在上一篇文章《Redis(七):多机部署之主从复制模式》中讲过在主从复制模式下从节点发生了故障之后重连数据重新同步的问题,但是并没有提过主节点发生了故障会发生什么。实际上从节点挂掉并不会影响什么,但是主节点挂掉影响就大了,如果没有高可用机制,则需要人工干预手动选择其他节点作为主节点,整个过程从发现到处理结束不仅耗时处理还繁琐。如何让这个过程自动化呢?这就是本篇文章讨论的主题:基于Redis6.2.1使用sentinel实现Redis主从复制模式高可用。
一、手动处理主节点故障
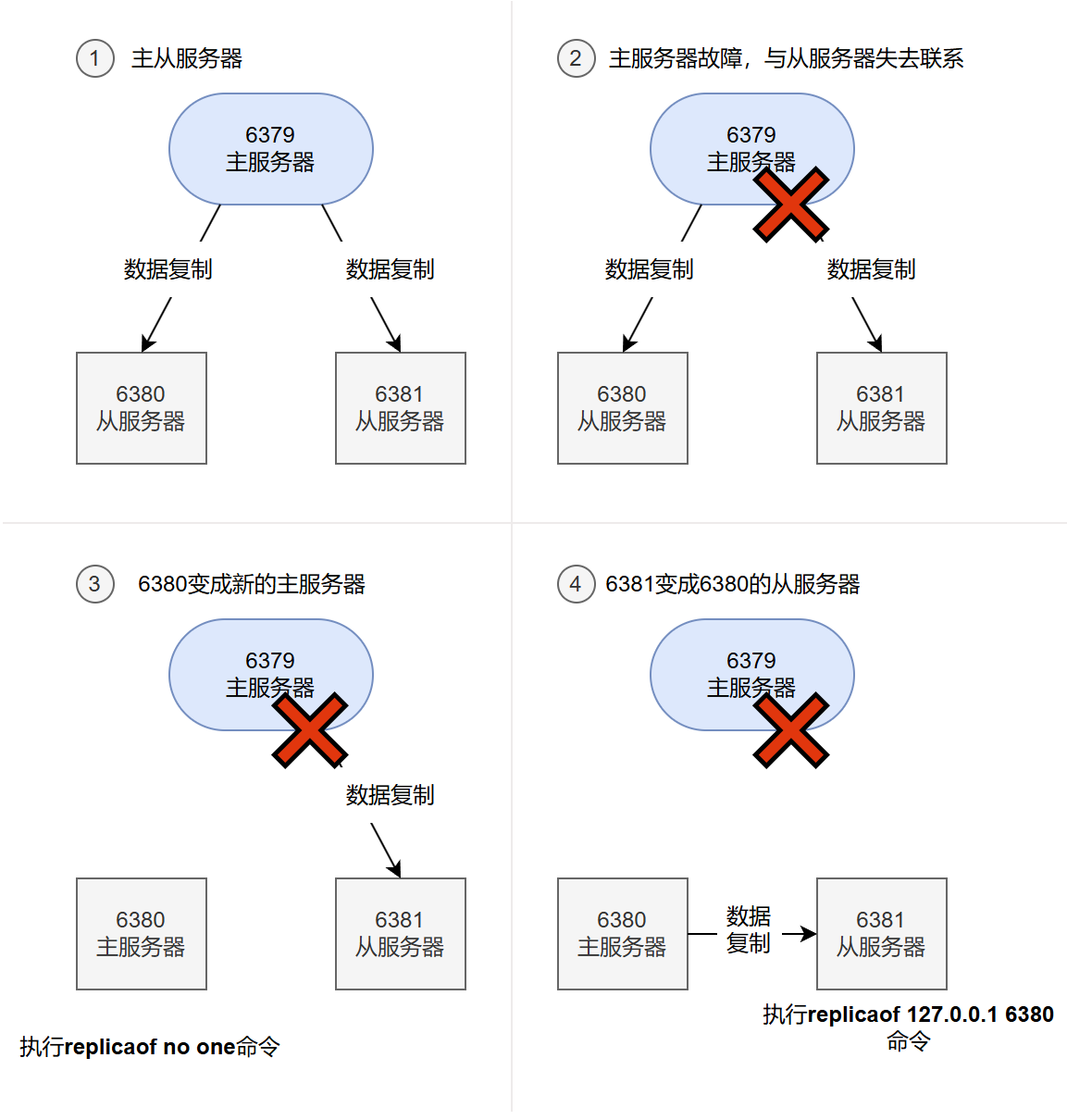
主从服务器拥有相同的数据,所以它们在理论上是可以互相替换的:如果我们把主服务器的某个从服务器转换为主服务器,让它代替原来的主服务器处理命令请求,那么它得出的结果应该与原来的主服务器处理相同请求时得出的结果一致。基于这个原理,我们可以在主服务器因故下线时,将它的其中一个从服务器转换为主服务器,并使用新的主服务器继续处理命令请求,这样整个系统就可以继续运转,不必仅因为主服务器的下线而停机。这种使用正常服务器替换下线服务器以维持系统正常运转的操作,一般被称为故障转移(failover)
因为Redis支持主从复制特性,所以我们同样可以对下线的Redis主服务器实施故障转移。举个例子,假设现在有一个主服务器127.0.0.1:6379(简称6379),它有两个从服务器127.0.0.1:6380(简称6380)和127.0.0.1:6381(简称6381),这3个服务器分别处理一些客户端的命令请求。如果在某一时刻,主服务器6379因为故障而下线,那么我们可以向6380发送命令REPLICAOF no one,将它转换为主服务器,然后向另一个从服务器6381发送命令REPLICAOF 127.0.0.6380,让它去复制新的主服务器6380,这样就可以重新建立起一个能够正常运作的主从服务器连接,并继续处理客户端发送的命令请求。
简单来说,如果我们在前面的例子中,使用了Redis sentinel来监视主服务器6379以及它的两个从服务器6380、6381,那么在6379因为故障而下线时,Redis sentinel就会把6380和6381的其中一个转换为主服务器,并让另一个从服务器去复制新的主服务器,这个过程完全不需要人工介入。
二、部署主从复制+sentinel
组建sentinel网络的方法非常简单,与启动单个sentinel时的方法一样:用户只需要启动多个sentinel,并使用sentinel monitor配置选项指定sentinel要监视的主服务器,那些监视相同主服务器的sentinel就会自动发现对方,并组成相应的sentinel网络。
在启动sentinel之前,我们先把主从复制模式的一主两从启动起来,详情可看文章《Redis(七):多机部署之主从复制模式》部署完成之后的架构图:
接下来在同一台机器上启动三个sentinel实例。
源码构建redis(参考CentOS安装Redis)后,sentinel的程序文件和redis-server同一个文件夹,文件名为redis-sentinel,配置文件则和redis.conf文件夹同一个目录,文件名为sentinel.conf:
redis-6.2.1
│
├── redis.conf
├── sentinel.conf
└── src
├── redis-server
└── redis-sentinel
之后创建三个文件夹sentinel.1、sentinel.2、sentinel.3分别将redis-sentinel、sentinel.conf文件复制进去,目录结构最终如下所示:
├── sentinel.1
│ ├── redis-sentinel
