本篇文章将讲解langchain内置的第三方集成工具以及自定义工具的三种方式、自定义Input Schema的三种方式。
一、第三方集成工具
在上一篇文章《大模型开发之langchain0.3(三):方法调用》中,已经简单介绍过如何自定义工具以及结合支持function calling的大模型使用,本小节将介绍langchain中已经集成各种的第三方工具,这些工具开箱即用,在很多场景下使用起来很方便,不需要我们重复造轮子了。
全部的第三方集成工具列表:https://python.langchain.com/docs/integrations/tools/#all-tools
下面介绍几个常见的经典的工具使用案例。
1、Tavily Search:让大模型支持联网功能
大模型都是默认离线使用的,这导致它们不能获取最新网络上的数据,Tavily Search 则解决了这一痛点。
Tavily Search官网地址:https://tavily.com/
Tavily Search控制台地址:https://app.tavily.com/home
先注册,注册成功之后进入控制台:控制台上显示Tavily Search每个月有1000次的免费额度,这个额度对于学习和实验用足够用了。
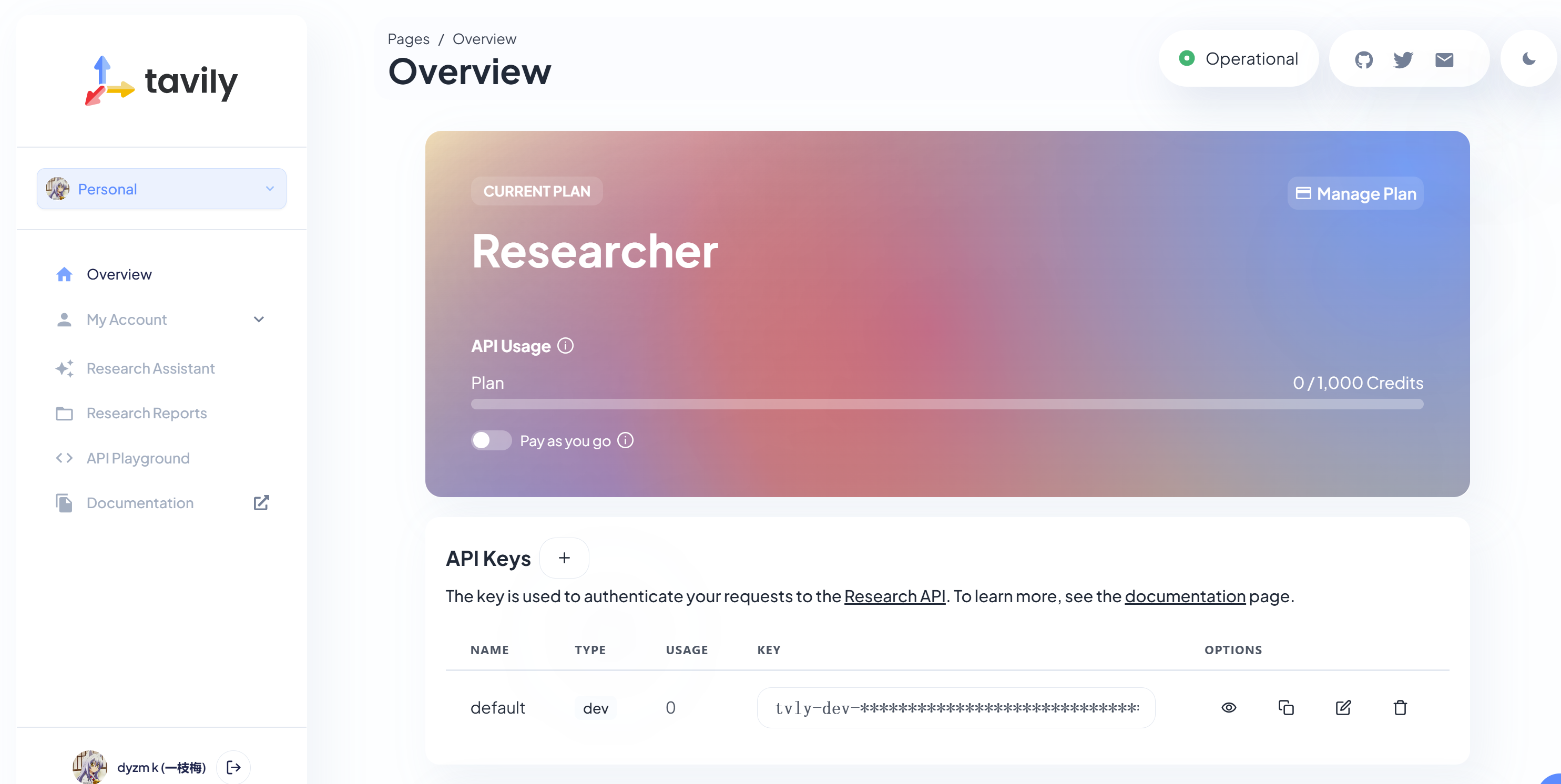
复制下来API Key,之后用的到,接下来看看如何使用Tavily Search工具。
Tavily Search langchain文档:https://python.langchain.com/docs/integrations/tools/tavily_search/
第一步:安装依赖
pip install langchain-tavily
