说起来方法特别简单,那就是在相应的字段加上@JsonProperty注解。。。当然,这种方法只是适用于一般场景,有其局限性:加上这个注解之后序列化和反序列化都会使用这个注解,不够灵活。
我的使用场景是这样子的:同样一个model,在正常业务使用的时候就用其字段属性名,但是在特殊场景下(我的是发送kafka日志)需要序列化成某个特殊的key值。
举个例子,我有个服务对接了好多个外部系统,我会将其外部系统的数据拉下来使用,但是他们给我的数据格式不统一,同样是手机号,有mobile、phone、telePhone等不同的名字,我在推数给数据中台的时候,数据中台希望名字能保持统一,手机号就叫mobile,但是在其它场景下都要保持原先的功能不变。
这里可以使用PropertyNamingStrategy.PropertyNamingStrategyBase来解决问题。
1. 首先定义一个注解,就叫做Mobile
/**
* @author kdyzm
* @date 2021/11/11
*/
@Target({ElementType.FIELD, ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Mobile {
String value() default KafkaLogFileds.MOBILE;
}
/**
* 和kafka约定的日志字段
*
* @author kdyzm
* @date 2021/11/11
*/
public class KafkaLogFileds {
/**
* 手机号
*/
public static final String MOBILE = "mobile";
/**
* 身份证号
*/
public static final String IDCARD = "idcard";
/**
* 统一社会信用代码
*/
public static final String UNISCID = "uniscid";
}
2. 将注解加到字段上
/**
* @author kdyzm
* @date 2021/11/15
*/
@Data
public class User {
/**
* 手机号
*/
@Mobile
private String phone;
}
3. 继承PropertyNamingStrategyBase
/**
* @author kdyzm
* @date 2021/11/12
*/
public class KafkaNamingStrategy extends PropertyNamingStrategy.PropertyNamingStrategyBase {
@Override
public String nameForField(MapperConfig<?> config, AnnotatedField field, String defaultName) {
return translate(field, defaultName);
}
@Override
public String translate(String propertyName) {
return propertyName;
}
private String translate(AnnotatedField field, String defaultName) {
int annotationCount = field.getAnnotationCount();
if (annotationCount <= 0) {
return defaultName;
}
return doTranslate(field, defaultName);
}
private String doTranslate(AnnotatedMember field, String defaultName) {