│ └── sentinel.conf
├── sentinel.2
│ ├── redis-sentinel
│ └── sentinel.conf
└── sentinel.3
├── redis-sentinel
└── sentinel.conf
我们的目标架构如下:
1、配置文件修改
启动sentinel的命令是./redis-sentinel ./sentinel.conf,形式和redis-server的启动方式很像。sentinel的配置文件很重要,sentinel程序不仅读,而且还写该配置文件,所以在运行sentinel程序的时候一定要确保当前用户对该文件拥有写权限。下面说下配置文件的重要配置:
port 26379 #默认端口号26379,运行多个实例需要改动端口号
daemonize no #是否在后台运行
pidfile /var/run/redis-sentinel.pid #后台运行时创建的pid文件名
logfile "" #日志文件的名称
dir /tmp #工作目录,最好是./这样可以方便查看日志文件
sentinel monitor mymaster 127.0.0.1 6379 2 #最重要的配置文件,监听的主服务器名称、ip、端口号以及quorum
sentinel down-after-milliseconds mymaster 30000 #多少毫秒内主服务器无响应考虑其主观下线
配置文件中最重要的配置就是sentinel monitor mymaster 127.0.0.1 6379 2,其中最后的2是quorum,当认为主节点主观下线的哨兵数量到达quorum的时候,就会执行故障转移操作。
修改配置文件成如下所示:
bind 0.0.0.0
port 26379 #另外两个sentinel实例修改为26380
daemonize yes
pidfile /var/run/redis-sentinel1.pid #另外两个sentinel实例修改成redis-sentinel2.pid、redis-sentinel3.pid
logfile "sentinel.log"
dir ./
另外两个配置:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
则不需要动,特别注意此处为主服务器命名"mymaster",在配置文件中有多处配置都使用了该名字,如果修改改名字,一定要全改掉。
2、启动sentinel
修改完配置文件以后,在三个文件夹中依次运行命令:
./redis-sentinel ./sentinel.conf
启动后查看26379日志:
2561:X 15 Jul 2025 13:26:06.421 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2561:X 15 Jul 2025 13:26:06.422 # Redis version=6.2.1, bits=64, commit=00000000, modified=0, pid=2561, just started
2561:X 15 Jul 2025 13:26:06.422 # Configuration loaded
2561:X 15 Jul 2025 13:26:06.422 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2561:X 15 Jul 2025 13:26:06.422 * monotonic clock: POSIX clock_gettime
2561:X 15 Jul 2025 13:26:06.423 * Running mode=sentinel, port=26379.
