11:22:13.106 * MASTER <-> REPLICA sync started
2529:S 11 Jul 2025 11:22:13.106 * REPLICAOF localhost:6379 enabled (user request from 'id=3 addr=127.0.0.1:32840 laddr=127.0.0.1:6380 fd=8 name= age=63 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=44 qbuf-free=40910 argv-mem=22 obl=0 oll=0 omem=0 tot-mem=61486 events=r cmd=replicaof user=default redir=-1')
2529:S 11 Jul 2025 11:22:13.106 * Non blocking connect for SYNC fired the event.
2529:S 11 Jul 2025 11:22:13.106 * Master replied to PING, replication can continue...
2529:S 11 Jul 2025 11:22:13.107 * Trying a partial resynchronization (request a1659b41814b4c2efffd56d4e1d4eb175a66f458:1).
2529:S 11 Jul 2025 11:22:13.167 * Full resync from master: 63830caba228eb487be0aaaf561cee0258e21c3e:0
2529:S 11 Jul 2025 11:22:13.167 * Discarding previously cached master state.
2529:S 11 Jul 2025 11:22:13.198 * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
2529:S 11 Jul 2025 11:22:13.198 * MASTER <-> REPLICA sync: Flushing old data
2529:S 11 Jul 2025 11:22:13.198 * MASTER <-> REPLICA sync: Loading DB in memory
2529:S 11 Jul 2025 11:22:13.200 * Loading RDB produced by version 6.2.1
2529:S 11 Jul 2025 11:22:13.200 * RDB age 0 seconds
2529:S 11 Jul 2025 11:22:13.200 * RDB memory usage when created 1.83 Mb