第二步:设置环境变量
将之前复制下来的Key设置到环境变量:TAVILY_API_KEY ,注意,设置环境变量之后需要重启PyCharm,这里的重启指的的是关闭PyCharm,然后再打开,而非File->InvalidCaches / Restart 功能,使用restart功能环境变量不会更新。
第三步:工具定义
from langchain_tavily import TavilySearch
tool = TavilySearch(
max_results=5,
topic="general",
# include_answer=False,
# include_raw_content=False,
# include_images=False,
# include_image_descriptions=False,
# search_depth="basic",
# time_range="day",
# include_domains=None,
# exclude_domains=None
)
接下来按照上一篇文章《大模型开发之langchain0.3(三):方法调用》中最后的代码,将该工具加入工具列表中:
# Tool 创建
tools = [multiply, tavily_search_tool]
运行代码,尝试问大模型:今天北京的天气如何?观察输出结果。
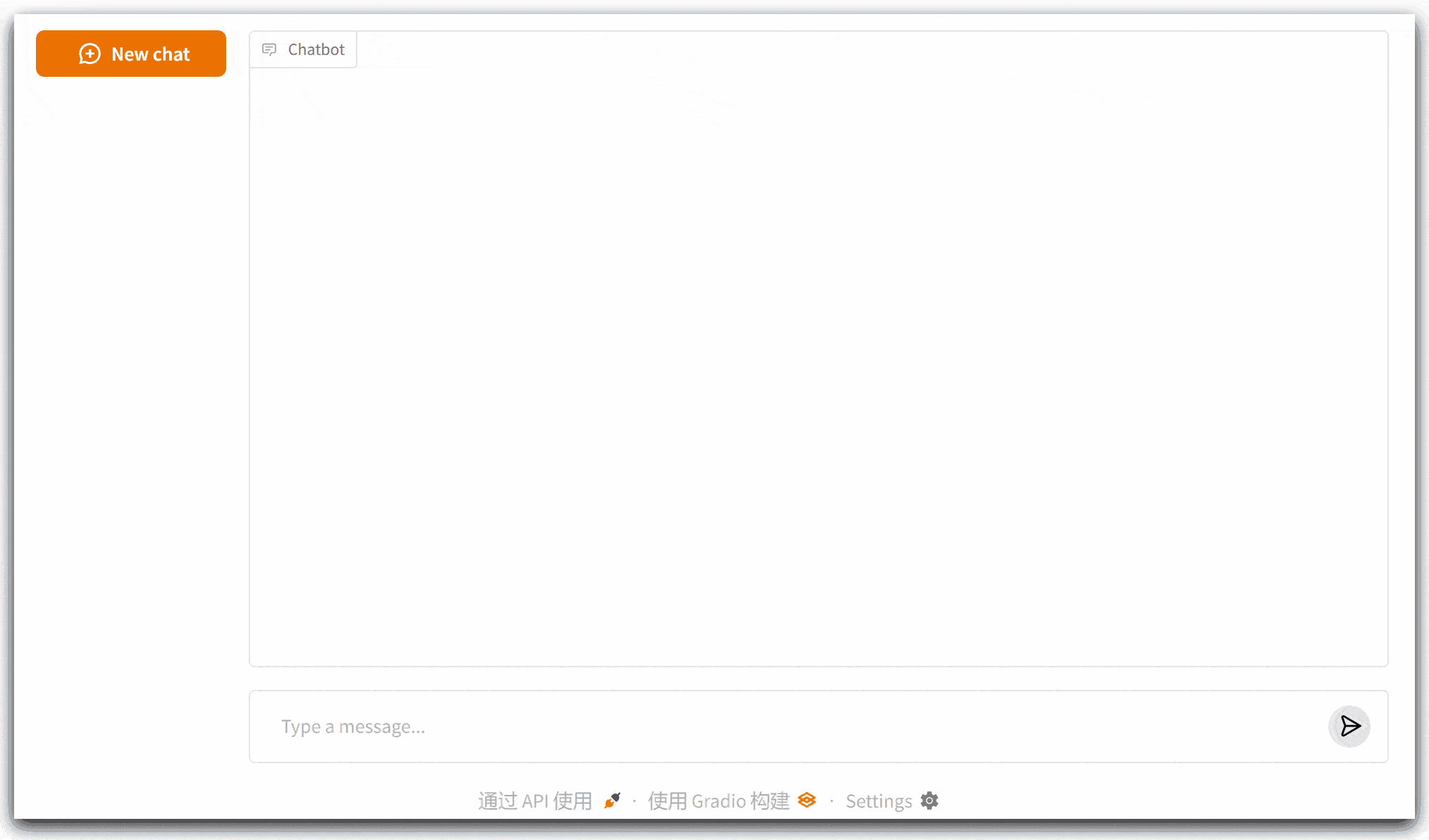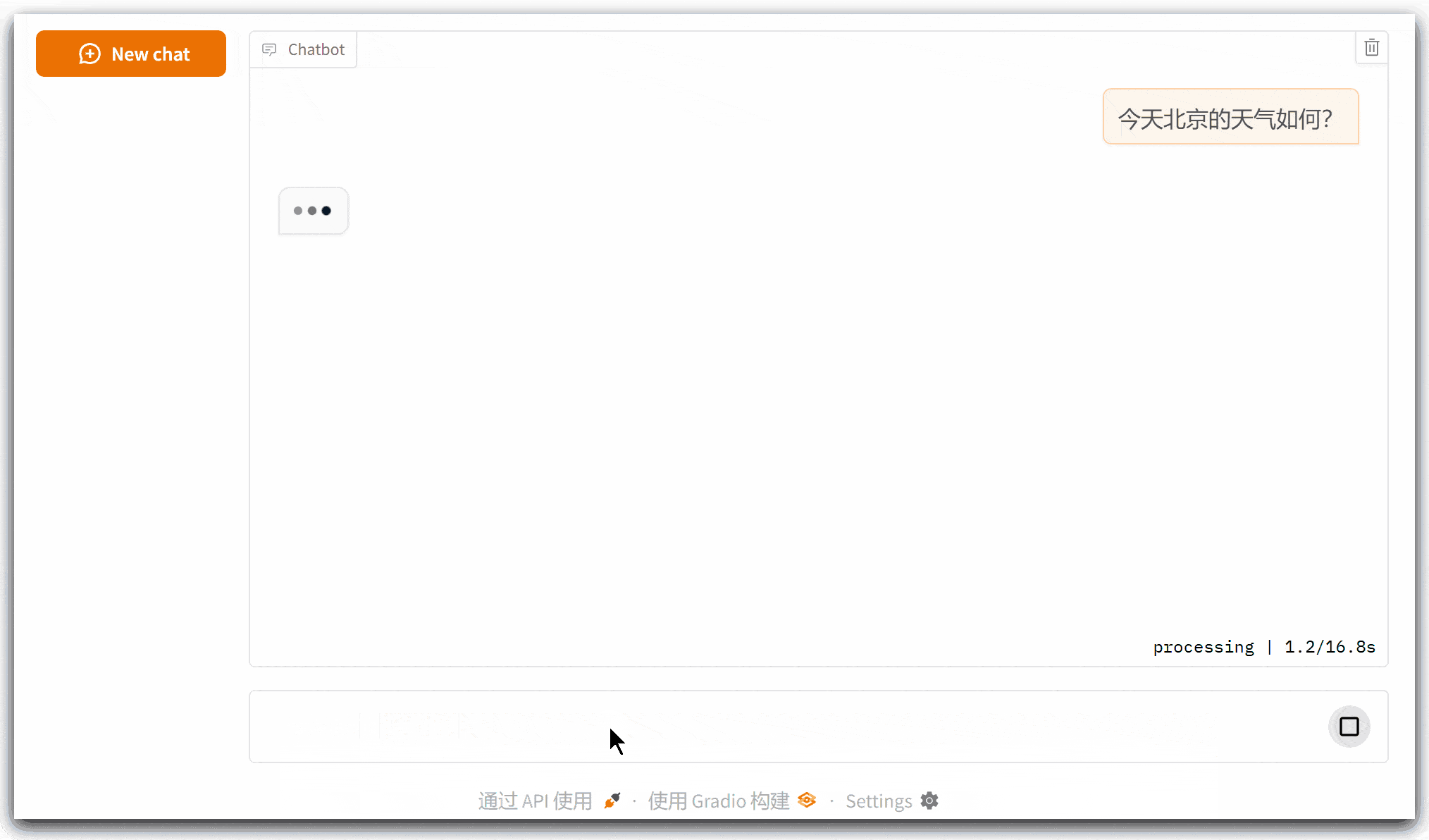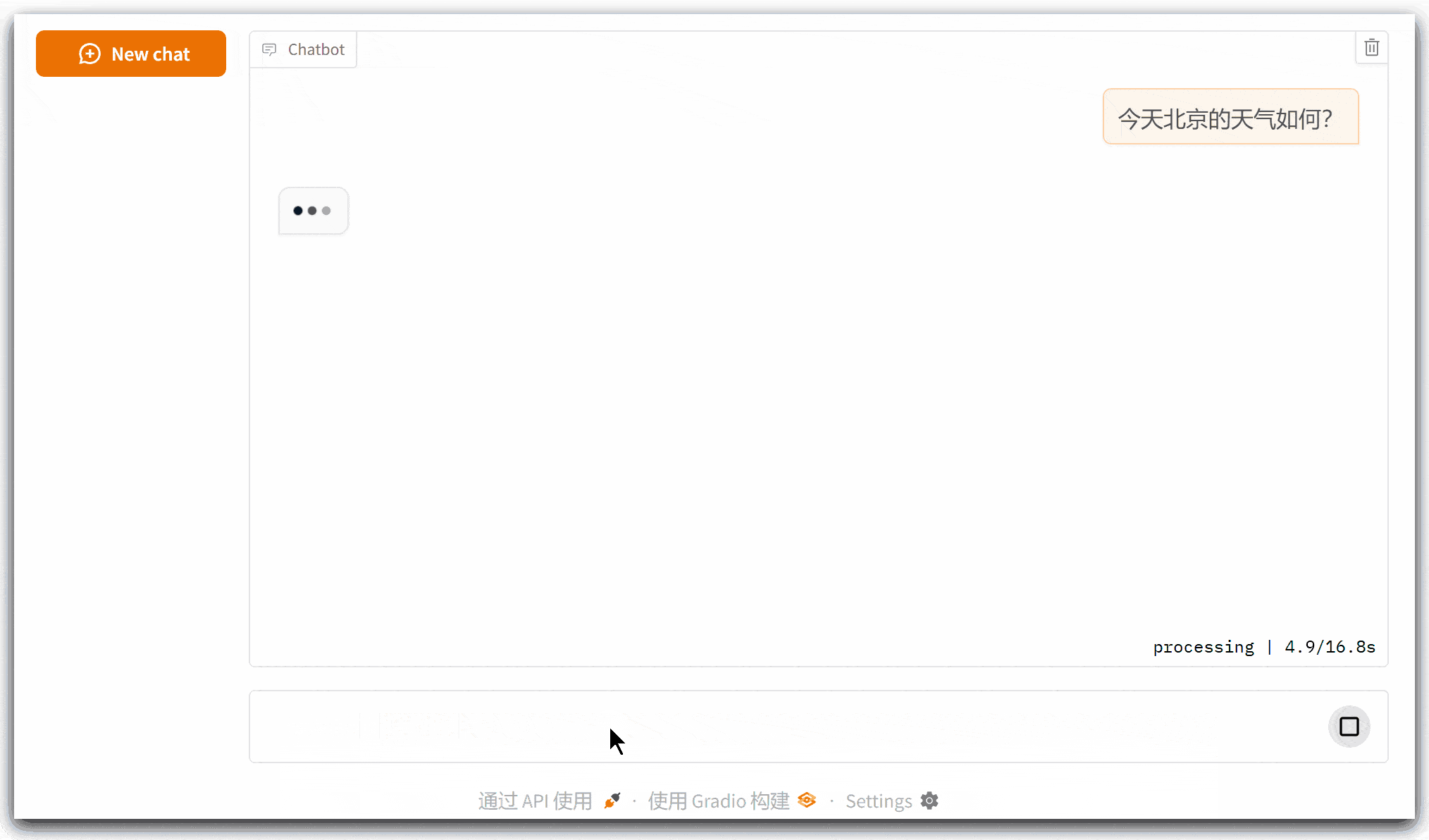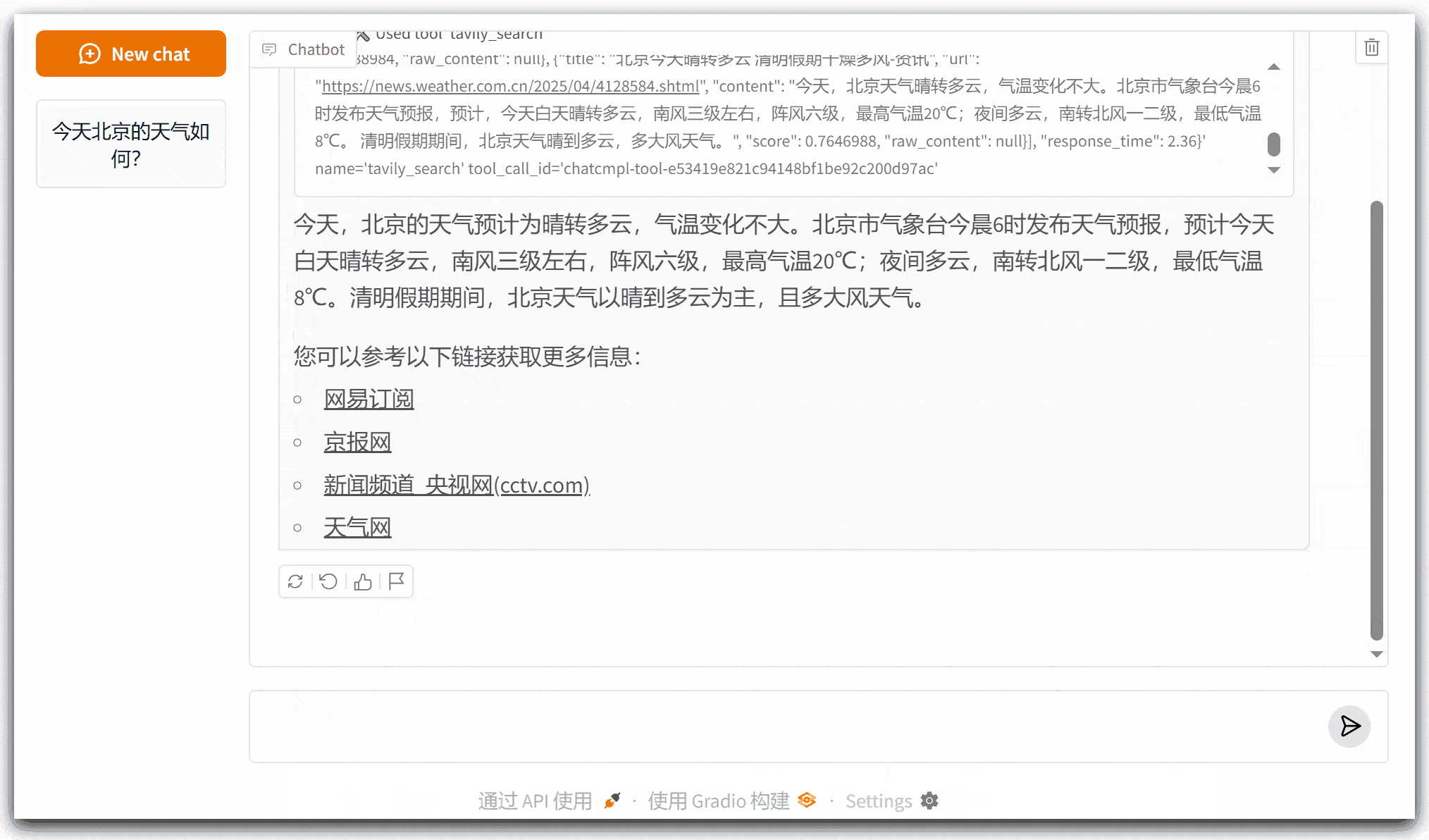
注意,如果运行报错,修改