2561:X 15 Jul 2025 13:26:06.423 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2561:X 15 Jul 2025 13:26:06.423 # Sentinel ID is 3a03b019736dfe3fe57e78863b8039d2c84b7a3a
2561:X 15 Jul 2025 13:26:06.423 # +monitor master mymaster 127.0.0.1 6379 quorum 2
2561:X 15 Jul 2025 13:30:37.763 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
2561:X 15 Jul 2025 13:30:37.764 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
之后26380和26381逐个启动起来之后,26379会打印日志:
2561:X 15 Jul 2025 13:39:23.767 * +sentinel sentinel 928560c4df01bf5b19ad19751fbeae80db947c18 127.0.0.1 26380 @ mymaster 127.0.0.1 6379
2561:X 15 Jul 2025 13:40:36.276 * +sentinel sentinel 9a84c1618c95ae74ed8000efee50be6a7bd4a73c 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
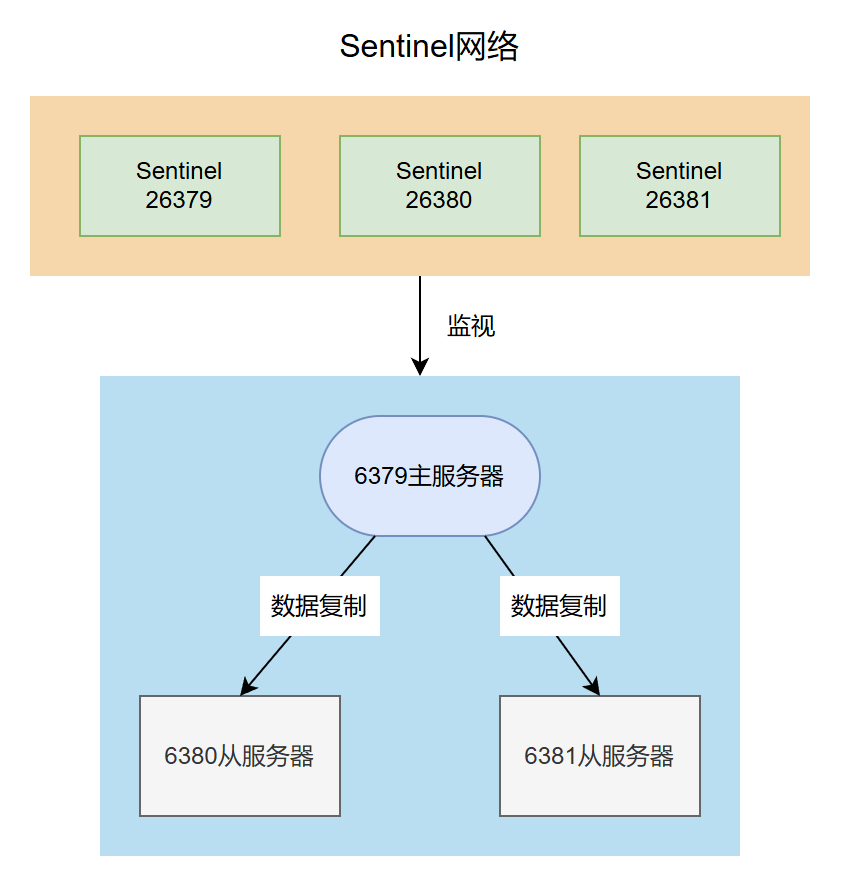
这样即表示sentinel集群已经正确监控redis的master节点以及两个slave节点。现在我们有了三个sentinel实例以及一主两从三个redis实例,架构图如下所示:
3、部署验证
先使用命令
ps -aux | grep redis
查看三个sentinel和三个redis实例进程是否都在线:

没问题的话我们进行一个实验:突然把master干掉,看看sentinel会怎么做。
第一步:打开三个窗口,使用tail -f -n 200 sentinel.log命令实时查看日志
第二步:使用kill 1795杀掉redis master实例的进程
查看三个sentinel实例的日志(可能得等待几秒钟才能看到日志):
sentinel1的日志:
sentinel2的日志:

sentinel3的日志:
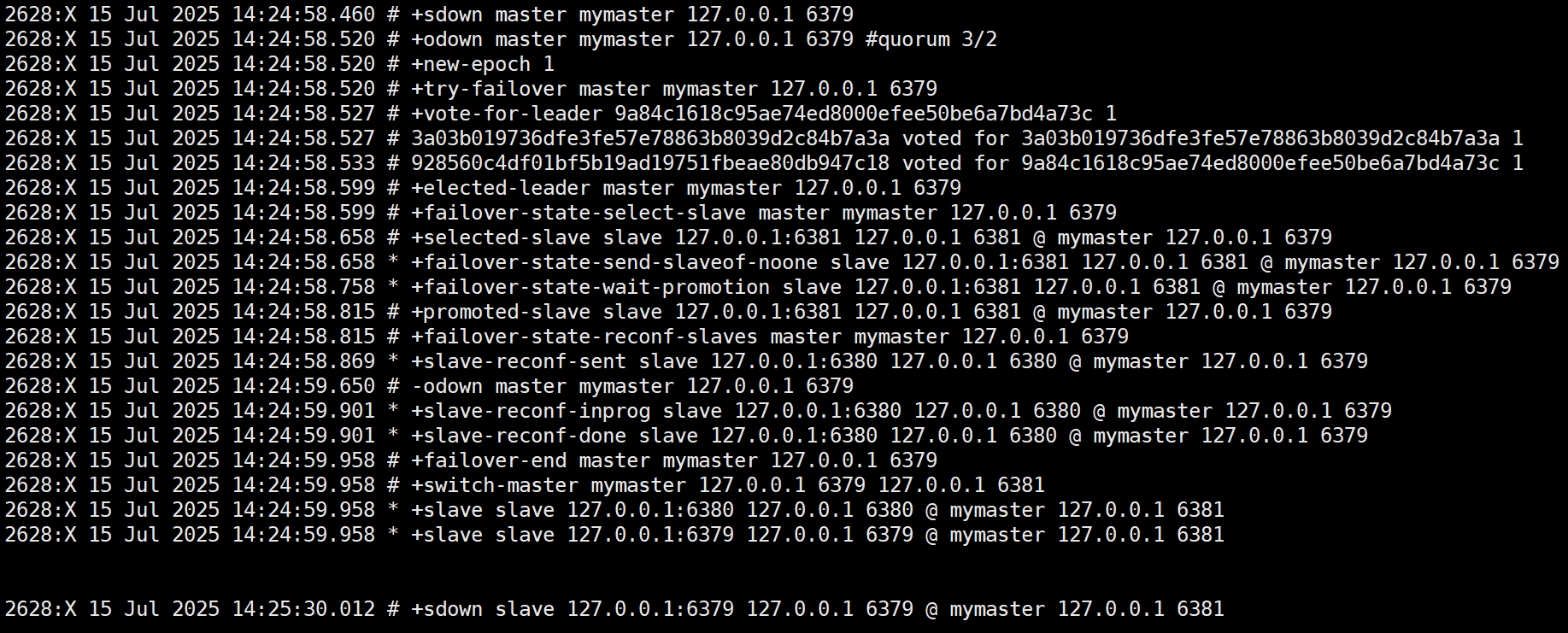
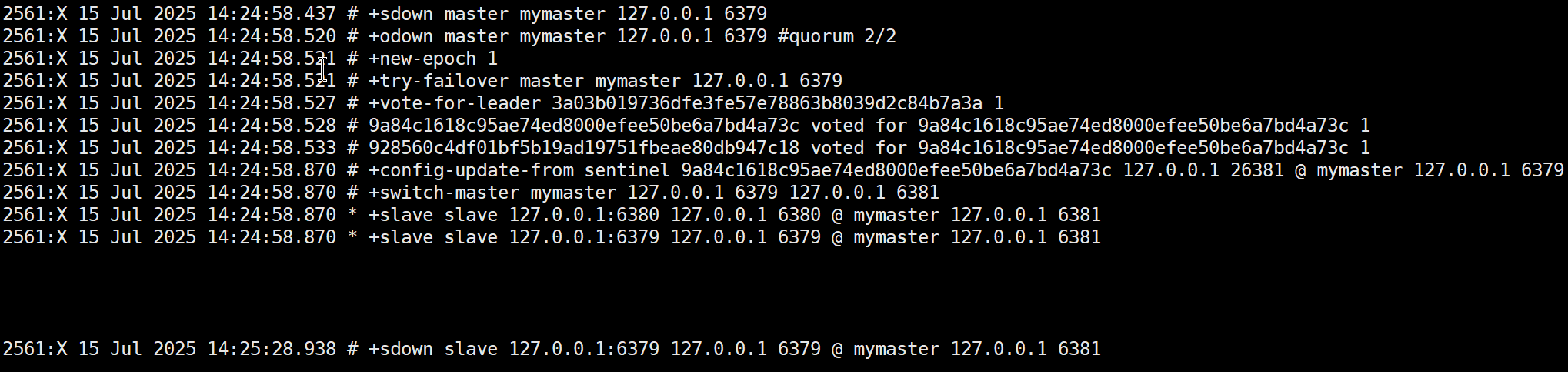
从日志中可以看到(日志详解参考附录部分),哨兵最终选举了sentinel3作为执行者执行了故障转移,6381被选择成为新的主节点,原来的6379被标记为主观下线了。
使用redis-cli进入6381redis实例,查看其角色信息:
127.0.0.1:6381> role
1) "master"
2) (integer) 2655664
3) 1) 1) "127.0.0.1"
2) "6380"
3) "2655664"
可以看到,6381节点已经变成了master节点,而且它只有一个副本。
接下来我们将6379重新上线,看看sentinel做了什么:
三个sentinel实例打印了如下日志:
2561:X 15 Jul 2025 15:20:42.236 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
表示消除了6379的主观下线状态,sentinel实例多了一行日志:
2561:X 15 Jul 2025 15:20:52.245 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
