LongAdder类直译过来名字叫做“原子加法器”,它是JDK1.8才出现的新类,它的作用是替代AtomicLong类在某些并发场景下的使用,使得程序运行效率更高。
在之前的《线程同步机制二:CAS原理和JUC原子类》文章中,已经简单介绍过该类的使用:AtomicLong在争用激烈的场景下,会有大量的CAS空自旋,甚至有的线程会进入一个无限重复的循环中。
LongAdder的原理是是以空间换时间的方式提升高并发场景下CAS操作的性能。
一、LongAdder高效原理
为了比较出LongAdder的先进性,需要回顾下AtomicLong的实现原理,它和AtomicInteger很相似,关于AtomicInteger,可以参考《CAS原子类:AtomicInteger源码解析》,简单来说,AtomicLong就是内部维护了一个long类型的变量,各种add、自增方法都是使用Unsafe类的CAS方法修改它的值。
public final boolean compareAndSet(long expect, long update) {
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
可以预料到的后果是,如果线程比较多,则执行CAS会遇到大量的竞争,会有大量的CAS操作失败,这种情况下AtomicLong效率会很低。
LongAdder为了减少这种竞争,使用了空间换时间的方式提高效率:最理想的情况下,每个线程都操作自己的一个初始值为0的long类型的变量,当最后计算结果值的时候,将所有线程持有的变量累加(LongAdder只会加减法),其结果和多线程操作AtomicLong是一样的。基于这种思路,LongAdder的架构图如下所示
