明明标题全字段匹配,但是按照默认的相关度排序却排到了第三四位,第一位怎么看都不应该排在最上面。。今天ES文章检索我遇到了这个问题。
我对文章的title和content字段使用了多字段查询,一开始我认为是content字段干扰了整体的相关度,后来使用boost字段加大了title的查询权重,结果还是一样的;后来单独查询title字段还是一样的结果,全匹配字段还是排在了下面,这不禁让我怀疑起了人生。
百度下,随便点着点着就点到了官网上的一篇文章:被破坏的相关度 ,全文如下
在讨论更复杂的 多字段搜索 之前,让我们先快速解释一下为什么只在主分片上 创建测试索引 。
用户会时不时的抱怨无法按相关度排序并提供简短的重现步骤:用户索引了一些文档,运行一个简单的查询,然后发现明显低相关度的结果出现在高相关度结果之上。
为了理解为什么会这样,可以设想,我们在两个主分片上创建了索引和总共 10 个文档,其中 6 个文档有单词
foo。可能是分片 1 有其中 3 个foo文档,而分片 2 有其中另外 3 个文档,换句话说,所有文档是均匀分布存储的。在 什么是相关度?中,我们描述了 Elasticsearch 默认使用的相似度算法,这个算法叫做 词频/逆向文档频率 或 TF/IDF 。词频是计算某个词在当前被查询文档里某个字段中出现的频率,出现的频率越高,文档越相关。 逆向文档频率 将 某个词在索引内所有文档出现的百分数 考虑在内,出现的频率越高,它的权重就越低。
但是由于性能原因, Elasticsearch 不会计算索引内所有文档的 IDF 。相反,每个分片会根据 该分片 内的所有文档计算一个本地 IDF 。
因为文档是均匀分布存储的,两个分片的 IDF 是相同的。相反,设想如果有 5 个
foo文档存于分片 1 ,而第 6 个文档存于分片 2 ,在这种场景下,foo在一个分片里非常普通(所以不那么重要),但是在另一个分片里非常出现很少(所以会显得更重要)。这些 IDF 之间的差异会导致不正确的结果。在实际应用中,这并不是一个问题,本地和全局的 IDF 的差异会随着索引里文档数的增多渐渐消失,在真实世界的数据量下,局部的 IDF 会被迅速均化,所以上述问题并不是相关度被破坏所导致的,而是由于数据太少。
为了测试,我们可以通过两种方式解决这个问题。第一种是只在主分片上创建索引,正如
match查询 里介绍的那样,如果只有一个分片,那么本地的 IDF 就是 全局的 IDF。第二个方式就是在搜索请求后添加
?search_type=dfs_query_then_fetch,dfs是指 分布式频率搜索(Distributed Frequency Search) , 它告诉 Elasticsearch ,先分别获得每个分片本地的 IDF ,然后根据结果再计算整个索引的全局 IDF 。不要在生产环境上使用
dfs_query_then_fetch。完全没有必要。只要有足够的数据就能保证词频是均匀分布的。没有理由给每个查询额外加上 DFS 这步。
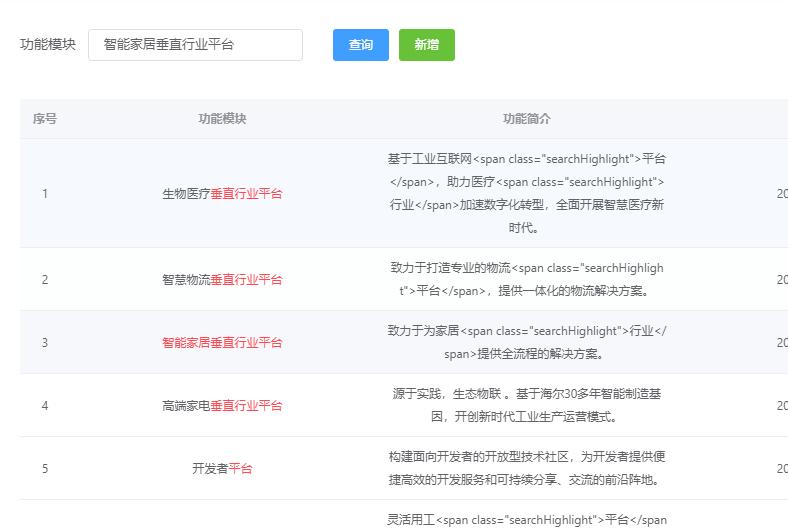
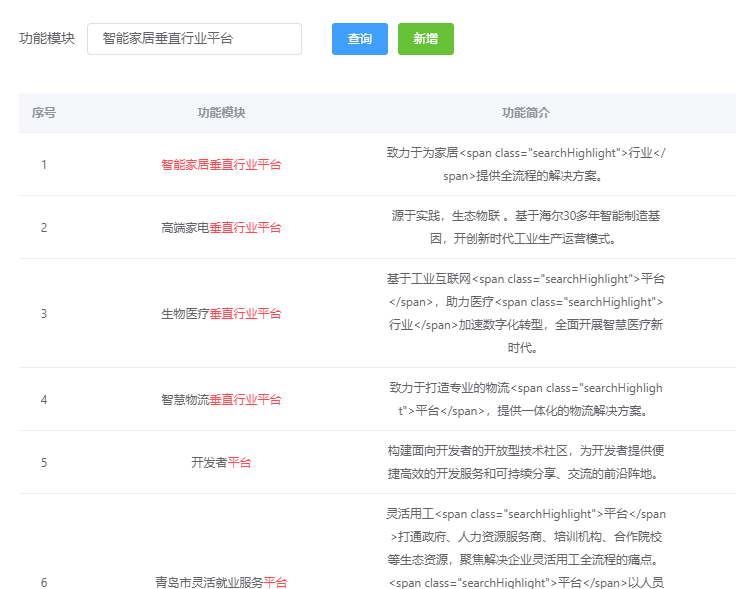
看完全文,似懂非懂,能明白大概是分片导致的,有一句话很重要:如果只有一个分片,那么本地的 IDF 就是 全局的 IDF。
我的索引分了5片,如果只是分了一片的话,是不是就能解决问题了?
首先,删除索引
DELETE {{es-host}}/cosmo_qdlind_top_search
然后重建索引
PUT {{es-host}}/cosmo_qdlind_top_search
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"max_result_window": 1000000
}
}
在这里把分片和副本数量都设置为1(原来我的分片数量是5)。
然后重建mapping,最后重新导入数据,测试结果就正常了
注意:本文归作者所有,未经作者允许,不得转载