这表示将6379变成6381实例的副本。
再次进入6381 redis-cli,查看角色信息:
127.0.0.1:6381> role
1) "master"
2) (integer) 2729754
3) 1) 1) "127.0.0.1"
2) "6380"
3) "2729621"
2) 1) "127.0.0.1"
2) "6379"
3) "2729754"
可以看到6379确实已经成为了6381的副本。
至此,我们验证了sentinel确实发挥了作用。
三、sentinel故障转移原理
我们的哨兵网络中有三个哨兵实例,每个实例都会独立检测除了自己之外的所有实例,包括redis实例以及sentinel实例,一旦主节点下线,每个哨兵都会发现,然后将其标记为“主观下线”,表示当前哨兵认为主节点不可用,同时通知其它哨兵。当认为主节点主观下线状态的哨兵数量大于配置的quorum时,会将该主节点标记为“客观下线”。这时,将开始正式的故障转移流程。
由于哨兵节点有多个,不可能都去执行故障转移操作,它们会先选举出来一个代表,具体的操作就是每个哨兵节点都从所有哨兵节点中投票选举一个,票多者成为leader,成为leader的哨兵将具体执行故障转移。
成为leader的哨兵先从所有的slave节点中选择合适的节点向其发送slaveof no one命令,使其成为主节点;之后重新设置其它节点,让其它节点成为该主节点的从节点(包括已下线的原主节点)。
最后,所有哨兵更新主节点和从节点信息,完成故障转移流程。
我们着重看下这个流程中的选举哨兵leader以及选举新的master节点的细节。
1、选举哨兵leader
Redis哨兵模式中的Leader选举是一个基于Raft算法的分布式一致性过程,用于在主节点故障时选举出一个负责协调故障转移的哨兵领导者。
哨兵Leader选举的触发条件是主节点被确认为**客观下线(ODown)**状态。这需要先经过:
- 主观下线(SDown):单个哨兵通过心跳检测(PING命令)发现主节点无响应,该哨兵将主节点状态标记为主观下线。
- 客观下线(ODown):当quorum数量的哨兵(通常为多数)都认为主节点不可用,达成共识,所有哨兵将该节点状态标记为客观下线。
选举采用了Raft算法,其核心要点包括:
-
**纪元(epoch)**机制:类似于Raft的term概念,每次选举会递增epoch值,确保选举过程有序
-
先到先得原则:最先发起投票请求的哨兵有更大几率成为Leader
-
多数决原则:候选人需要获得超过半数的哨兵投票才能当选
哨兵确认主节点ODown后,将自己的current_epoch加1,然后将leader字段指向自己,表明要参与竞选;随后向其他所有哨兵发送sentinel is-master-down-by-addr命令,附带自己的epoch和runID。**每个哨兵节点只能投一票,遵循"先到先投"原则。**收到请求的哨兵会比较请求中的epoch与自己的current_epoch:
- 如果请求epoch更大,则更新自己的epoch并将票投给请求方
- 如果epoch相同,则投给自己已记录的leader(可能是自己)
已投过票的哨兵会拒绝后续请求。
最终,得票最多的哨兵将成为leader。
在我们的例子中,有三个哨兵节点实例:
sentinel1:3a03b019736dfe3fe57e78863b8039d2c84b7a3a
sentinel2:928560c4df01bf5b19ad19751fbeae80db947c18
sentinel3:9a84c1618c95ae74ed8000efee50be6a7bd4a73c
三个哨兵节点均发现了主节点主观下线的事实,然后将该消息传播给了其它哨兵节点。
哨兵1最先得到消息,但是并没有得到所有消息,它只知道包括自己在内,有两个哨兵已经发现主节点主观下线了,并且触达了quorum阈值,主节点已经达到了客观下线的条件。所以它立即将纪元值自增1并发起投票,由于它觉得是自己发现主节点客观下线的,所以它将票投给了自己:

其实哨兵1不知道的是,哨兵3则知道3个哨兵的主节点主观下线状态了,所以哨兵3和哨兵1一样,都以为自己是第一个发现主节点客观下线的,所以它也将纪元新增1并且发起了投票,同样的,它将票投给了自己:

所以得胜票在哨兵2手里,哨兵2先收到谁的投票请求,它就会将票投给谁:

它将票投给了哨兵3,这意味着它先收到了节点3的投票请求,节点3顺利成章成为了哨兵leader。
2、选择新的主节点
选择新的主节点按照优先级 > offset > run id的次序依次筛选。
-
优先级最高的从节点胜出。每个redis数据节点都会在配置文件中有一个优先级配置(slave-priority,默认情况下都相同)
-
复制偏移量offset最大的从节点胜出。offset代表从节点从主节点这里同步数据的进度。数值越大,说明从节点的数据和主节点就越接近。
-
run id值更小的胜出。run id是每个redis节点启动的时候随机生成的一串数字(大小全凭缘分)。此时意味着优先级和offset都一样,那么选谁都可以,其实就是随便挑一个。
在我们的例子中,由于两个副本的优先级相同,有可能是6381的复制偏移量更大,也有可能是随机被选择到的,说不好是什么原因被选择到的。
四、sentinel管理命令
使用redis-cli可以像进入redis-server一样进入redis-sentinel执行各种命令,实际上sentinel的启动命令./redis-sentinel ./sentinel.conf可以替换为./redis-server ./sentinel.conf --sentinel,两者是等价的。
进入sentinel控制台命令:
./redis-cli -p 26379
进入控制台以后,能运行哪些命令呢?可以使用sentinel help命令查看有哪些子命令
127.0.0.1:26379> sentinel help
1) SENTINEL <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) CKQUORUM <master-name>
3) Check if the current Sentinel configuration is able to reach the quorum
4) needed to failover a master and the majority needed to authorize the
5) failover.
6) CONFIG SET <param> <value>
7) Set a global Sentinel configuration parameter.
8) CONFIG GET <param>
9) Get global Sentinel configuration parameter.
10) GET-MASTER-ADDR-BY-NAME <master-name>
11) Return the ip and port number of the master with that name.
12) FAILOVER <master-name>
13) Manually failover a master node without asking for agreement from other
14) Sentinels
15) FLUSHCONFIG
16) Force Sentinel to rewrite its configuration on disk, including the current
17) Sentinel state.
18) INFO-CACHE <master-name>
19) Return last cached INFO output from masters and all its replicas.