2529:S 11 Jul 2025 11:22:13.200 * MASTER <-> REPLICA sync: Finished with success
6380进行了一次全量数据同步:6380接收到主服务器6379发送过来的数据保存到了硬盘上,之后清空自己所有的旧数据,然后从硬盘加载了RDB数据文件。
方法二:配置文件
使用上述方法一可以暂时实现主从模式架构的部署,但是服务器一重启就失效了,为了能永久有效,需要将该命令写入配置文件:修改6380和6381服务的redis.conf配置文件
replicaof localhost 6379
masterauth <master-password> #如果主服务器开启password需要新增这项配置
masteruser <username> #如果主服务器开启了ACL则需要新增这项配置
该配置项和命令是一样的。
这样修改完成后,再重新启动redis就不会丢失主从模式架构的配置了。
3、主从模式架构验证
上面已经将一主两从的主从复制模式架构搭建好了,现在验证下是否已经成功,如果我们在主服务器上设置了一个key,在从服务器上能查询到该key,则表示主从模式架构已经生效了。
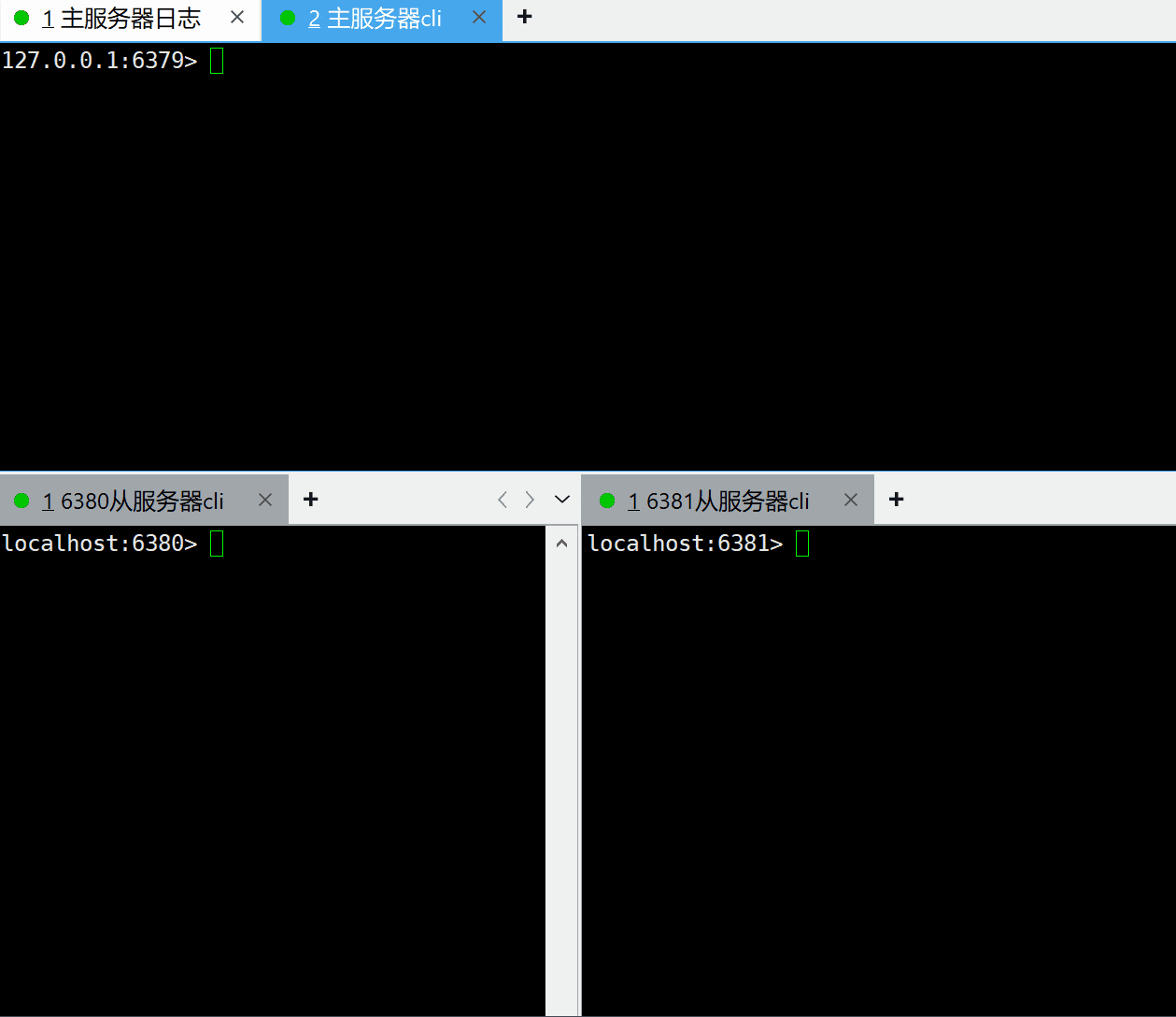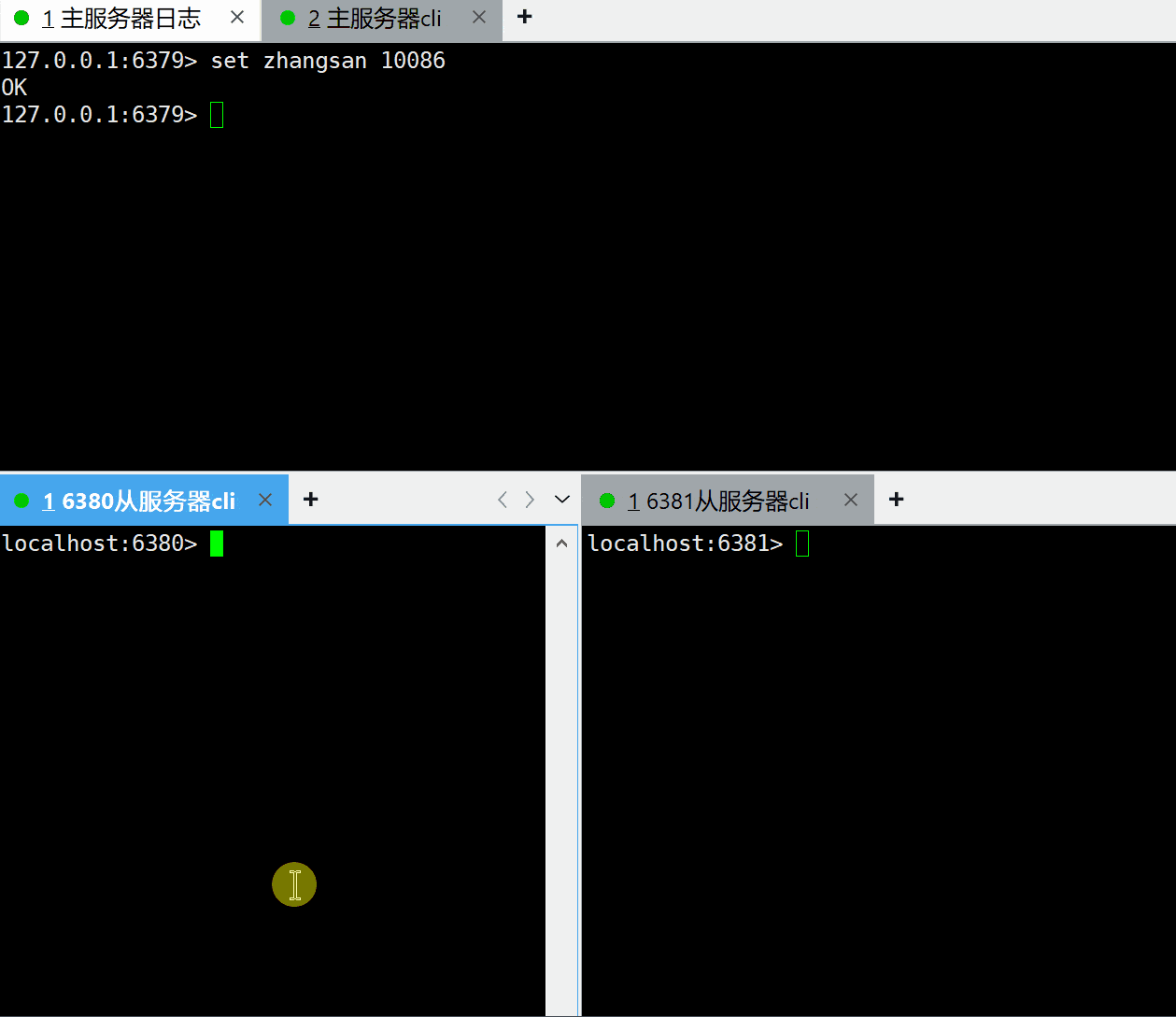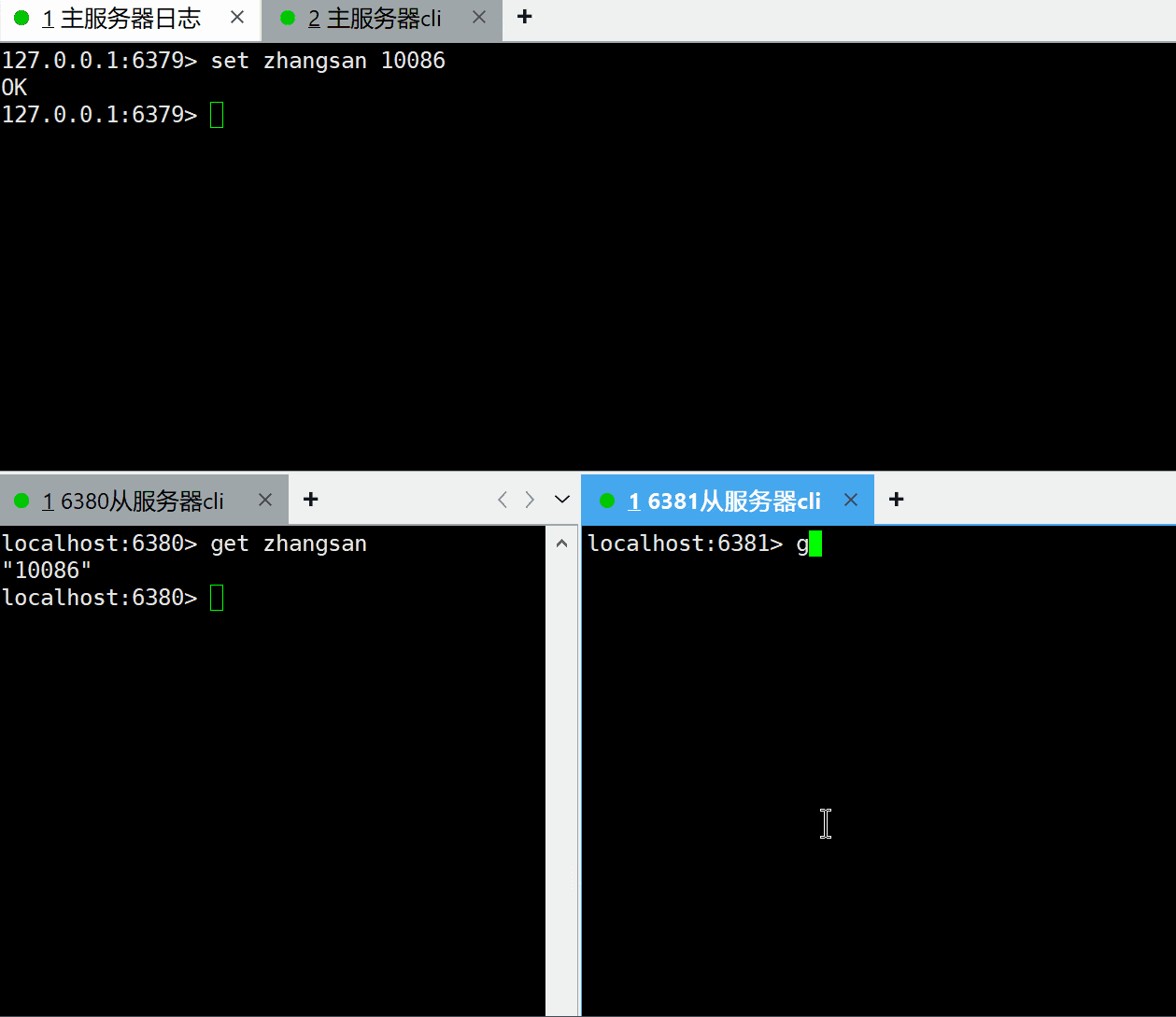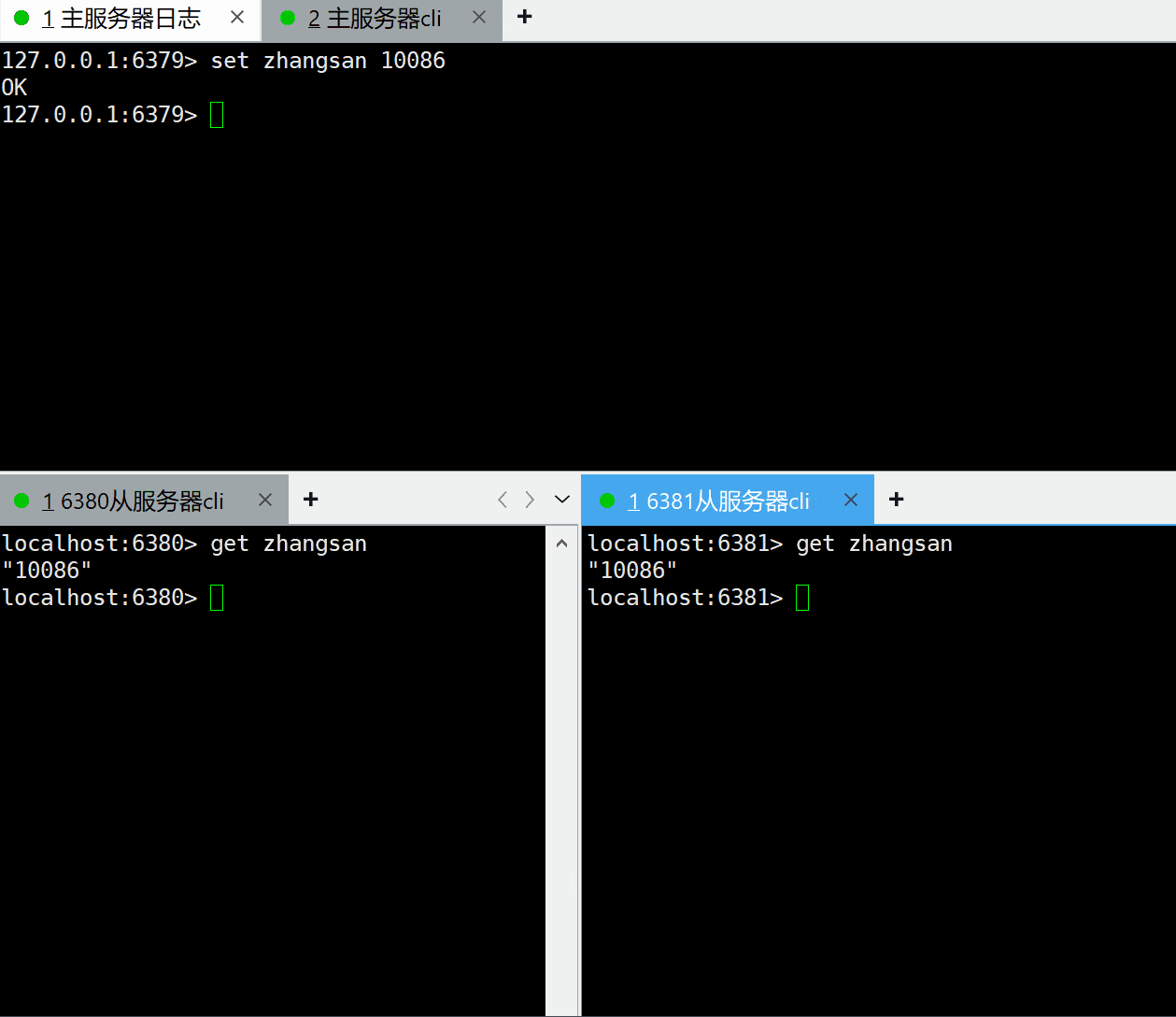
可以看到主服务器新增的key,已经顺利同步到了两个从服务器上,表示我们主从复制模式的架构已经搭建好了。
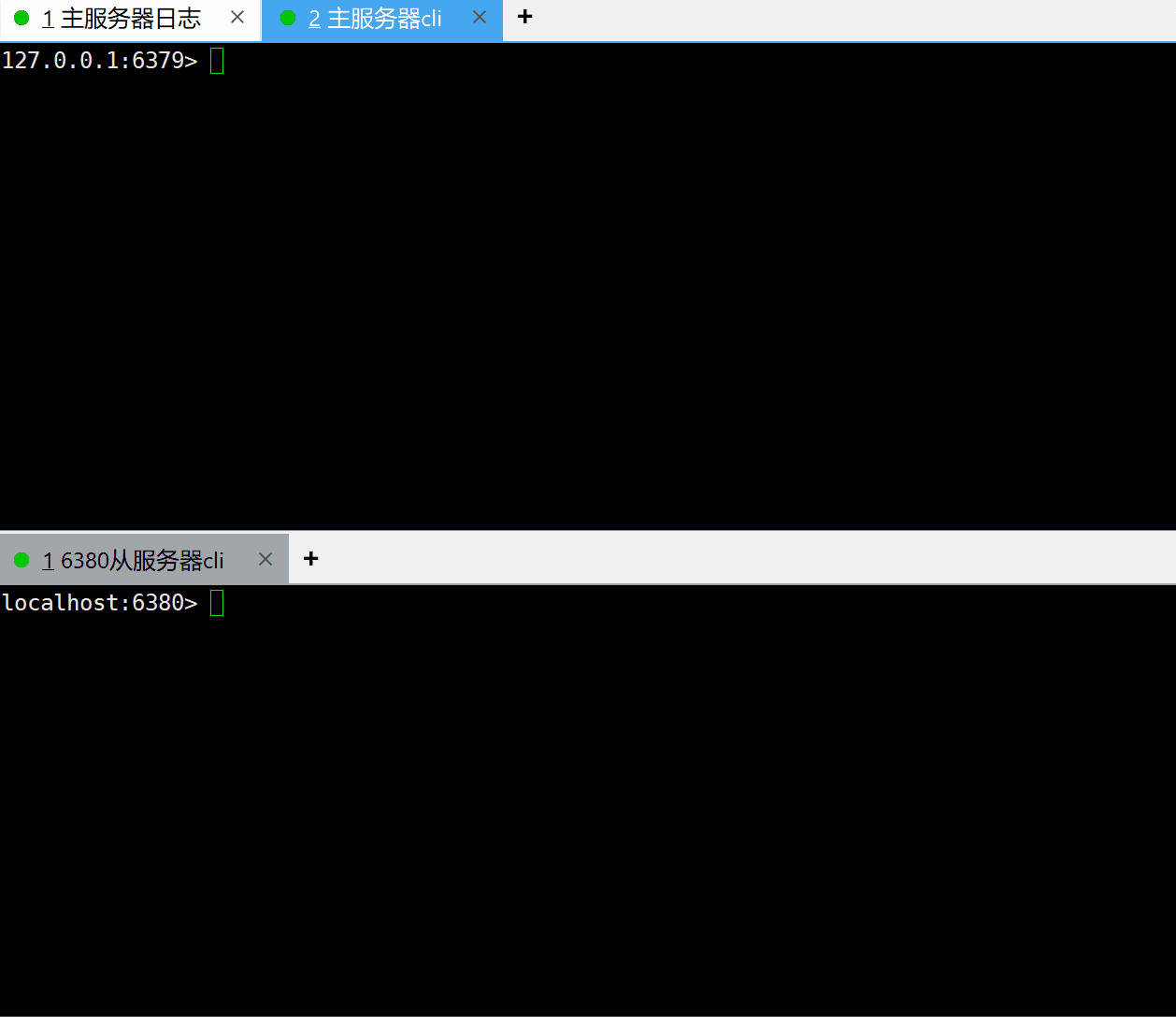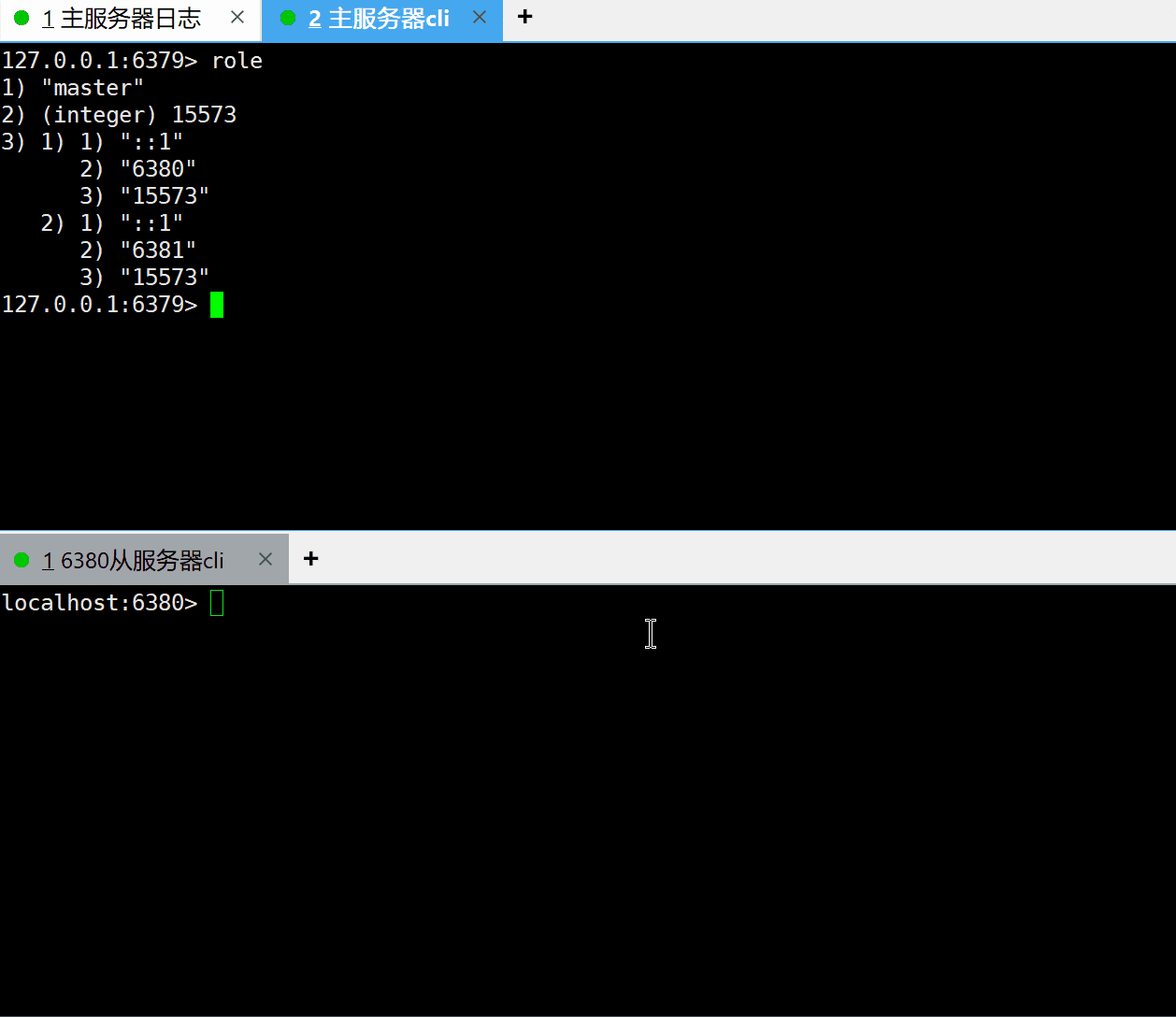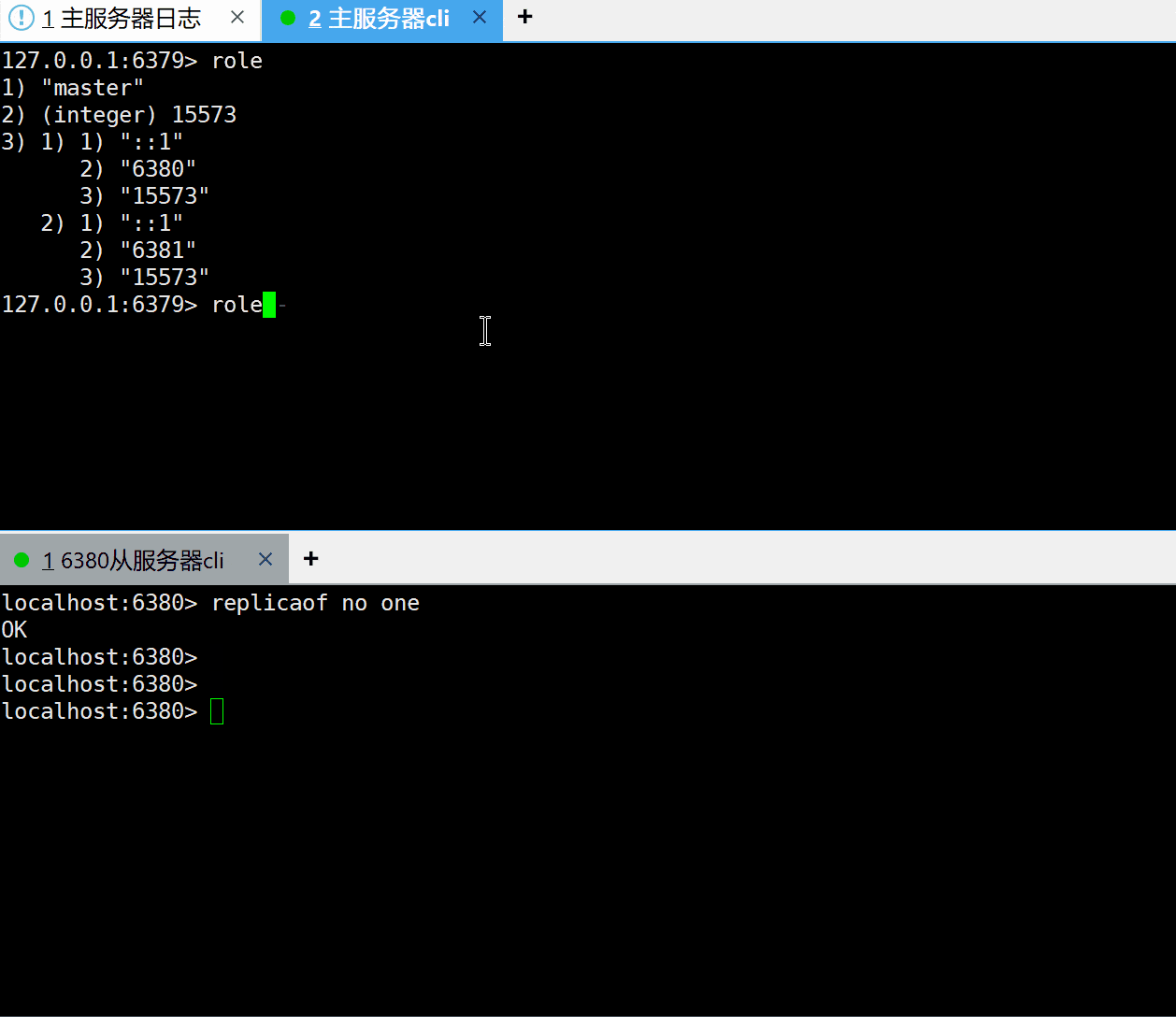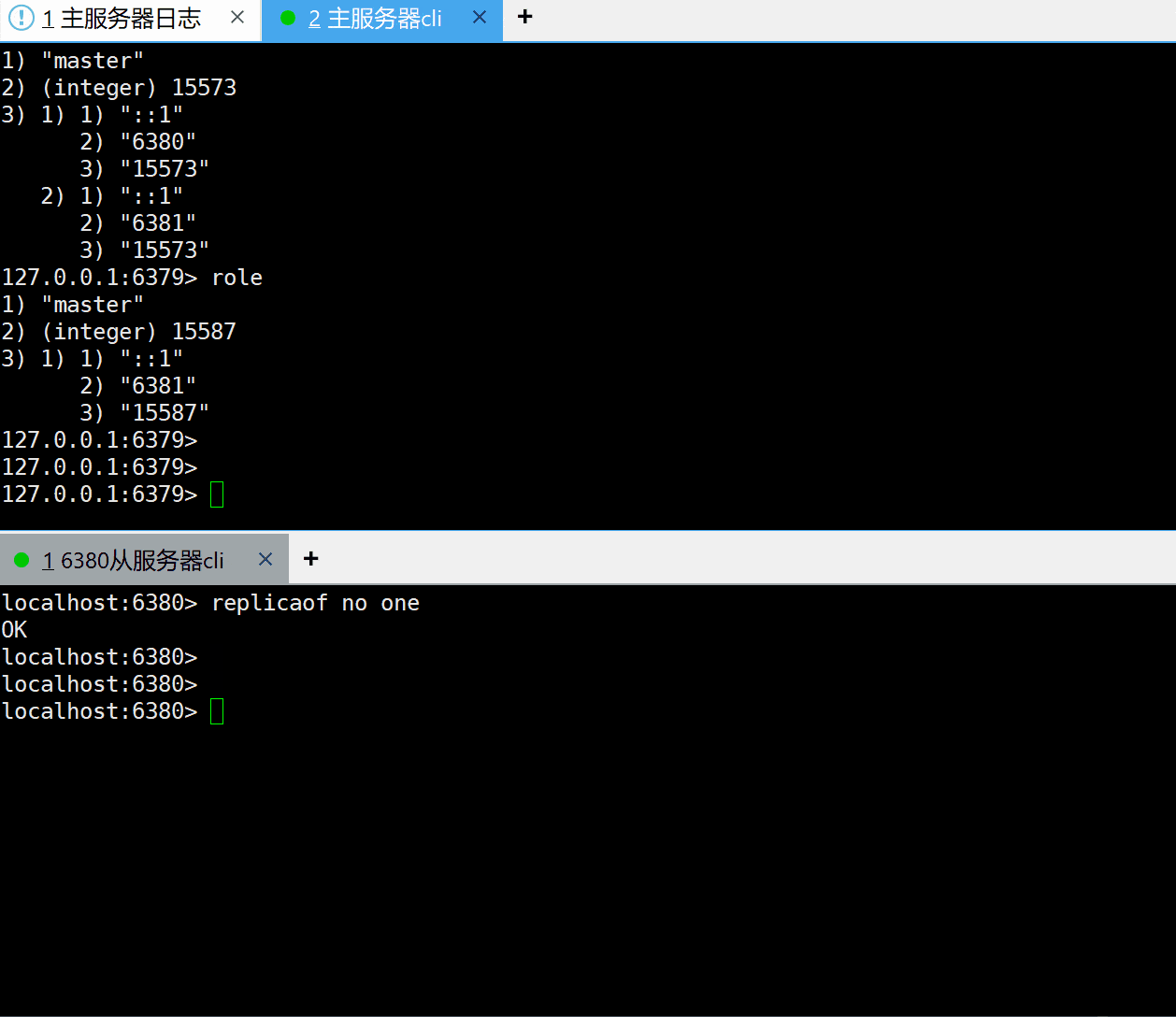
role:查看服务器角色
用户可以通过执行role命令查看服务的当前角色。
主服务器执行role命令:
127.0.0.1:6379> role
1) "master"
2) (integer) 12577
3) 1) 1) "::1"
2) "6380"
3) "12563"
2) 1) "::1"
2) "6381"
3) "12577"
127.0.0.1:6379>
- 第一个元素master表示是主服务器角色
- 第二个元素12577是复制偏移量(replication offset),它是一个整数,记录了主服务器目前向复制数据流发送的数据数量
- 第三个元素是一个数组,表示主服务器属下的从服务器。每个元素都由三个子元素组成:
- 第1个子元素为从服务器的IP地址
- 第2个子元素为从服务器的端口号
- 第3个子元素则为从服务器的复制偏移量。从服务器的复制偏移量记录了从服务器通过复制数据流接收到的复制数据数量,当从服务器的复制偏移量与主服务器的复制偏移量保持一致时,它们的数据就是一致的。在这个例子中并不一致,这是正常的,因为从服务器发送数据给从服务器,从服务器需要时间同步,再者也存在网络延迟。
从服务器执行role命令:
localhost:6381> role
1) "slave"
2) "localhost"
3) (integer) 6379
4) "connected"
5) (integer) 13095
-
数组的第1个元素是字符串"slave",它表示这个服务器的角色是从服务器。
-
数组的第2个元素和第3个元素记录了这个从服务器正在复制的主服务器的IP地址和端口号。
-
数组的第4个元素是主服务器与从服务器当前的连接状态,这个状态的值及其表示的意义如下:
- "none":主从服务器尚未建立连接。
- "connect":主从服务器正在握手。
- "connecting":主从服务器成功建立了连接。
- "sync":主从服务器正在进行数据同步。
- "connected":主从服务器已经进入在线更新状态。
- "unknown":主从服务器连接状态未知。
-
数组的第5个元素是从服务器当前的复制偏移量。
info replication
在之前的文章Redis(一):Redis数据类型和常用命令 介绍过info命令,其中info命令有个子命令info replication可以查看主从复制信息,包括角色(master/slave)、从节点列表、复制偏移量、延迟等。
在主服务器上执行info replication命令:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=::1,port=6380,state=online,offset=14201,lag=1
slave1:ip=::1,port=6381,state=online,offset=14201,lag=1
master_failover_state:no-failover
master_replid:63830caba228eb487be0aaaf561cee0258e21c3e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14201
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14201
从该输出上可以看出该节点的角色信息、从节点数量以及从节点的ip和端口号、状态、延迟等信息。
在从服务器上执行info replication命令:
localhost:6381> info replication