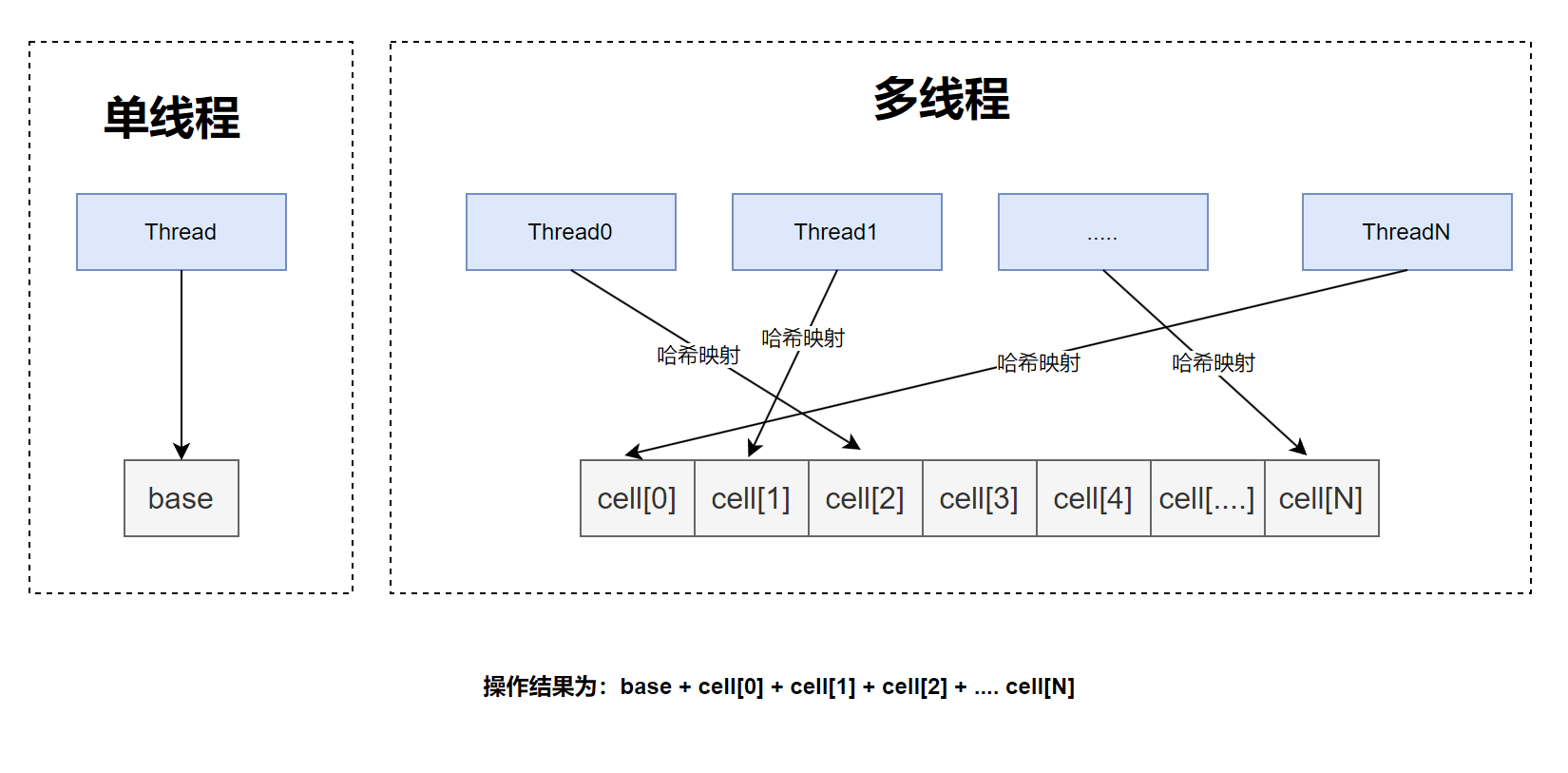
LongAdder内部维护了一个base变量和一个cells[]数组,在无竞争的环境下(上述图中表示的并不准确,但是能为了更加直观,使用了“单线程”和“多线程”的说法),只对base变量进行CAS操作。
在出现竞争之后(即有base变量CAS失败的情况发生了),会初始化cells数组,初始长度为2,之后每个线程会根据自己的线程探针(可以理解为hashCode)映射到数组中的某个元素上,之后线程将只对该元素进行CAS,如果CAS失败,则LongAdder会再重试一次CAS,如果还是失败,最后会尝试对cells数组扩容,每次扩容之后数组的长度为原先的两倍,扩容之后会重试CAS,直到成功。
二、LongAdder源码解析
LongAdder中其实就两个核心方法:add方法和sum方法
| 方法名 | 释义 |
|---|---|
| public void add(long x) | 增加一个数 |
| public long sum() | 计算LongAdder的数值 |
1、add方法
add方法源码如下
/**
* Adds the given value.
*
* @param x the value to add
*/
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
源码虽然比较短,但是似乎有些复杂:在LongAdder相关的源码中,有很多判断条件中都会调用一些方法,再加上赋值操作,结果可能会作为下一个判断条件中的运算条件,这导致代码看起来会比较乱,其实这样做让代码保持简洁的同时还能让它更具有可读性,习惯了就好。
为了方便标记,我将源码中的代码进行格式化,如下
/**
* Adds the given value.