20) IS-MASTER-DOWN-BY-ADDR <ip> <port> <current-epoch> <runid>
21) Check if the master specified by ip:port is down from current Sentinel's
22) point of view.
23) MASTER <master-name>
24) Show the state and info of the specified master.
25) MASTERS
26) Show a list of monitored masters and their state.
27) MONITOR <name> <ip> <port> <quorum>
28) Start monitoring a new master with the specified name, ip, port and quorum.
29) MYID
30) Return the ID of the Sentinel instance.
31) PENDING-SCRIPTS
32) Get pending scripts information.
33) REMOVE <master-name>
34) Remove master from Sentinel's monitor list.
35) REPLICAS <master-name>
36) Show a list of replicas for this master and their state.
37) RESET <pattern>
38) Reset masters for specific master name matching this pattern.
39) SENTINELS <master-name>
40) Show a list of Sentinel instances for this master and their state.
41) SET <master-name> <option> <value>
42) Set configuration paramters for certain masters.
43) SIMULATE-FAILURE (CRASH-AFTER-ELECTION|CRASH-AFTER-PROMOTION|HELP)
44) Simulate a Sentinel crash.
45) HELP
46) Prints this help.
sentinel masters
sentinel masters命令用于获取所有被监视主服务器的信息。从命令形式中就可以看出,实际上sentinel网络可以监控多个master实例,只需要在配置文件中配置好就可以。sentinel masters命令输出如下所示:
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
7) "runid"
8) "a63914648545d8922778cc3a6bfcc5eefc383260"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "730"
19) "last-ping-reply"
20) "730"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "6813"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "11141987"
29) "config-epoch"
30) "1"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
形成表格如下所示:
| 字段名 | 示例值 | 含义解释 |
|---|---|---|
name |
"mymaster" |
主服务器(master)的名称,由用户在 sentinel 配置中定义 |
ip |
"127.0.0.1" |
主服务器的 IP 地址。 |
port |
"6381" |
主服务器的端口号。 |
runid |
"a63914648545d..." |
主服务器的唯一运行 ID,用于标识实例 |
flags |
"master" |
当前角色标识,master 表示主节点;可能包含其他状态(如 s_down、o_down) |
link-pending-commands |
"0" |
sentinel向服务器发送了命令之后,仍在等待回复的命令数量,通常为 0 表示无阻塞。 |
link-refcount |
"1" |
当前连接到主服务器的引用计数(如 sentinel 或客户端连接数) |
last-ping-sent |
"0" |
距离 sentinel最后一次向服务器发送PING 命令之后消逝的毫秒数,0表示已发送 |
last-ok-ping-reply |
"730" |
服务器最后一次向sentinel 返回有效PING 命令回复之后消逝的毫秒数 |
last-ping-reply |
"730" |
服务器最后一次向 sentinel 返回 PING 命令回复之后消逝的毫秒数,一般与last-ok-ping-reply相同 |
down-after-milliseconds |
"30000" |
判定主节点不可用的超时时间(毫秒),超过此时间未响应则标记为主观下线(SDOWN) |
info-refresh |
"6813" |
上一次从主节点获取 INFO 信息的时间间隔(毫秒) |
role-reported |
"master" |
主节点自身报告的角色(应与 flags 一致) |
role-reported-time |
"11141987" |
上一次角色报告的时间戳(毫秒) |
config-epoch |
"1" |
配置版本号,用于故障转移时标识新主节点的唯一性 |
num-slaves |
"2" |
当前主节点的从服务器(slave)数量 |
num-other-sentinels |
"2" |
监控此主节点的其他 sentinel 实例数量(不包含当前 sentinel) |
quorum |
"2" |
达成客观下线(ODOWN)所需的最小 sentinel 同意数 |
failover-timeout |
"180000" |
故障转移超时时间(毫秒),超过此时间未完成则放弃本次故障转移 |
parallel-syncs |
"1" |
故障转移后,允许同时向新主节点同步数据的从节点数量 |
sentinel master
该命令的完整格式如下:
sentinel master <master-name>
这个命令只会返回用户指定主服务器的相关信息。比如:
sentinel master mymaster
查询的是mymaster主服务器的相关信息。返回数据格式和sentinel masters相同。
sentinel sentinels
该命令用于获取其他sentinel的相关信息,其完整命令格式如下所示:
sentinel sentinels <master-name>
命令输出如下所示:
127.0.0.1:26379> sentinel sentinels mymaster
1) 1) "name"
2) "928560c4df01bf5b19ad19751fbeae80db947c18"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "26380"
7) "runid"
8) "928560c4df01bf5b19ad19751fbeae80db947c18"
9) "flags"
10) "sentinel"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "813"
19) "last-ping-reply"
20) "813"
21) "down-after-milliseconds"
22) "30000"
23) "last-hello-message"
24) "145"
25) "voted-leader"
26) "?"