# Replication
role:slave
master_host:localhost
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:14901
slave_priority:100
slave_read_only:1
connected_slaves:0
master_failover_state:no-failover
master_replid:63830caba228eb487be0aaaf561cee0258e21c3e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14901
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:10235
repl_backlog_histlen:4667
replicaof no one
replicaof no one 在从服务器上执行之后,会将从服务器停止复制,并变回主服务器。
二、数据同步机制
当用户将一个服务器设置为从服务器,让它去复制另一个服务器的时候,主从服务器需要通过数据同步机制来让两个服务器的数据库状态保持一致。
1、完整同步
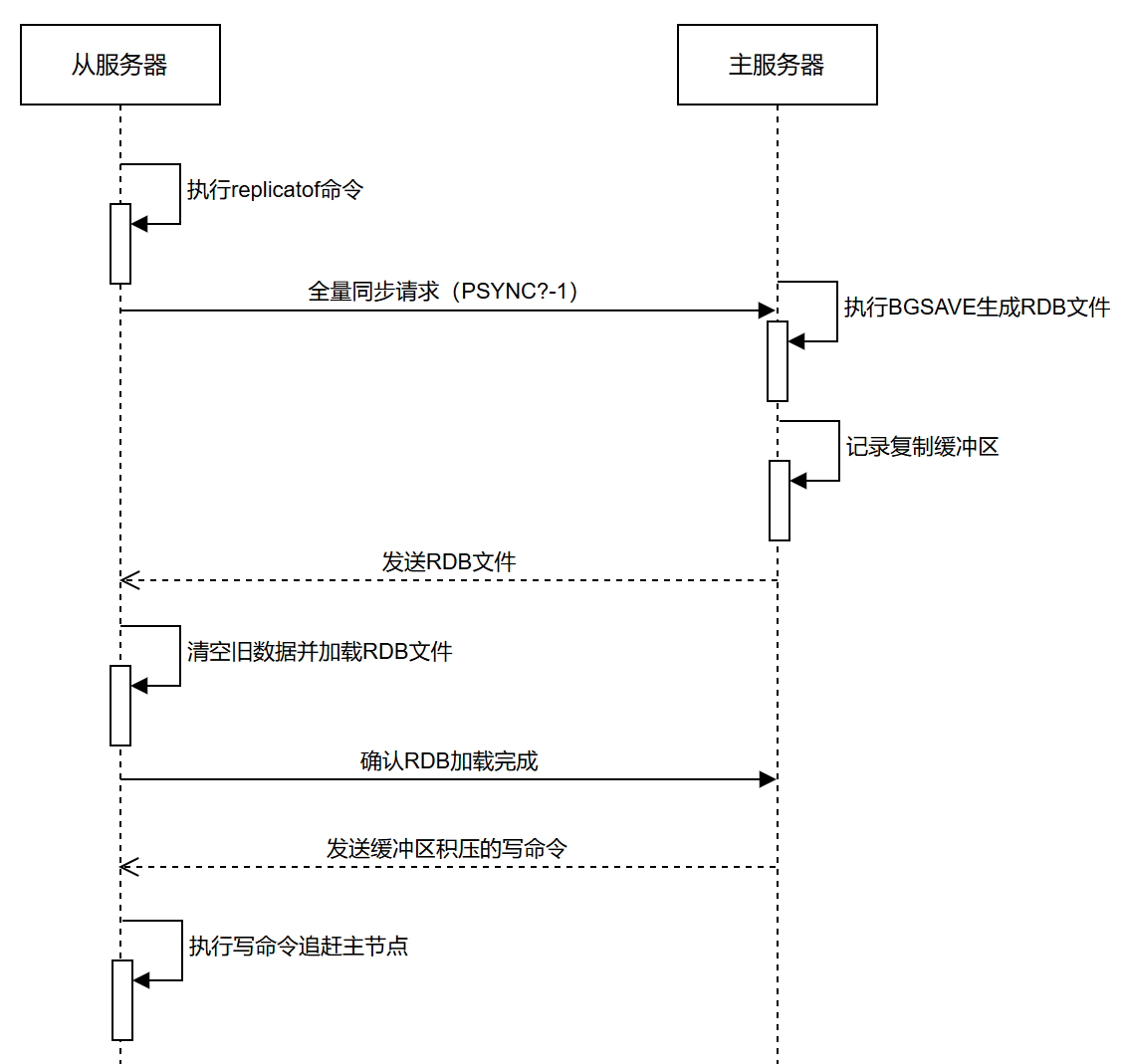
当一个Redis服务器接收到REPLICAOF命令,开始对另一个服务器进行复制的时候,主从服务器会执行以下操作:
-
主服务器执行BGSAVE命令,生成一个RDB文件,并使用缓冲区存储起在BGSAVE命令之后执行的所有写命令。
-
当RDB文件创建完毕,主服务器会通过套接字将RDB文件传送给从服务器。
-
从服务器在接收完主服务器传送过来的RDB文件之后,就会载入这个RDB文件,从而获得主服务器在执行BGSAVE命令时的所有数据。
-
当从服务器完成RDB文件载入操作,并开始上线接受命令请求时,主服务器就会把之前存储在缓存区中的所有写命令发送给从服务器执行。
因为主服务器存储的写命令都是在执行BGSAVE命令之后执行的,所以当从服务器载入完RDB文件,并执行完主服务器存储在缓冲区中的所有写命令之后,主从服务器包含的数据库数据将完全相同。
这个通过创建、传送并载入RDB文件来达成数据一致的步骤,我们称之为完整同步操作。每个从服务器在刚开始进行复制的时候,都需要与主服务器进行一次完整同步。
完整流程图如下所示:
2、部分同步
主从服务器在执行完完整同步操作之后,它们的数据就达到了一致状态,但这种一致并不是永久的:每当主服务器执行了新的写命令之后,它的数据库就会被改变,这时主从服务器的数据一致性就会被破坏。
为了让主从服务器的数据一致性可以保持下去,让它们一直拥有相同的数据,Redis会对从服务器进行在线更新:每当主服务器执行完一个写命令之后,它就会将相同的写命令或者具有相同效果的写命令发送给从服务器执行。