*
* @param x the value to add
*/
public void add(long x) {
Cell[] as;
long b, v;
int m;
Cell a;
if ((as = cells) != null //① 为true表示发生过竞争,走②
|| !casBase(b = base, b + x)) //② 为true表示对base变量CAS操作失败
{
boolean uncontended = true;
if (as == null //③ 为true表示base变量CAS操作失败进来的,说明首次进来,cells数组还未初始化
|| (m = as.length - 1) < 0 //④ 获取掩码m,判断<0则是为了防止⑤出现数组访问异常
|| (a = as[getProbe() & m]) == null //⑤ 计算当前线程对应的Cell数组中的“槽”值并判空
|| !(uncontended = a.cas(v = a.value, v + x)) //⑥ 当前线程对应的Cell数组坐标元素CAS操作
){
//⑦ 执行异常情况下的Cell元素加法操作
longAccumulate(x, null, uncontended);
}
}
}
①(as = cells) != null:判定cells数组是否为空,如果为空,表示已经发生过竞争(单线程或者多线程CAS均成功),不再操作base值,直接操作cells数组。
②!casBase(b = base, b + x):在①条件未满足的情况下,即cells数组为空,表示未发生过竞争,直接对base做CAS操作尝试增加一个数值。
①和②的判定顺序在这里是有意义的,这两个条件判断告诉我们:如果发生过竞争,则会使用cells数组执行自增,不再操作base数值;如果没发生过竞争,则操作base数值进行自增。这正是减少线程竞争的操作。
如果满足①或者②条件,则开始进入下一个if,即 ③ ④ ⑤ ⑥ 的判定条件,这表示要么cells数组不为空,要么cells数组为空,但是base数值的CAS操作失败了(多线程操作产生了竞争)
③as == null:如果为true表示base变量CAS操作失败进来的,说明首次进来,cells数组还未初始化
④(m = as.length - 1) < 0:这里做了两个操作,一个是m=as.length-1这里对m进行了赋值操作;一个是判断了m<0。赋值操作的目的是获取掩码,为可能得后续条件⑤做准备;判断m<0也是,为了防止⑤数组取值抛出数组越界异常。
⑤(a = as[getProbe() & m]) == null:这段代码整体上是个赋值和判断的操作;a赋值为cell数组的某个元素值然后判断a是否是null。关键的是getProbe() & m这个代码,这个代码用于计算cell数组的坐标。getProbe() 方法用于获取当前线程的探针值,相当于“hashCode”,getProbe() & m 的操作将当前线程的探针值与 m 进行按位与操作,这样可以确保结果位于 0 和 m 之间,也就是0和cells.lenth-1之间,确保不会出现数组越界异常。该段代码实际上是获取cells数组中当前线程对应的“槽”值,并判空。
⑥!(uncontended = a.cas(v = a.value, v + x)):对当前线程对应的Cell数组坐标元素CAS操作,并判定是否成功。
综合上述描述,流程图如下