27) "voted-leader-epoch"
28) "1"
该输出和sentinel masters基本相同,有三项新增:
| 字段 | 解释 |
|---|---|
| last-hello-message | 距离当前 sentinel 最后一次从这个 sentinel那里收到问候信息之后,逝去的毫秒数 |
| voted-leader | sentinel网络当前票选出来的sentinel首领(leader),?表示目前无首领 |
| voted-leader-epoch | sentinel首领当前所处的配置纪元 |
sentinel get-master-addr-by-name
该命令可以通过给定主服务器的名字来获取该服务器的IP地址以及端口号:
sentinel get-master-addr-by-name <master-name>
比如想获取mymaster节点的ip地址和端口号:
127.0.0.1:26379> sentinel GET-MASTER-ADDR-BY-NAME mymaster
1) "127.0.0.1"
2) "6381"
sentinel reset
sentinel reset命令可以让sentinel忘掉主服务器之前的记录,并重新开始对主服务器进行监视,其完整格式如下所示:
sentinel reset <pattern>
pattern可以使用通配符一次选定多个被监视的master节点。
sentinel reset命令我觉得是个最有用的命令了,sentinel会将运行中的数据实时写入sentinel.conf文件中,下次重启的时候会利用这些数据恢复上次运行时的状态,要命的是这时候往往很多节点的状态已经发生了变化,最主要的是有可能部分节点已经下线或者id已经发生了变化,这时候运行该命令可以让sentinel删除所有数据,重新开始对主服务器监视,相当于“关机重启”了。
运行该命令:
127.0.0.1:26379> sentinel reset mymaster
(integer) 1
sentinel日志:

运行了sentinel reset命令的哨兵节点会重新建立和其他哨兵的联系,并重新监视主节点,添加从节点。
sentinel failover
sentinel failover的作用是使用当前哨兵节点强制执行故障转移,其完整命令为:
sentinel failover <master-name>
一般来说,sentinel网络需要主节点故障之后触发故障转移流程,哨兵节点还需要先投票选举leader最后才能执行故障转移。使用sentinel failover命令则不需要主节点发生故障,也不需要选举,它将指定当前哨兵节点强制执行故障转移。
比如我们想使用sentinel1对mymaster实行强制故障转移,可以使用命令:
sentinel failover mymaster
sentinel1的日志:
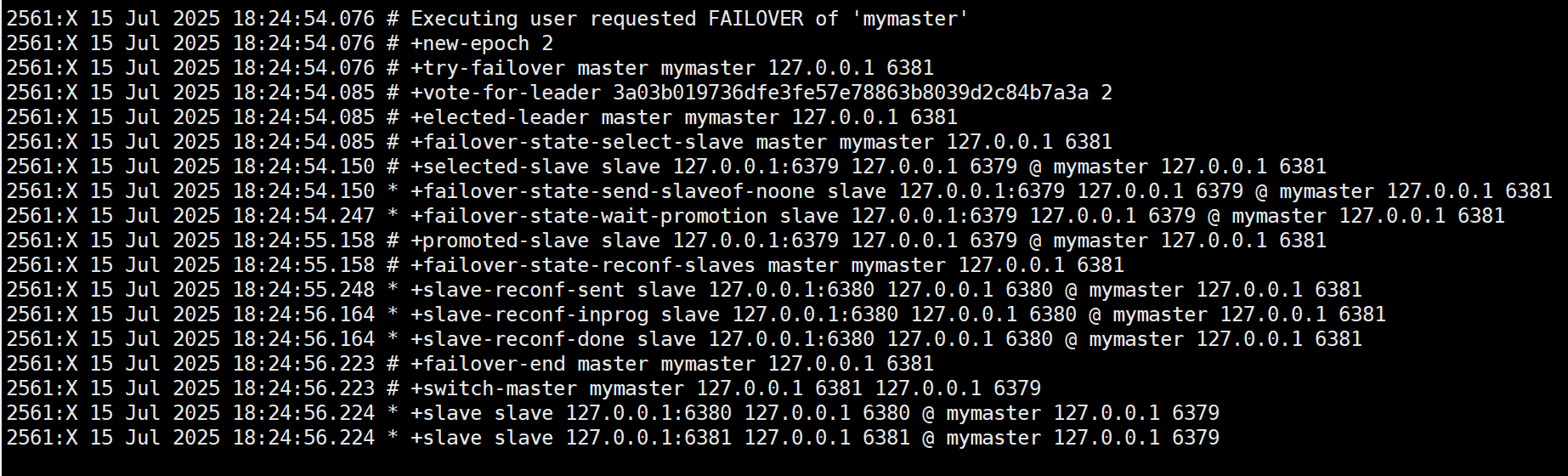
可以看到,开启了新纪元2,并且6379服务重新变成了主节点。
sentinel ckquorum
sentinel ckquorum命令用于检查sentinel网络当前可用的sentinel数量是否达到了判断主服务器客观下线并实施故障转移所需的数量:
sentinel ckquorum <master-name>
举例:
127.0.0.1:26379> sentinel ckquorum mymaster
OK 3 usable sentinels. Quorum and failover authorization can be reached
127.0.0.1:26379>
从结果可以看到,sentinel网络目前有3个sentinel可用,这已经满足了判断mymaster客观下线所需的sentinel数量。
sentinel ckquorum命令一般用于检查sentinel网络的部署是否成功。比如,如果我们在部署了3个sentinel之后,却发现sentinel ckquorum只能识别到2个可用的sentinel,那就说明有什么地方出错了。
sentinel flushconfig
sentinel flushconfig命令用于将配置文件重新写入硬盘。
因为sentinel在被监视服务器的状态发生变化时就会自动重写配置文件,所以这个命令的作用就是在配置文件基于某些原因或错误而丢失时,立即生成一个新的配置文件。此外,当sentinel的配置选项发生变化时,sentinel内部也会使用这个命令创建新的配置文件来替换原有的配置文件。
这个命令在误删除配置文件的时候非常有用。
sentinel monitor
该命令用于监视一个新的主服务器,完整命令如下:
sentinel monitor <master-name> <ip> <port> <quorum>
sentinel monitor命令本质上就是sentinel monitor配置选项的命令版本,当我们想要让sentinel监视一个新的主服务器,但是又不想重启sentinel并手动修改sentinel配置文件时就可以使用这个命令。
比如,我们想监控127.0.0.1:6379主服务器,而且达成客观下线所需的最小 sentinel 同意数为2,则可以运行如下命令:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel remove
该命令用于取消对指定主服务器的监控,完整命令如下所示:
sentinel remove <masters-name>
接收到这个命令的sentinel会停止对给定主服务器的监视,并删除sentinel内部以及sentinel配置文件中与给定主服务器有关的所有信息,然后返回OK表示操作执行成功。
举例:移除对mymaster主节点的监控
sentinel remove mymaster