只要从服务器一直与主服务器保持连接,在线更新操作就会不断进行,使得从服务器的数据库可以一直被更新,并与主服务器的数据库保持一致。
数据一致性问题
每当主服务器执行完一个写命令之后,它就会将相同的写命令或者具有相同效果的写命令发送给从服务器执行以保持主从数据的一致性。但是由于网络延迟以及数据处理需要时间,在主服务器执行完写命令之后,直到从服务器也执行完相同写命令的这段时间里,主从服务器的数据库将出现短暂的不一致。
此外,主服务器也可能因故障下线,这时候可能还没来得及将同步命令发送出去,这同样可能会导致出现主从数据不一致的情况。
可以看到,数据一致性问题在主从复制模式中是没有办法杜绝的,对于数据一致性要求比较高的场景,最好直接读主服务器。
redis提供了两个参数设置,可以尽可能的降低出现数据不一致情况发生的概率:min-replicas-to-write、min-replicas-max-lag。
min-replicas-to-write 和 min-replicas-max-lag 搭配使用可以实现主节点写入熔断,确保数据同步的可靠性。
min-replicas-to-write
- 作用:定义主节点(master)在执行写操作时,要求至少连接的从节点(replica)数量。如果当前连接的从节点数少于该值,主节点会拒绝写请求。
- 应用场景:例如,设置为
3时,主节点会检查是否有至少3个从节点处于正常连接状态。若不满足条件,写操作将被拒绝,从而避免数据写入后无法同步到足够多的从节点,降低数据丢失风险 - 默认值:未显式配置时,主节点不会检查从节点数量,可能导致数据不一致。
min-replicas-max-lag
- 作用:设置从节点与主节点之间的最大复制延迟(秒数)。若从节点的延迟超过该阈值,主节点会将其视为“不可用”。
- 应用场景:例如,设置为
10时,主节点会检查所有从节点的复制延迟是否在10秒内。若延迟超过10秒的从节点数量不满足min-replicas-to-write的要求,主节点同样会拒绝写请求 - 默认值:未配置时,主节点不会检查延迟
这两个参数通常配合使用,主要解决以下问题:
- 异步复制的数据丢失:Redis默认异步复制,主节点不会等待从节点确认写操作。通过这两个参数,可以确保写入时至少有N个从节点处于低延迟状态,提高数据可靠性
- 脑裂问题:当网络分区导致主节点与部分从节点断开时,旧主节点可能继续接收写请求,但新主节点已被选举。通过限制写条件,旧主节点会因不满足从节点数量或延迟要求而拒绝写入,减少数据不一致
比如以下配置:
min-replicas-to-write 2
min-replicas-max-lag 10
表示:至少需要2个从节点连接且延迟不超过10秒,主节点才允许写入。
从节点重连
在主从复制模式中,如果从节点突然挂掉了,在挂掉的期间主节点还做了很多写操作,从节点重新上线后会发生什么?