Uniscid uniscid = field.getAnnotation(Uniscid.class);
if (Objects.nonNull(uniscid)) {
return KafkaLogFileds.UNISCID;
}
Mobile mobile = field.getAnnotation(Mobile.class);
if (Objects.nonNull(mobile)) {
return KafkaLogFileds.MOBILE;
}
Idcard idcard = field.getAnnotation(Idcard.class);
if (Objects.nonNull(idcard)) {
return KafkaLogFileds.IDCARD;
}
return defaultName;
}
}
4.单独创建ObjectMapper
/**
* 写kafka专用,序列化的时候要修改某些特殊的值
*/
public static ObjectMapper getKafkaObjectMapper() {
if (Objects.nonNull(kafkaObjectMapper)) {
return kafkaObjectMapper;
}
synchronized (ObjectMapperFactory.class) {
if (Objects.nonNull(kafkaObjectMapper)) {
return kafkaObjectMapper;
}
kafkaObjectMapper = new ObjectMapper();
//添加kafka特殊处理
kafkaObjectMapper.setPropertyNamingStrategy(new KafkaNamingStrategy());
return kafkaObjectMapper;
}
}
一切似乎都没有问题,但是最后测试的时候发现,并没有生效,字段名根本没发生变化。。
5.问题探讨和解决
debug了下,KafkaNamingStrategy类重写的nameForField方法根本没有被调用到。。。debug下,看下源代码实现
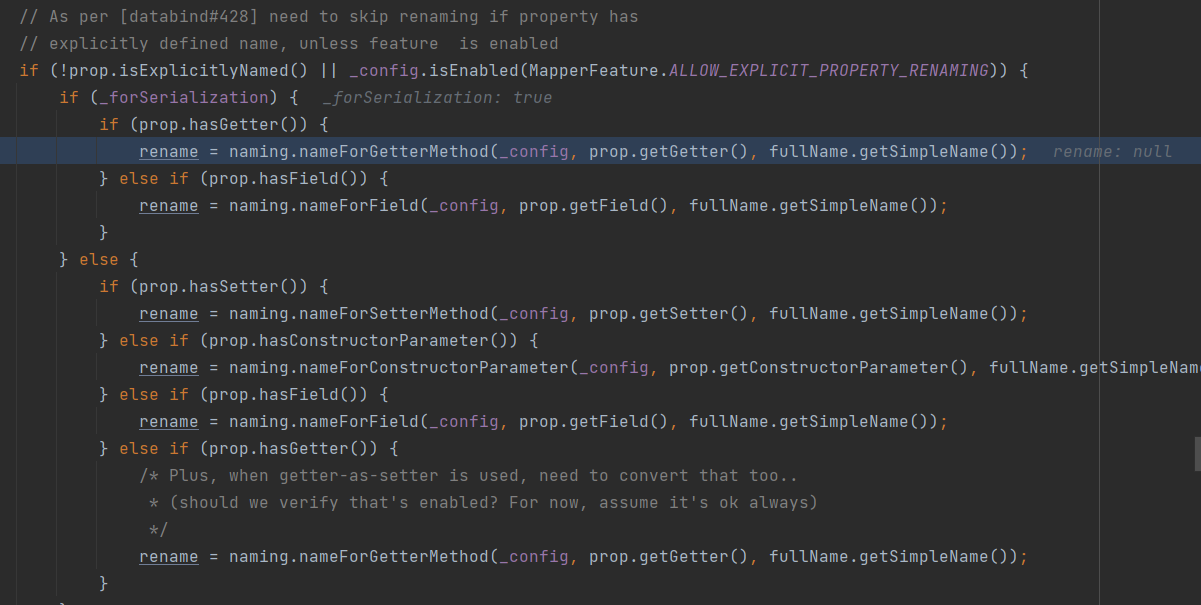
可以看到Getter方法优先级要比Filed方法优先级要高,如果有Getter方法,就会调用nameForGetterMethod方法,PropertyNamingStrategyBase类中已经默认提供了该方法的实现

所以,为了解决问题,很明显要重写nameForGetterMethod方法,OK,那就重写好了
/**
* @author kdyzm
* @date 2021/11/12
*/
public class KafkaNamingStrategy extends PropertyNamingStrategy.PropertyNamingStrategyBase {
@Override
public String nameForField(MapperConfig<?> config, AnnotatedField field, String defaultName) {
return translate(field, defaultName);
}
@Override
public String nameForGetterMethod(MapperConfig<?> config, AnnotatedMethod method, String defaultName) {
return translate(method, defaultName);
}
@Override
public String translate(String propertyName) {