sentinel set
该命令用于在线修改sentinel配置文件中与主服务器相关的配置选项值,完整命令如下:
sentinel set <master-name> <option> <value>
只要是sentinel配置文件中与主服务器有关的配置选项,都可以使用sentinel set命令在线进行配置。命令在成功修改给定的配置选项值之后将返回OK作为结果。
可以先使用sentinel masters命令查看有哪些参数以及值是多少,然后使用该命令修改指定的参数值。
比如,我要修改failover-timeout的值,可以这样做:
sentinel set mymaster failover-timeout 120000
注意该修改并不会传播给其它哨兵节点,也就是说每个哨兵节点都需要执行一次这个命令才能实现配置同步。
sentinel myid
该命令用于查询当前哨兵节点的id号码
127.0.0.1:26379> sentinel myid
"3a03b019736dfe3fe57e78863b8039d2c84b7a3a"
sentinel replicas
该命令用于展示被监控的主节点的所有副本信息,完整命令如下所示:
sentinel replicas <master-name>
举例:
127.0.0.1:26379> sentinel replicas mymaster
1) 1) "name"
2) "127.0.0.1:6381"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6381"
7) "runid"
8) "a63914648545d8922778cc3a6bfcc5eefc383260"
9) "flags"
10) "slave"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "501"
19) "last-ping-reply"
20) "501"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "502"
25) "role-reported"
26) "slave"
27) "role-reported-time"
28) "2029212"
29) "master-link-down-time"
30) "0"
31) "master-link-status"
32) "ok"
33) "master-host"
34) "127.0.0.1"
35) "master-port"
36) "6379"
37) "slave-priority"
38) "100"
39) "slave-repl-offset"
40) "5259427"
五、附录
哨兵故障转移日志详解
在上面的案例中,sentinel3完成了第一次故障转移:
让我们挨个分析每行日志:
故障检测阶段
-
+sdown master mymaster 127.0.0.1 6379:哨兵将主节点标记为主观下线(Subjectively Down),表示当前哨兵认为主节点不可用 -
+odown master mymaster 127.0.0.1 6379 #quorum 3/2:哨兵集群达成共识,将主节点标记为客观下线(Objectively Down),表示多个哨兵(3个中的2个)都认为主节点不可用
故障转移准备阶段
+new-epoch 1:开启新的配置纪元(epoch),这是一个递增的计数器,用于标识集群配置的版本+try-failover master mymaster 127.0.0.1 6379:开始尝试进行故障转移
领导者选举阶段
-
+vote-for-leader:哨兵节点开始投票选举领导者(leader)来执行故障转移操作 -
+elected-leader master mymaster 127.0.0.1 6379:成功选举出负责故障转移的哨兵领导者
从节点选择与提升阶段
+failover-state-select-slave:开始寻找合适的从节点进行提升+selected-slave slave 127.0.0.1:6381:选择了6381端口的从节点作为新的主节点+failover-state-send-slaveof-noone:向选中的从节点发送SLAVEOF NO ONE命令,使其成为主节点+failover-state-wait-promotion:等待从节点被提升为主节点+promoted-slave slave 127.0.0.1:6381:从节点6381成功被提升为新的主节点
重新配置从节点阶段
+failover-state-reconf-slaves:开始重新配置其他从节点+slave-reconf-sent:向其他从节点(6380)发送命令,使其复制新的主节点+slave-reconf-inprog:从节点正在重新配置+slave-reconf-done:从节点完成重新配置
故障转移完成阶段
-odown master mymaster 127.0.0.1 6379:清除主节点的客观下线状态+failover-end master mymaster 127.0.0.1 6379:故障转移顺利完成+switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381:更新主节点信息,从6379切换到6381
后续处理
+slave slave 127.0.0.1:6380:将6380节点添加为新主节点的从节点+slave slave 127.0.0.1:6379:原主节点6379恢复后,被添加为新主节点的从节点+sdown slave 127.0.0.1:6379:原主节点6379因为尚未完全恢复被标记为主观下线
注意:本文归作者所有,未经作者允许,不得转载