当一个Redis服务器成为另一个服务器的主服务器时,它会把每个被执行的写命令都记录到一个特定长度的先进先出队列(复制积压缓冲区)中。当断线的从服务器尝试重新连接主服务器的时候,主服务器将检查从服务器断线期间,被执行的那些写命令是否仍然保存在队列里面。如果是,那么主服务器就会直接把从服务器缺失的那些写命令发送给从服务器执行,从服务器通过执行这些写命令就可以重新与主服务器保持一致,这样就避免了重新进行完整同步的麻烦。
现在模拟下这个过程,已知现在的架构如下所示:
我现在模拟这个过程,将6380从节点使用shutdown命令退出redis进程,之后6379服务执行一个写命令,看看6380服务重新上线之后会发生什么。
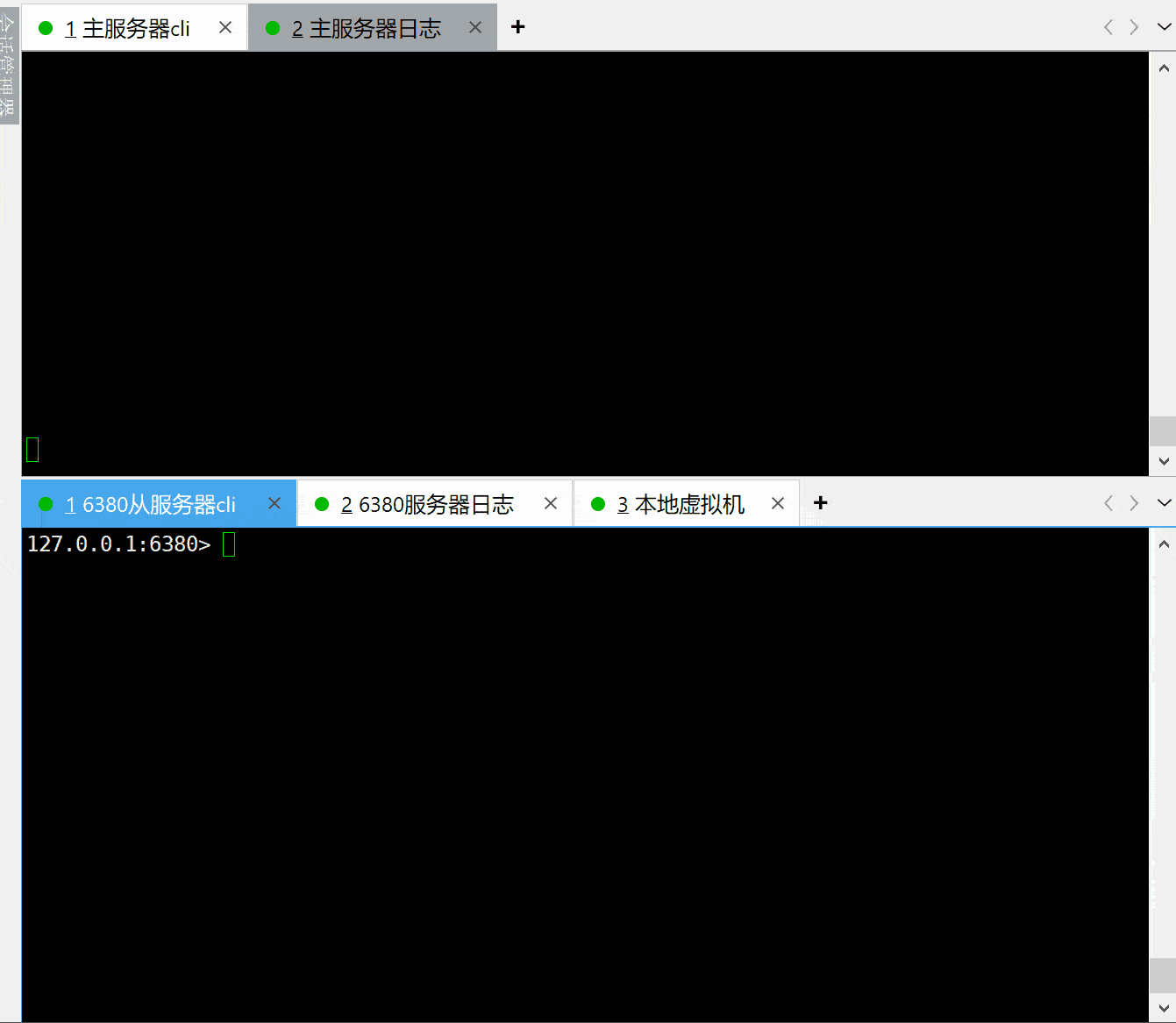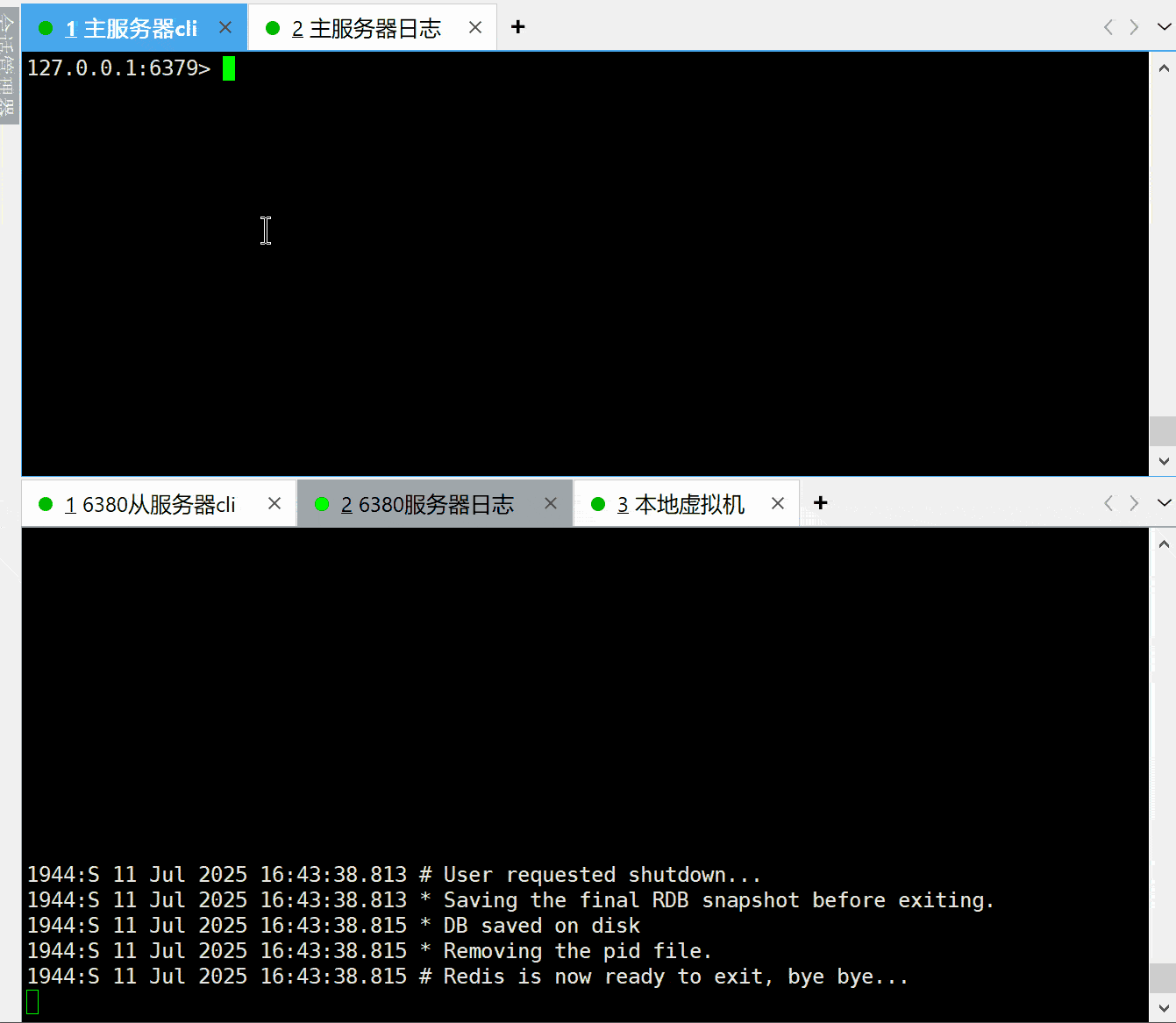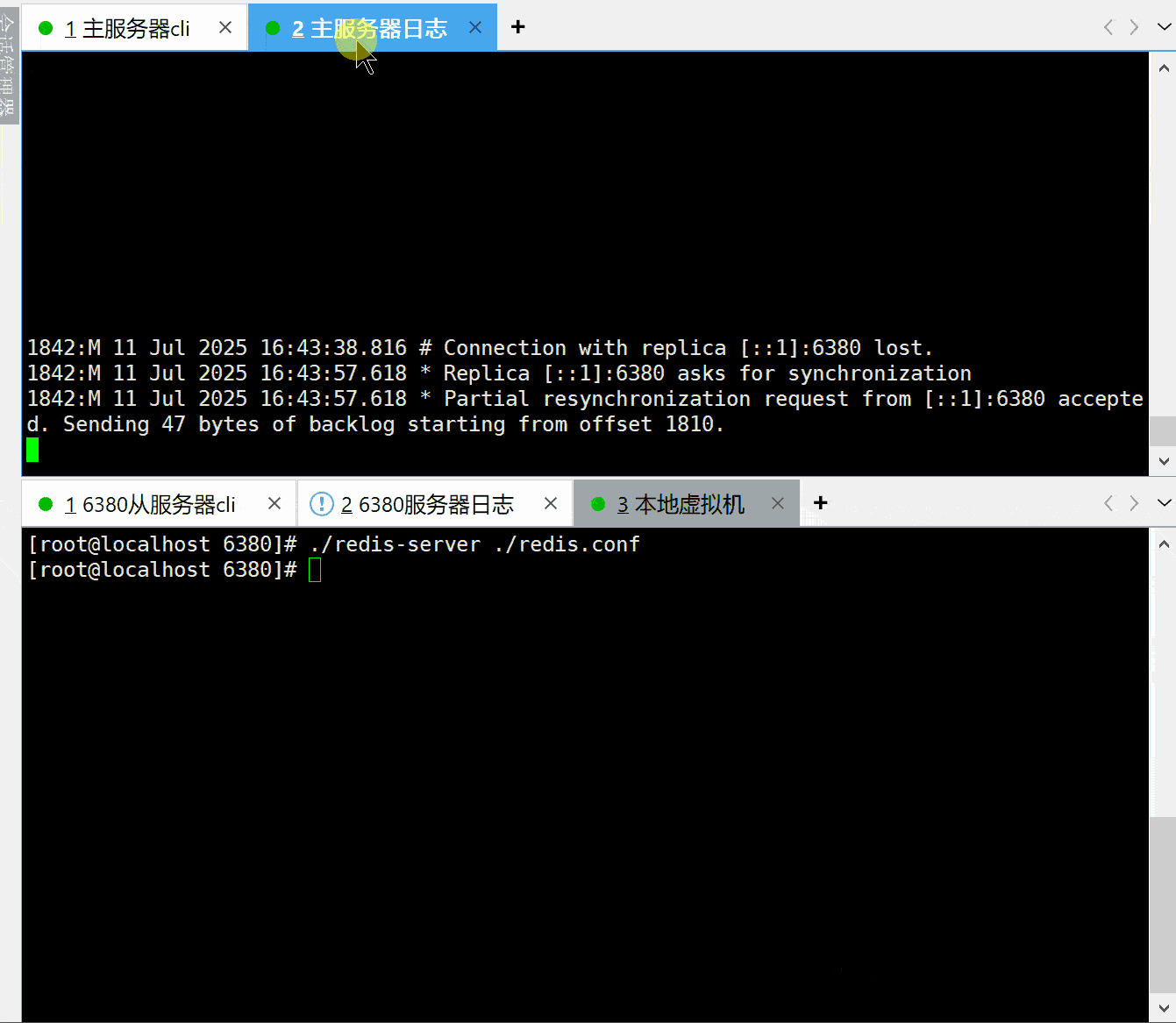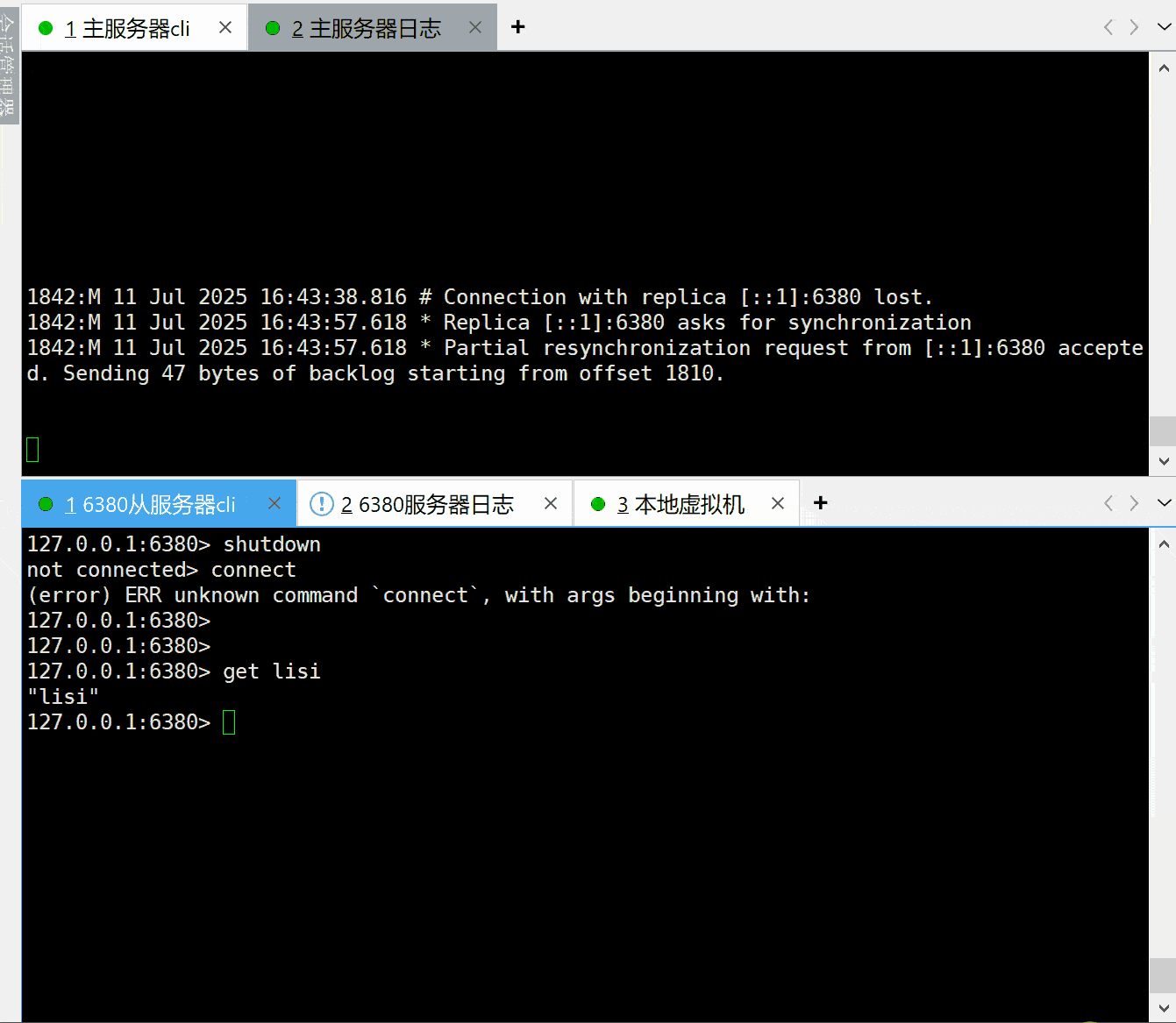
主服务的日志:
1842:M 11 Jul 2025 16:43:38.816 # Connection with replica [::1]:6380 lost.