return propertyName;
}
private String translate(AnnotatedField field, String defaultName) {
int annotationCount = field.getAnnotationCount();
if (annotationCount <= 0) {
return defaultName;
}
return doTranslate(field, defaultName);
}
private String translate(AnnotatedWithParams field, String defaultName) {
int annotationCount = field.getAnnotationCount();
if (annotationCount <= 0) {
return defaultName;
}
return doTranslate(field, defaultName);
}
private String doTranslate(AnnotatedMember field, String defaultName) {
Uniscid uniscid = field.getAnnotation(Uniscid.class);
if (Objects.nonNull(uniscid)) {
return KafkaLogFileds.UNISCID;
}
Mobile mobile = field.getAnnotation(Mobile.class);
if (Objects.nonNull(mobile)) {
return KafkaLogFileds.MOBILE;
}
Idcard idcard = field.getAnnotation(Idcard.class);
if (Objects.nonNull(idcard)) {
return KafkaLogFileds.IDCARD;
}
return defaultName;
}
}
重写之后果然好了,但是我的@Mobile注解命名加在字段上的
@Data
public class User {
/**
* 手机号
*/
@Mobile
private String phone;
}
反编译看下字节码文件中如何翻译它的
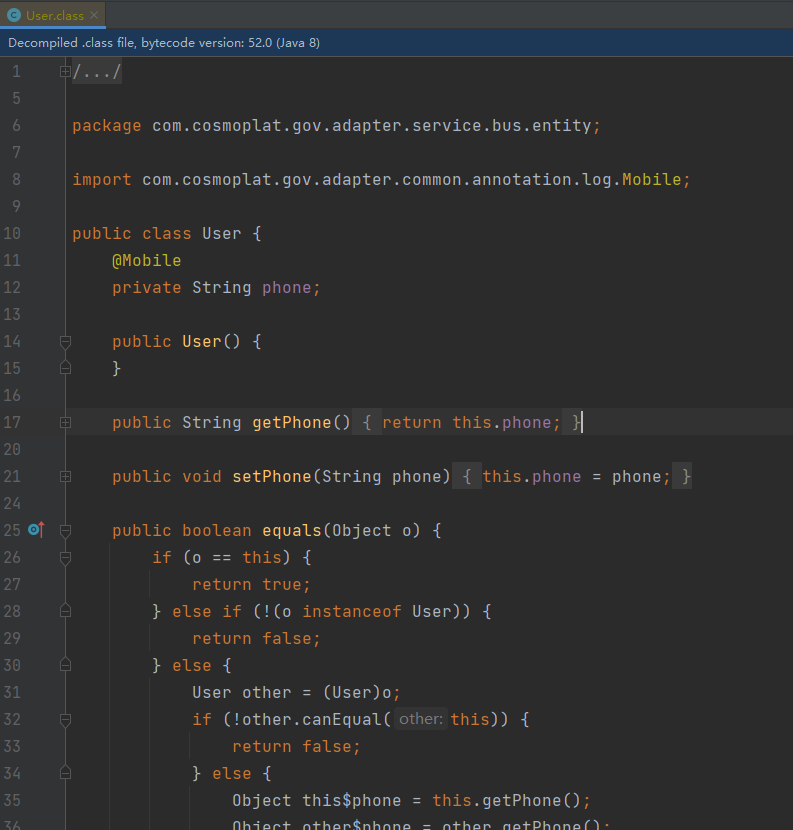
确实没有什么特殊的地方,那么getter方法是如何检测到@Mobile注解的呢。。无法理解
接着上面的问题探讨,经过debug,最终找到了源码对getter方法注解的处理
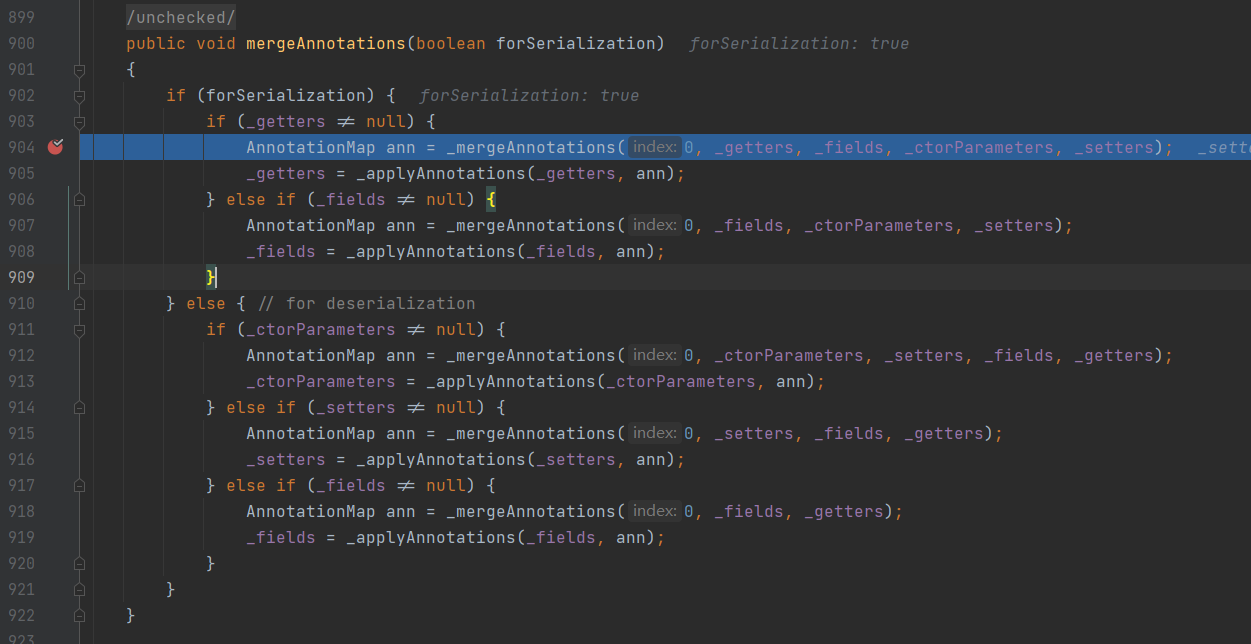
根据这段源码的逻辑,无论是序列化还是反序列化,字段上的注解最终都会合并到getter方法上的注解,其实不止字段上的注解,还有setter方法上的注解、构造方法上的注解,最终都会被合并到getter方法上去,换句话说,如果目标注解的作用点是Getter方法,那么这个注解加到什么位置都是一样的。
根据这段源码梳理下
对于序列化来说
| 作用目标 | 注解可以添加的位置 |
|---|---|
| Getter方法 | Getter方法、字段、构造方法参数(存疑)、Setter方法 |
| 字段 | 字段、构造方法、Setter方法 |
对于反序列化来说
| 作用目标 | 注解可以添加的位置 |
|---|---|
| 构造方法参数(存疑) | Getter方法、字段、构造方法参数(存疑)、Setter方法 |
| Setter方法 | 字段、构造方法、Setter方法 |
| 字段 | 字段、Getter方法 |
注意:本文归作者所有,未经作者允许,不得转载