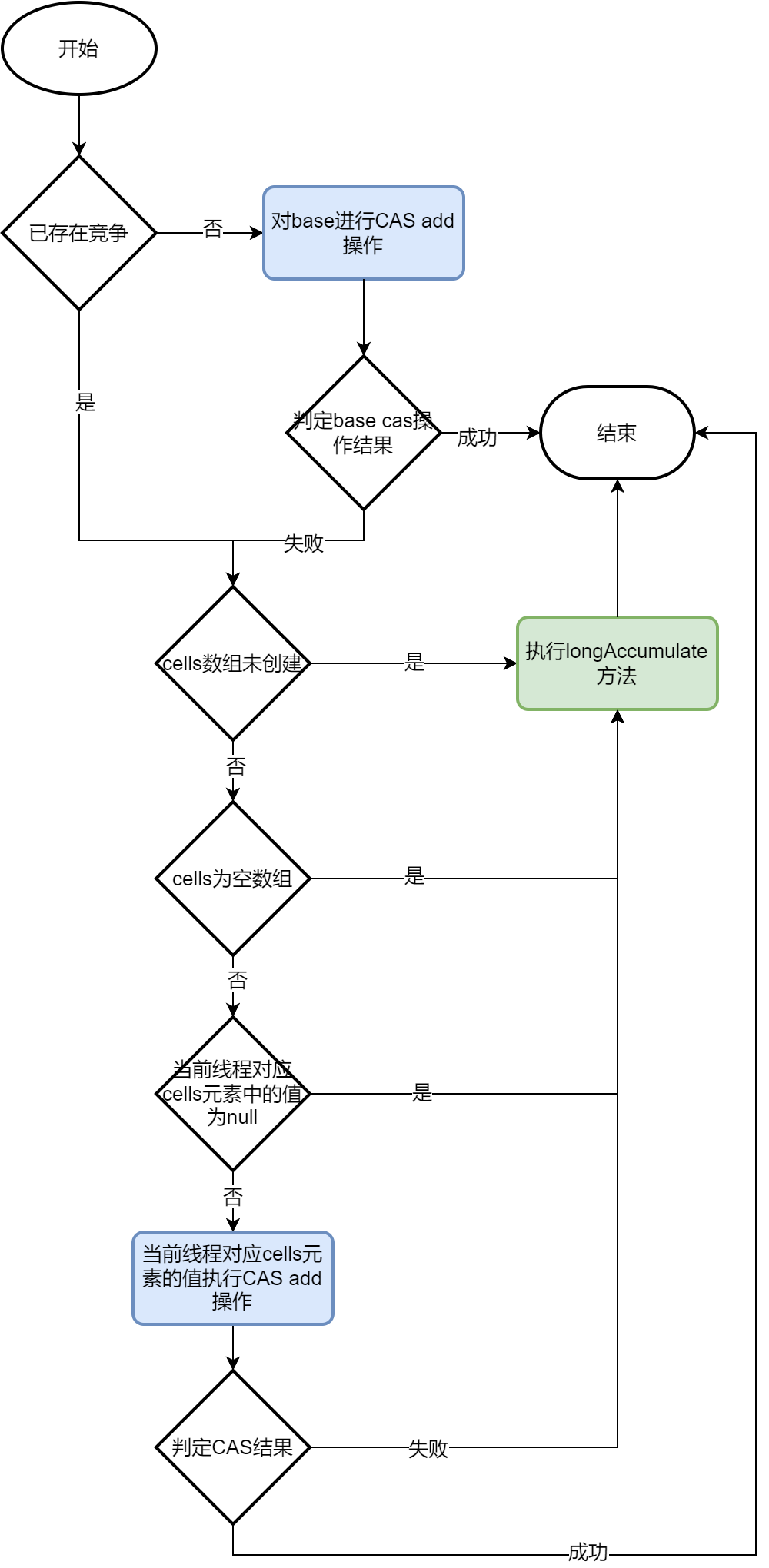
执行完该方法,会有三种情况的结果:
- 未发生过竞争,base变量CAS add操作成功
- 发生过竞争,当前元素对应的cells元素CAS add操作成功
- 以上两种情况都没成功,执行longAccumulate方法,确保当前方法能够add成功。
2、sum方法
/**
* Returns the current sum. The returned value is <em>NOT</em> an
* atomic snapshot; invocation in the absence of concurrent
* updates returns an accurate result, but concurrent updates that
* occur while the sum is being calculated might not be
* incorporated.
*
* @return the sum
*/
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
sum方法比较简单,它将base值和cells数组中的元素全部累加起来返回就是最终结果了。
三、Striped64源码解析
Striped64是LongAdder的父类,同时它也是DoubleAdder、DoubleAccumulator、LongAccumulator类的父类
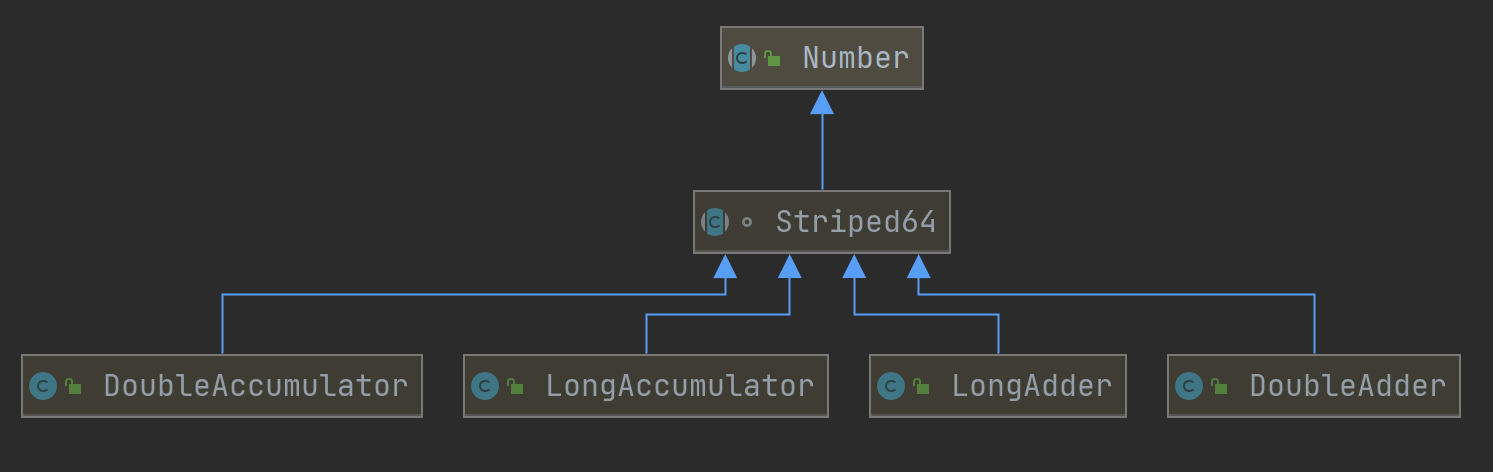
LongAdder类中的add方法,方法执行结果中的最后的三种情况中有一种是调用了longAccumulate方法,该方法是其父类Striped64中的方法。
1、Cell类
Cell类是Striped64的静态内部类,其定义如下
/**
* Padded variant of AtomicLong supporting only raw accesses plus CAS.
*
* JVM intrinsics note: It would be possible to use a release-only
* form of CAS here, if it were provided.
*/
@sun.misc.Contended //使用@Contended注解解决伪共享问题
static final class Cell {
//因为CAS的原因,所以必须要用volatile关键字修饰保证可见性
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
//value字段的对象偏移量
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
该类使用了@sun.misc.Contended 注解标注,这是为了解决“伪共享”问题,提高访问效率。关于伪共享,可以参考《伪共享(False Sharing)》。为什么会发生伪共享问题呢?因为在Striped64类内部有一个成员变量cells,它的定义如下:transient volatile Cell[] cells; 它是一个数组,数组在内存中保存的时候是相邻的,这就为伪共享问题的发生创造了条件。
该类内部成员变量value使用了volatile关键字修饰,这保证了可见性,因为可能会发生多线程对value的cas操作,而有cas的地方必有volatile是常识。