trimmer = trim_messages(
max_tokens=300,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
将max_tokens值修改为3000再重试。
2、Wolfram Alpha:让大模型拥有数学计算能力

大模型本身就有数学计算的能力,但是它经常会“算错”,Wolfram Alpha 则赋能大模型让其具有更精准的数学计算的能力。
Wolfram Alpha 官网:https://www.wolframalpha.com/
Langchain Wolframe Alpha文档:https://python.langchain.com/docs/integrations/tools/wolfram_alpha/
注册成功之后在“我的应用程序”中创建AppID,记住AppID,后续用得到。
第一步:环境变量设置
将之前复制的AppID设置到环境变量:WOLFRAM_ALPHA_APPID,注意,设置成功后需要关闭PyCharm然后重新打开。
第二步:安装依赖包
pip install langchain-community==0.3.21 wolframalpha
第三步:定义工具方法
wolframaAlpha = WolframAlphaQueryRun(api_wrapper=WolframAlphaAPIWrapper())
接下来按照上一篇文章《大模型开发之langchain0.3(三):方法调用》中最后的代码,将该工具加入工具列表中:
tools = [tavily_search_tool, math_tool]
运行代码:
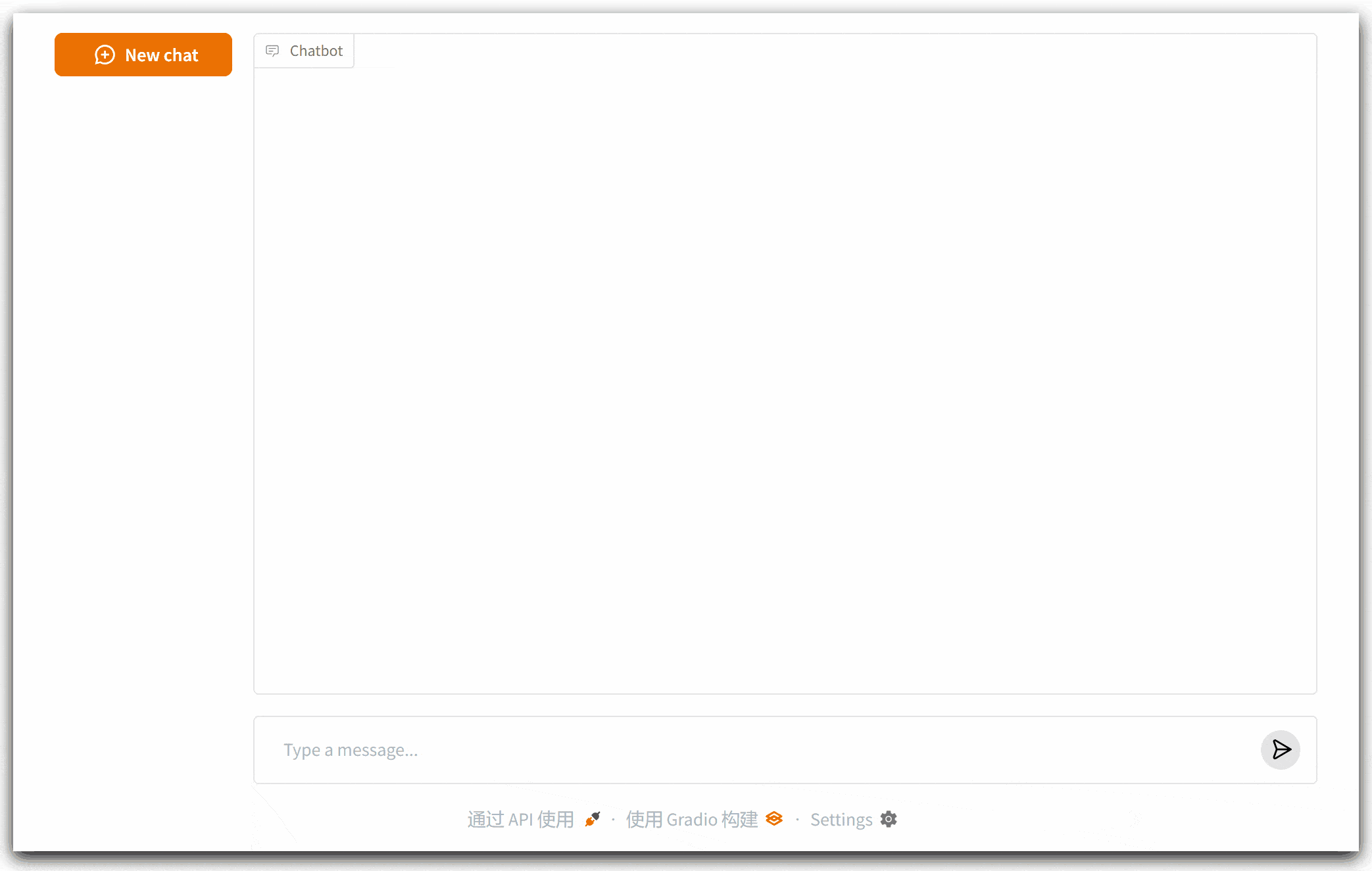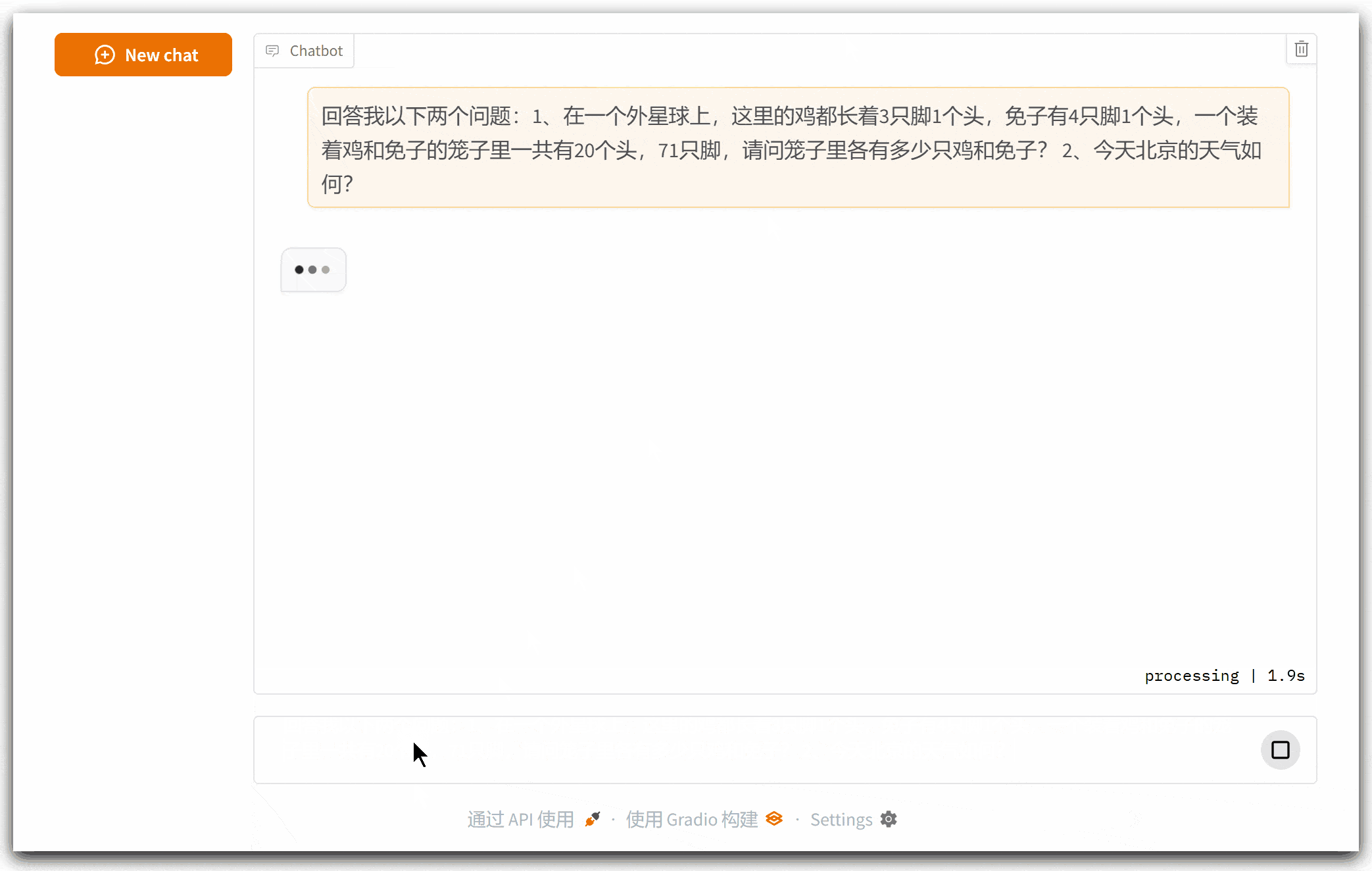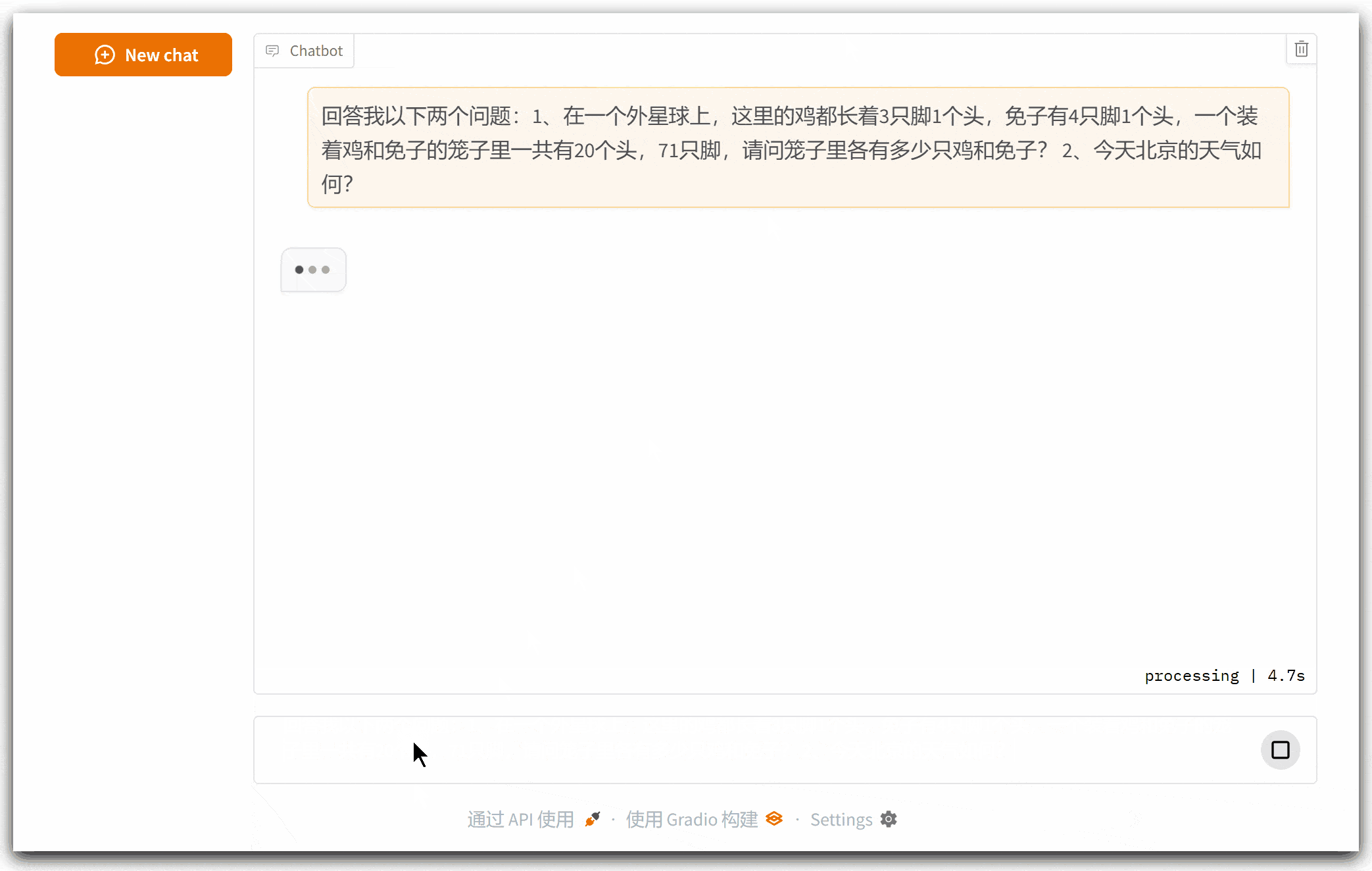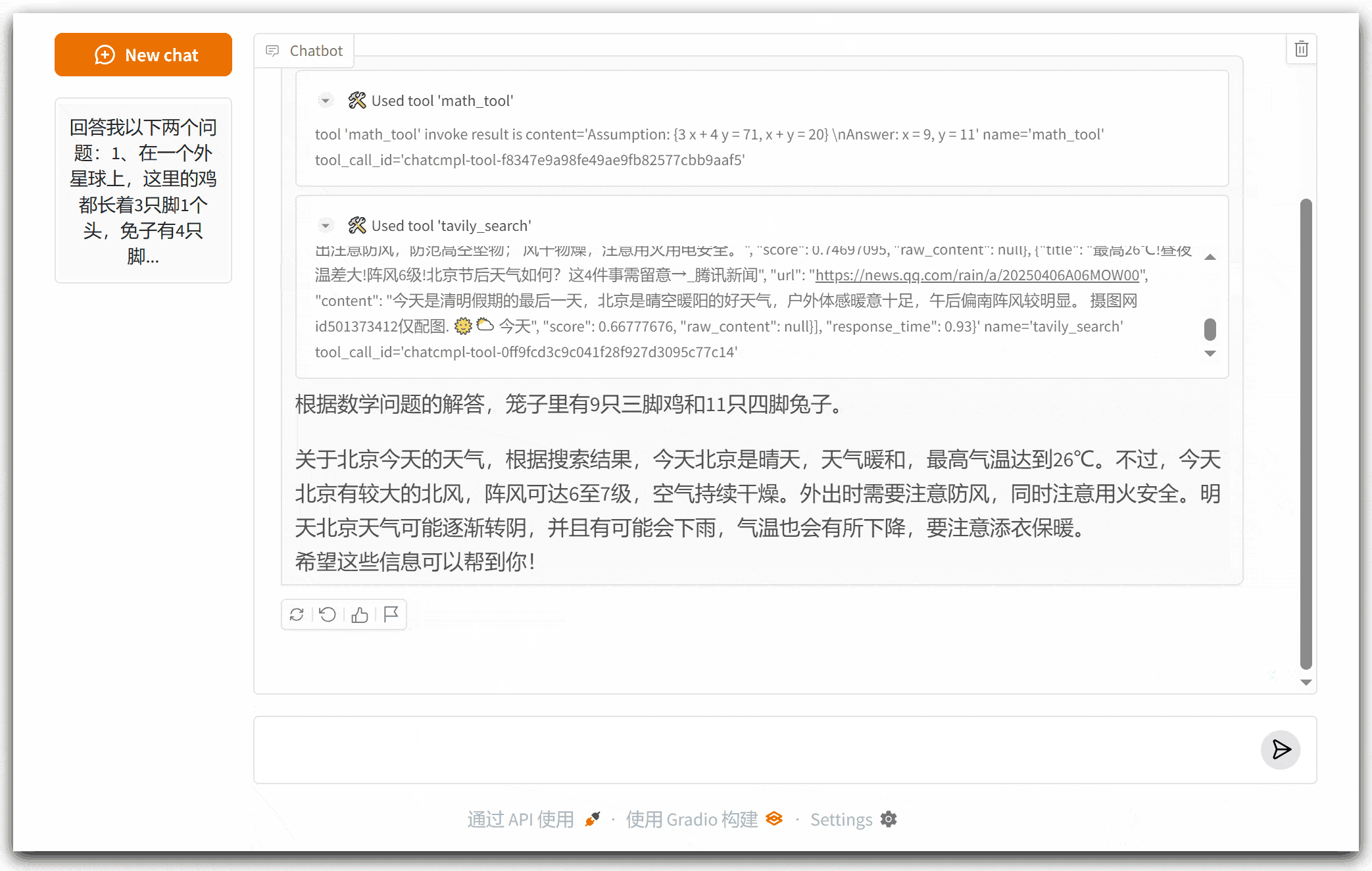
查看后台工具类打印出来的输入:
input math req=3x + 4y = 71, x + y = 20
可以看到,大模型将问题转化成了二元一次方程组,Wolfram Alpha只需要解方程组就好了。
3、其它工具
上述两个例子只做抛砖引玉之用,完整的工具列表可查看文档:https://python.langchain.com/docs/integrations/tools/#all-tools
大多数的第三方工具使用起来都很简单,只需要安装依赖,按照官方教程即可使用。
比如,如何引入维基百科的搜索功能,和Wolfram Alpha相似,只需要一行代码即可:
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
二、自定义工具的三种方式
官方文档:How to create tools
创建自定义工具有三种方式:普通方法构建、LangChain Runnable方法构建、继承BaseTool类构建。无论是哪一种构建方式,都需要遵循构建自定义工具的规范:工具方法要由name、description、args_schema、return_direct 四部分组成。
1、自定义工具的组成
一个自定义tool由以下几部分组成:
| 属性 | 类型 | 描述 |
|---|---|---|
| name | str | 当提供给LLM或者agent的时候,需要在工具列表中保持唯一;它最好有比较好的语义含义,这样有利于大模型作出合适的选择 |