1842:M 11 Jul 2025 16:43:57.618 * Replica [::1]:6380 asks for synchronization
1842:M 11 Jul 2025 16:43:57.618 * Partial resynchronization request from [::1]:6380 accepted. Sending 47 bytes of backlog starting from offset 1810.
从服务的日志:
1951:S 11 Jul 2025 16:43:57.616 * Loading RDB produced by version 6.2.1
1951:S 11 Jul 2025 16:43:57.616 * RDB age 19 seconds
1951:S 11 Jul 2025 16:43:57.617 * RDB memory usage when created 1.85 Mb
1951:S 11 Jul 2025 16:43:57.617 * DB loaded from disk: 0.001 seconds
1951:S 11 Jul 2025 16:43:57.617 * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
1951:S 11 Jul 2025 16:43:57.617 * Ready to accept connections
1951:S 11 Jul 2025 16:43:57.617 * Connecting to MASTER localhost:6379
1951:S 11 Jul 2025 16:43:57.618 * MASTER <-> REPLICA sync started
1951:S 11 Jul 2025 16:43:57.618 * Non blocking connect for SYNC fired the event.
1951:S 11 Jul 2025 16:43:57.618 * Master replied to PING, replication can continue...
1951:S 11 Jul 2025 16:43:57.618 * Trying a partial resynchronization (request 6cb93c7859fe76e9e1e334fe799eda6fdb55fffc:1810).
1951:S 11 Jul 2025 16:43:57.619 * Successful partial resynchronization with master.
1951:S 11 Jul 2025 16:43:57.619 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
从节点服务重启的时候先从本地加载RDB文件恢复之前的数据,连接主服务器成功以后尝试发起部分同步请求,主服务器接受了部分同步请求发送从服务器断线以后丢失的命令数据,从服务器最终同步成功。
3、复制积压缓冲区
上面的部分同步功能很依赖于主服务器的复制积压缓冲区,复制积压缓冲区越大,意味着从节点可以离线的时间越长。复制积压缓冲区的设置可以在主服务器的redis.conf配置文件中设置:
repl-backlog-size 1mb
repl-backlog-ttl 3600
repl-backlog-size
设置复制积压缓冲区的大小。积压缓冲区是一个缓存区,用于在从节点(replica)因某些原因断开连接时累积主节点的数据。这样,当从节点重新连接时,通常不需要执行完整的全量同步(full resync),而只需通过部分同步(partial resync)传递从节点在断开期间缺失的数据部分。
复制积压缓冲区越大,从节点能容忍的断开时间越长,后续也更可能通过部分同步恢复数据。
该缓冲区仅在至少有一个从节点连接时才会分配内存空间,默认值是1Mb。
repl-backlog-ttl
当主节点(master)在一段时间内没有任何连接的从节点(replica)时,积压缓冲区(backlog)将被释放。该配置项用于设定从最后一个从节点断开连接开始,经过多少秒后积压缓冲区会被自动释放。
注意:从节点(replica)永远不会因超时而释放积压缓冲区,因为它们后续可能被提升为主节点,必须确保能够与其他从节点正确进行“部分重新同步”(partial resynchronization)。因此,从节点会始终保留积压缓冲区。
值为0表示永不释放积压缓冲区。
默认值:3600(即缓冲区在最后一个从节点断开后1小时释放)
4、无需硬盘的复制
主服务器在进行完整同步的时候,需要在本地创建RDB文件,然后通过套接字将这个RDB文件传送给从服务器。但是,如果主服务器所在宿主机器的硬盘负载非常大或者性能不佳,那么创建RDB文件引起的大量硬盘写入将对主服务器的性能造成影响,并导致复制进程变慢。
为了解决这个问题,Redis从2.8.18版本开始引入无须硬盘的复制特性(diskless replication):启用了这个特性的主服务器在接收到REPLICAOF命令时将不会再在本地创建RDB文件,而是会派生出一个子进程,然后由子进程通过套接字直接将RDB文件写入从服务器。这样主服务器就可以在不创建RDB文件的情况下,完成与从服务器的数据同步。
要使用无须硬盘的复制特性,可以使用如下配置
repl-diskless-sync no #核心配置
repl-diskless-sync-delay 5
repl-diskless-load disabled
repl-diskless-sync
该配置项的值为no时使用rdb传输,为yes时使用无盘传输。
该配置项为节点,如果无法通过增量同步继续复制过程,则需要执行全量同步(full synchronization)。此时,主节点会生成RDB文件并传输给从节点。
RDB文件的传输可通过两种方式实现:
- 磁盘备份模式(Disk-backed)
- 主节点创建一个子进程,将RDB文件写入磁盘。
- 父进程随后将磁盘中的RDB文件增量传输给从节点。
- 无盘模式(Diskless):
- 主节点创建一个子进程,直接通过套接字(socket)将RDB文件流式传输给从节点,完全不经过磁盘。
两种模式的差异:
- 磁盘备份模式:生成RDB文件期间,新连接的从节点会排队等待,当前子进程完成后即可共享同一RDB文件。
- 无盘模式:传输一旦开始,新到达的从节点需等待当前传输完成后才能启动新一轮传输。
无盘模式的延迟配置:
启用无盘复制时,主节点会等待一段可配置的时间(秒),以期望更多从节点加入,从而实现并行传输(默认值:repl-diskless-sync-delay 5)。
适用场景:在磁盘性能较差但网络带宽较高的环境下,无盘复制的性能更优。
repl-diskless-sync-delay
该配置项的值为整数,单位秒,表示当启用无盘复制(diskless replication)时,主节点在启动RDB传输子进程前等待的延迟时间(单位为秒)。这一延迟的目的是让更多从节点能够加入当前的同步批次,从而避免重复生成RDB文件。
重要性:一旦RDB传输开始,新连接的从节点将无法立即加入同步,只能排队等待下一次RDB传输。因此,主节点通过延迟等待,尽可能让更多从节点在同一批次完成同步。
默认值:5秒。若设置为0秒,则主节点会立即开始传输RDB,不等待任何从节点加入。
repl-diskless-load
该配置项用于从服务器节点RDB误判加载功能的开启。它有三种值:
disabled:禁用无盘加载,优先将RDB写入磁盘再加载(默认安全选项)。on-empty-db:仅在数据库为空时启用无盘加载(完全安全时使用)。swapdb:解析套接字数据时,在内存中保留当前数据库的副本。需确保内存充足,否则可能触发OOM。
我们知道使用repl-diskless-sync配置项可以让主服务器实现无盘复制,但是从服务器默认还是需要先下载rdb文件再从rdb文件恢复数据的。repl-diskless-load配置项则可以让从服务器节点实现无盘加载,即从从服务器获取到rdb文件后不下载到本地,直接从内存恢复数据。
注意:RDB无盘加载是实验性功能。 在此配置下,从节点(replica)不会立即将RDB文件存储到磁盘,可能导致故障转移期间的数据丢失。此外,若Redis模块未处理I/O读取,在与主节点初始同步阶段出现I/O错误时,Redis可能会中止。如果能接受该风险,就可以使用该项功能。
优劣分析:
- 无盘加载的优势: 磁盘速度通常低于网络,存储和加载RDB文件可能增加复制时间(甚至增加主节点的写时复制内存和从节点缓冲区压力)。
- 无盘加载的风险: 直接从套接字解析RDB文件时,可能需要在完整接收RDB前清空当前数据库内容,导致数据不一致或内存不足(OOM)。
三、可写的从服务器
从Redis 2.6版本开始,Redis的从服务器在默认状态下只允许执行读命令。如果用户尝试对一个只读从服务器执行写命令,那么服务器将拒绝写入。

Redis之所以将从服务器默认设置为只读服务器,是为了确保从服务器只能通过与主服务器进行数据同步来得到更新,从而保证主从服务器之间的数据一致性。
但在某些情况下,我们可能想要将一些不太重要或者临时性的数据存储在从服务器中,或者不得不在从服务器中执行一些带有写性质的命令(比如ZINTERSTORE命令,它只能将计算结果存储在数据库中,不能直接返回计算结果)。这时我们可以通过将replica-read-only配置选项的值设置为no来打开从服务器的写功能:
replica-read-only <yes|no>
注意该配置是作用在从服务器上的。
使用从服务器写功能可能会导致和主服务器写的key冲突,这点需要注意,在从服务器上写入key时尽量设置ttl从而保证和主服务器的数据一致性。
注意:本文归作者所有,未经作者允许,不得转载