总结一下:Cell类包装了一个long类型的变量以及可以快速访问该字段的内存偏移量。并且保证了自己的可见性且免受“伪共享”问题的影响。
2、成员变量
/**
* Table of cells. When non-null, size is a power of 2.
*/
transient volatile Cell[] cells;
/**
* Base value, used mainly when there is no contention, but also as
* a fallback during table initialization races. Updated via CAS.
*/
transient volatile long base;
/**
* Spinlock (locked via CAS) used when resizing and/or creating Cells.
*/
transient volatile int cellsBusy;
base:未发生竞争的时候直接操作该变量,这时候和AtomicLong几乎一样
cells:发生竞争的时候分散热点,将值散落到各个Cell,减少线程冲突
cellsBusy:相当于CAS的“锁”,用于保证cells扩容或者创建Cell的安全性。
3、静态常量
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long BASE;
private static final long CELLSBUSY;
private static final long PROBE;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> sk = Striped64.class;
BASE = UNSAFE.objectFieldOffset
(sk.getDeclaredField("base"));
CELLSBUSY = UNSAFE.objectFieldOffset
(sk.getDeclaredField("cellsBusy"));
Class<?> tk = Thread.class;
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
} catch (Exception e) {
throw new Error(e);
}
}
这里使用了Unsafe计算了base、cellsBusy以及Thread对象的threadLocalRandomProbe变量的对象偏移量,用于以后Unsafe类相关CAS方法需要。
4、longAccumulate方法
longAccumulate是Striped64最核心的方法,其代码很复杂,我根据自己的理解几乎每行一个注释的方式标记了一下
/**
* Handles cases of updates involving initialization, resizing,
* creating new Cells, and/or contention. See above for
* explanation. This method suffers the usual non-modularity
* problems of optimistic retry code, relying on rechecked sets of
* reads.