| description | str | 这个工具是做什么用的。这个描述信息非常重要,大模型或者agent将会使用该信息作为是否调用该方法的依据。 |
| args_schema | pydantic.BaseModel | 可选的参数,但是推荐使用;使用该参数可以额外设置一些属性,比如在few-shot模式下给出examples |
| return_direct | boolean | 该参数是agent相关的参数,当为True的时候,agnet执行完方法会立即停止执行并将方法执行的结果返回给用户。 |
2、方法1:function方法构建Tool
从普通的方法构建中构建Tool在前面的文章《大模型开发之langchain0.3(三):方法调用》已经演示过了,在普通方法上加上装饰器@tool就可以将普通方法转化为Tool,比如一个简单的加法运算:
from langchain_core.tools import tool
@tool
def tool(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
if __name__ == '__main__':
print(type(tool))
print(f"Name: {tool.name}")
print(f"Description: {tool.description}")
print(f"args schema: {tool.args}")
print(f"returns directly?: {tool.return_direct}")
输出结果:
<class 'langchain_core.tools.structured.StructuredTool'>
Name: tool
Description: Multiply two numbers.
args schema: {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
returns directly?: False
可以看到,被@tool装饰器装饰之后的方法,类型从function变成了StructuredTool,因此,tool就有了name、description、args、return_direct等属性。
实际上,如果不想使用@tool装饰器,可以使用StructuredTool直接利用现有方法构建一个工具:
from langchain_core.tools import StructuredTool
import asyncio
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
async def amultiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator = StructuredTool.from_function(func=multiply, coroutine=amultiply)
print(calculator.invoke({"a": 2, "b": 3}))
print(asyncio.run(calculator.ainvoke({"a": 2, "b": 5})))
这样,对于原有的代码都不需要改动,就可以创建出一个工具,但是上述代码缺少了参数说明,LLM调用的时候是否会报错?可以通过额外新增一个参数说明的schema来描述这些信息。
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="multiply numbers",
args_schema=CalculatorInput,
return_direct=True,
# coroutine= ... <- you can specify an async method if desired as well
)
print(calculator.invoke({"a": 2, "b": 3}))
print(calculator.name)
print(calculator.description)
print(calculator.args)
通过定义CalculatorInput类,对输入参数进行了说明,这样大模型就能理解输入参数是什么意思了从而使得方法调用逻辑不会出错。
3、方法2:从Runnables接口构建Tool
Runnables详解:Runnable interface
官方文档:How to convert Runnables to Tools
Runnable接口是个比较大的话题,简单来说langchain的各种组件比如 language models, output parsers, retrievers, compiled LangGraph graphs 等等都实现了该接口,实现了该接口的组件,可以通过as_tool方法构建Tool:
from langchain_core.language_models import GenericFakeChatModel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[("human", "Hello. Please respond in the style of {answer_style}.")]
)
# Placeholder LLM
llm = GenericFakeChatModel(messages=iter(["hello matey"]))
chain = prompt | llm | StrOutputParser()
as_tool = chain.as_tool(
name="Style responder",
description="Description of when to use tool."
)
if __name__ == '__main__':
print(as_tool.args)
输出:
{'answer_style': {'title': 'Answer Style', 'type': 'string'}}
4、方法3:继承BaseTool类构建Tool
通过继承BaseTool类构建Tool需要些更多的代码,但是这是一种能够最大程度掌控工具创建细节的方法。
这种方式在上一节:《第三方集成工具》中无论是Tavily Search还是Wolfram Alpha,均是使用此种方式创建的工具。
import asyncio
from typing import Optional
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
from langchain_core.tools import BaseTool
from langchain_core.tools.base import ArgsSchema
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
# Note: It's important that every field has type hints. BaseTool is a
# Pydantic class and not having type hints can lead to unexpected behavior.
class CustomCalculatorTool(BaseTool):
name: str = "Calculator"
description: str = "useful for when you need to answer questions about math"
args_schema: Optional[ArgsSchema] = CalculatorInput
return_direct: bool = True
def _run(
self, a: int, b: int, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return a * b
async def _arun(
self,
a: int,
b: int,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
# If the calculation is cheap, you can just delegate to the sync implementation
# as shown below.
# If the sync calculation is expensive, you should delete the entire _arun method.
# LangChain will automatically provide a better implementation that will
# kick off the task in a thread to make sure it doesn't block other async code.
return self._run(a, b, run_manager=run_manager.get_sync())
if __name__ == '__main__':
multiply = CustomCalculatorTool()
print(multiply.name)
print(multiply.description)
print(multiply.args)
print(multiply.return_direct)
print(multiply.invoke({"a": 2, "b": 3}))
print(asyncio.run(multiply.ainvoke({"a": 2, "b": 3})))
输出:
Calculator
useful for when you need to answer questions about math
{'a': {'description': 'first number', 'title': 'A', 'type': 'integer'}, 'b': {'description': 'second number', 'title': 'B', 'type': 'integer'}}
True
6
6
三、自定义Input Schema的三种方式
官方文档:
How to use chat models to call tools
1、方法1:Python functions
这种方式是通过文档注释的方式声明Input Schema的:
import json
from langchain_core.tools import tool
@tool(parse_docstring=True)
def tool(a: int, b: int) -> int:
"""Add two integers.
Args:
a: First integer
b: Second integer
"""
return a + b
if __name__ == '__main__':
print(f"Name: {tool.name}")
print(f"Description: {tool.description}")
print(f"args schema: {json.dumps(tool.args, indent=4)}")
print(f"returns directly?: {tool.return_direct}")
输出:
Name: tool
Description: Add two integers.
args schema: {
"a": {
"description": "First integer",
"title": "A",
"type": "integer"
},
"b": {
"description": "Second integer",
"title": "B",
"type": "integer"
}
}
returns directly?: False
关键是要使用@tool装饰器,而且要设置parse_docstring属性为true。这种方式的好处是代码简洁,坏处是不够灵活,比如不能明确指定directly的值,工具名字和方法名是绑定的。
2、方法2:Pydantic class
这种方式通过继承BaseModel实现单独的Schema定义
from pydantic import BaseModel, Field
import json
from langchain_core.tools import tool
class AddSchema(BaseModel):
"""Add two integers."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
@tool("add tool", args_schema=AddSchema, return_direct=True)
def tool(a: int, b: int) -> int:
return a + b
if __name__ == '__main__':
print(f"Name: {tool.name}")
print(f"Description: {tool.description}")
print(f"args schema: {json.dumps(tool.args, indent=4)}")
print(f"returns directly?: {tool.return_direct}")
输出结果:
Name: add tool
Description: Add two integers.
args schema: {
"a": {
"description": "First integer",
"title": "A",
"type": "integer"
},
"b": {
"description": "Second integer",
"title": "B",
"type": "integer"
}
}
returns directly?: True
Process finished with exit code 0
3、方式3:TypedDict class
我个人比较喜欢这种方式,通过@tool装饰器、文档注释和字段注解相配合共同构建Input Schema。
import json
from typing import List
from langchain_core.tools import tool
from typing_extensions import Annotated
@tool
def tool(
a: Annotated[int, "scale factor"],
b: Annotated[List[int], "list of ints over which to take maximum"],
) -> int:
"""Multiply a by the maximum of b."""
return a * max(b)
if __name__ == '__main__':
print(f"Name: {tool.name}")
print(f"Description: {tool.description}")
print(f"args schema: {json.dumps(tool.args, indent=4)}")
print(f"returns directly?: {tool.return_direct}")
输出:
Name: tool
Description: Multiply a by the maximum of b.
args schema: {
"a": {
"description": "scale factor",
"title": "A",
"type": "integer"
},
"b": {
"description": "list of ints over which to take maximum",
"items": {
"type": "integer"
},
"title": "B",
"type": "array"
}
}
returns directly?: False
END.
注意:本文归作者所有,未经作者允许,不得转载