*
* @param x the value
* @param fn the update function, or null for add (this convention
* avoids the need for an extra field or function in LongAdder).
* @param wasUncontended false if CAS failed before call
*/
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
//线程探针,类似于当前线程的hashCode,此处的缩写h即为hashCode的意思
int h;
//当前线程探针未初始化
if ((h = getProbe()) == 0) {
//强制初始化,生成线程探针
ThreadLocalRandom.current();
//重新获取线程探针
h = getProbe();
//调用当前方法之前的CAS成功标志,线程探针未初始化,表示之前并没有CAS操作,更不可能有CAS失败的情况,所以改为true
wasUncontended = true;
}
//初始化冲突标记为false
boolean collide = false;
for (; ; ) {
Cell[] as;
Cell a;
int n;
long v;
//① 如果cells数组已经创建
if ((as = cells) != null && (n = as.length) > 0) {
//② 当前线程对应的Cell为null
if ((a = as[(n - 1) & h]) == null) {
//③ 该if块将尝试创建Cell并添加到cells数组,此处锁标志如果为0表示可以拿到锁
if (cellsBusy == 0) {
//创建Cell
Cell r = new Cell(x);
//④ 再次判断锁标志,减少CAS竞争;如果锁标志位还是0,就尝试获取锁,如果获取锁成功,就开始尝试修改cells数组,新增创建的Cell元素
if (cellsBusy == 0 && casCellsBusy()) {
//初始化已创建标志为false
boolean created = false;
try {
Cell[] rs;
int m, j;
//再次判断当前线程对应的Cell是否为null,防止在③和④之间发生线程切换导致目标Cell被别的线程创建变成非空
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//添加Cell元素到cells数组
rs[j] = r;
//已创建标志位设置为true
created = true;
}
} finally {
//无论有没有成功,都必须释放锁
cellsBusy = 0;
}
//如果元素创建成功了,就停止for循环
if (created) {
break;
}
//如果创建失败了,表示当前线程对应的Cell非空,需要在下个循环重试
continue;
}
}
//⑤ 虽然没创建成功,但是未发生碰撞冲突
collide = false;
}
//⑥ 如果当前线程对应的Cell非空,而且调用该方法的之前的CAS失败(比如LongAdder的add方法中的cas)
else if (!wasUncontended) {
//在⑪处rehash,重新计算当前线程对应的Cell坐标,下次循环将会执行⑦进行CAS重试;此处设置为true的目的是为了下次循环不再走⑥这段逻辑,直接进入⑦
wasUncontended = true;
//⑦ 当前线程对应的cells中的元素不为空,则执行cas操作
} else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) {
//若是CAS成功,则停止循环
break;
//⑧ 验证数组长度是否超出限制,如果超出限制,设置冲突标志为false,将永远不会走⑩数组扩容逻辑
} else if (n >= NCPU || cells != as) {
// At max size or stale
collide = false;
//⑨ 运行到此处,⑦CAS失败表示出现了冲突,将会在⑪rehash一次之后在下次循环重试⑦CAS,如果仍然失败,同时cells数组长度没有超出限制,即不满足条件⑧,将执行⑩扩容操作
} else if (!collide) {
collide = true;
//⑩ collide为true⑨,表示出现了冲突,因为⑦CAS失败、⑧数组长度符合要求,这时候尝试通过扩容解决hash碰撞问题
} else if (cellsBusy == 0 && casCellsBusy()) {
try {
//此处判断Expand table unless stale
if (cells == as) {
//每次扩容数组大小都是原来的两倍
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i) {
rs[i] = as[i];
}
cells = rs;
}
} finally {
cellsBusy = 0;
}
//扩容完成后将冲突标记为已解决
collide = false;
// 下次循环将使用扩容后的数组执行⑦ CAS
continue;
}
//⑪对于cellsBusy而且未抢到锁的线程,重新生成hashCode重试
h = advanceProbe(h);
//⑫如果当前锁空闲而且cells数组为空,就尝试获取锁并初始化cells;cells == as的判定是用于判定是否存在其它线程初始化了cells数组
} else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
//再次判定是否存在其它线程初始化了cells数组,个人感觉是不需要再判定了。
if (cells == as) {
//初始化数组大小是2
Cell[] rs = new Cell[2];
//实际上是rs[h & (2 - 1)]
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init) {
break;
}
//⑬ 由于⑫失败,多个线程同时初始化只允许一个成功,其它获取锁失败的回退为对base执行cas操作
} else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) {
// 如果对base CAS成功,就终止循环
break;
}
}
}
可以看到该方法巨长而且循环+if嵌套结构看上去就让人头大。。为了更直观的明白这段代码的意思,看以下流程图:
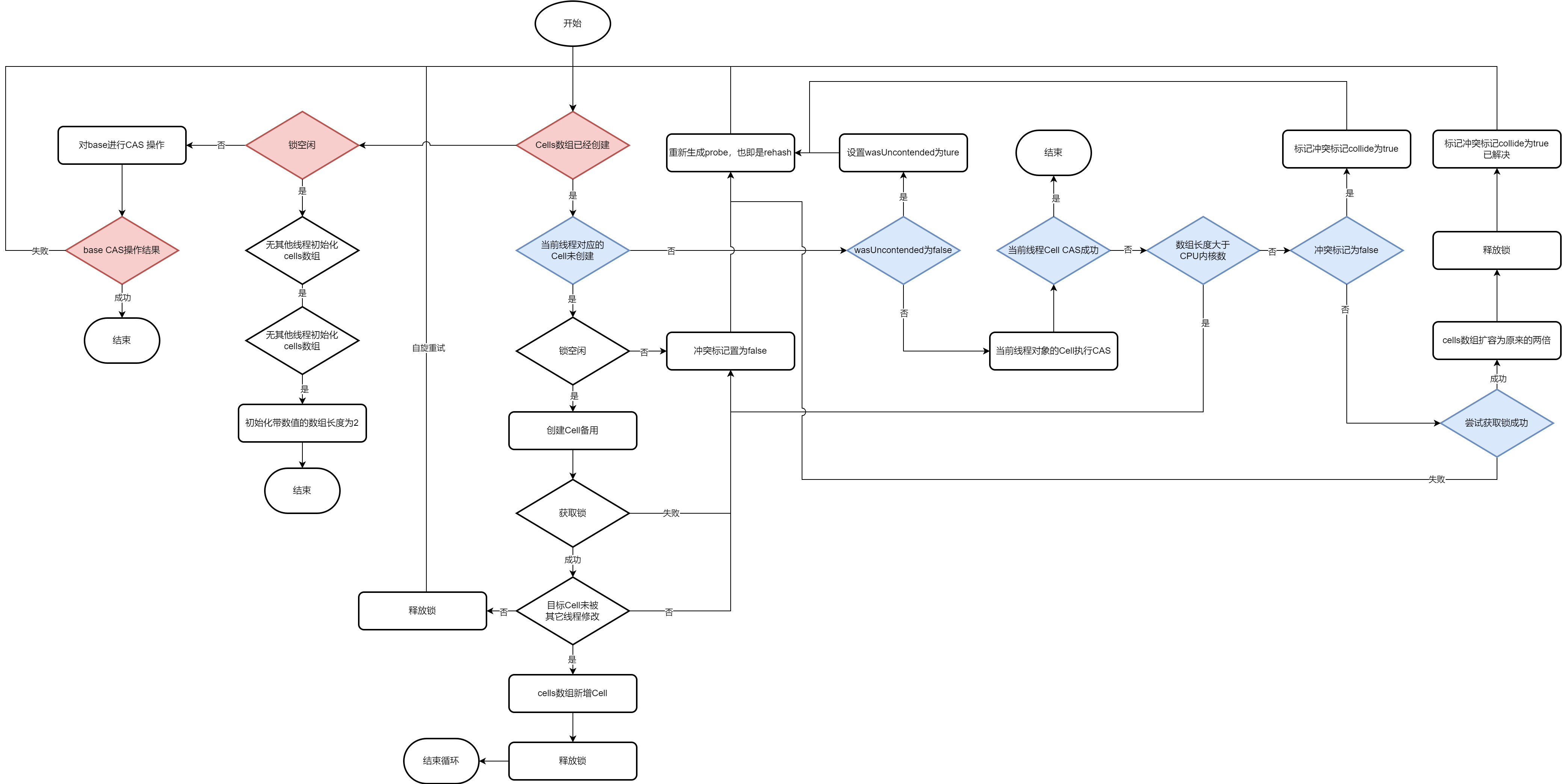
好吧,流程图还是很复杂,总之longAccumulate方法需要深入代码细节仔细研究才能研究明白,下面总结下longAccumulate方法的细节:
-
整体使用for循环实现“自旋重试”,确保一定能操作成功
-
使用了大量的if else实现流程控制,其顺序有特定含义,不可改变
-
wasUncontended入参代表了调用longAccumulate方法的调用者在调用longAccumulate方法前做CAS操作的结果,它仅仅会让for循环自旋一次,然后再进行CAS重试。
-
cellsBusy是锁,在cell初始化、创建Cell、cells扩容的时候为了线程安全性,操作前都需要获取锁,由于CAS操作是原子操作,而操作的目标cellsBusy被volitile修饰,具有可见性的同时禁止指令重排序,所以可以保证是线程安全的。
-
collide变量比较特殊,它实际的作用是控制cells数组扩容,当它为false的时候,永远走不到数组扩容的逻辑;当它为true的时候,取决于当前数组长度是否超过限制,即当前处理器核心数量。所以代码中看到这个变量的赋值操作,就要下意识的知道是想扩容还是禁止扩容。
-
cells数组初始化的时候长度是2,每次扩容使用左位移符号<<位移一位,也就是乘以2,然后将老数组赋值到新数组,并更新cells指针到新数组,所以数组长度必定是2的幂次方。
-
关于
Runtime.getRuntime().availableProcessors();得到的大小是“逻辑处理器”的核心数量比如我的电脑是6个性能核心+8个效率核心,实际上的逻辑处理器的数量就是性能核心数X2+效率核心数量,即6X2+8=20。关于这个,可参考《伪共享(False Sharing)》
四、LongAdder Vs AtomicLong
使用JMH微基准测试工具类测试两个类在多线程环境下自增一亿次所使用的时间,关于微基准测试,可以参考文章:《微基准测试工具JMH》
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
/**
* @author kdyzm
* @date 2024/10/14
*/
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Group)
@Fork(value = 1)
@Measurement(iterations = 5, time = 1, batchSize = 100000000, timeUnit = TimeUnit.SECONDS)
@Warmup(iterations = 5, time = 1, batchSize = 100000000, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
public class LongAdderVsAtomicLong {
public LongAdderVsAtomicLong() {
System.out.println("create instance");
}
private LongAdder longAdder;
private AtomicLong atomicLong;
@Setup
public void setUp() {
this.longAdder = new LongAdder();
this.atomicLong = new AtomicLong(0L);
}
@Benchmark
@Group("test")
@GroupThreads(5)
public void longAdderIncrement() {
this.longAdder.increment();
}
@Benchmark
@Group("test")
@GroupThreads(5)
public void atomicLongIncrement() {
this.atomicLong.incrementAndGet();
}
public static void main(String[] args) throws RunnerException {
final Options opts = new OptionsBuilder()
.include(LongAdderVsAtomicLong.class.getSimpleName())
.build();
new Runner(opts).run();
}
}
运行结果

可以看到,5个线程对一个数自增一亿次,LongAdder的效率是AtomicLong的近8倍。可以看得出LongAdder的效率确实高。
END.
注意:本文归作者所有,未经作者允许,不得转载